Si l’apprentissage automatique permet aux organisations d’être plus efficaces et de prendre les meilleures décisions, encore faut-il que les experts en data science maîtrisent les différents algorithmes d’intelligence artificielle. Car il en existe plusieurs dizaines. Et chacun répond à un objectif particulier. Dans cet article, nous allons justement étudier les différents algorithmes de classification.
Qu’est-ce qu’un algorithme de classification ?
Définition
Avant toute chose, il convient de voir ce qu’est un algorithme : un ensemble d’opérations suivies dans un ordre précis afin de résoudre un problème ou d’apporter de nouvelles solutions. Comme l’apprentissage par un système d’intelligence artificielle.
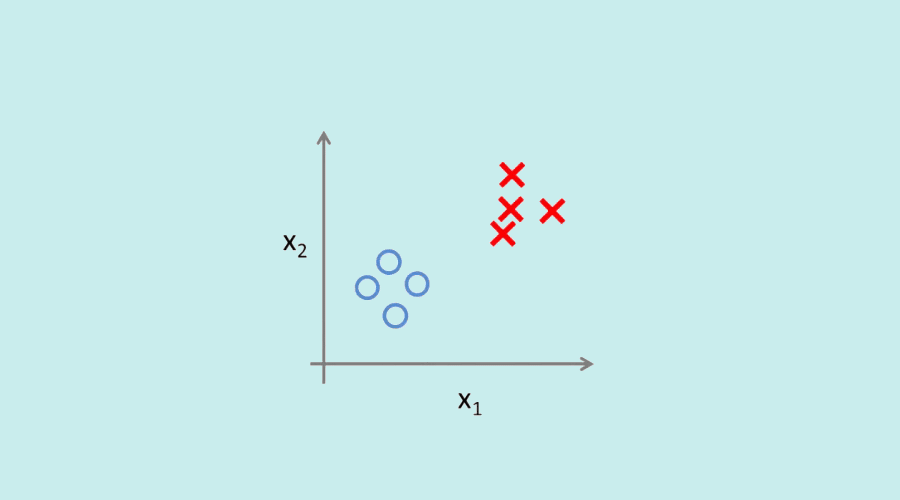
C’est justement le rôle des algorithmes de classification utilisés en machine learning. Ils permettent au logiciel d’apprendre en toute autonomie à partir de plusieurs ensembles de données.
L’idée est alors de classifier les différents éléments d’un jeu de données en plusieurs catégories. Ces dernières regroupent les datas en fonction de leur similarité. Comme les datas présentent des caractéristiques communes, il est plus facile de prédire leur comportement.
Par exemple, pour une boutique e-commerce, les internautes qui reviennent plusieurs fois sur le site sont plus susceptibles d’acheter que ceux qui ne le consultent plus jamais. L’algorithme de classification segmente ainsi les utilisateurs en différentes catégories afin de permettre à l’entreprise d’adapter sa communication.
Ces différents modèles d’apprentissage peuvent donc être utilisés pour l’analyse des données et pour l’analyse prédictive.
Une classification supervisée
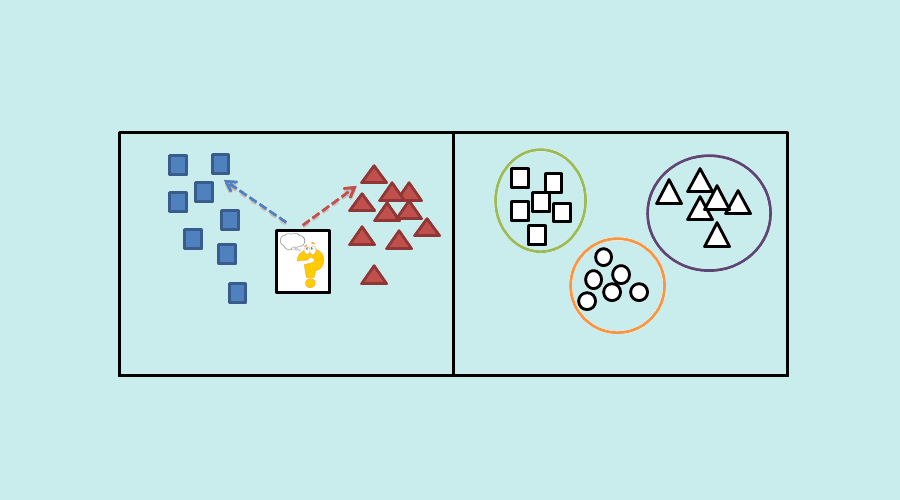
L’algorithme de classification fait partie des méthodes d’apprentissage supervisé. C’est-à-dire que les prédictions sont réalisées à partir de données historiques.
À l’inverse de l’apprentissage non supervisé où il n’y a pas de classes prédéfinies. Il faut donc constituer les catégories en fonction des attributs communs, pour ensuite réaliser la prédiction.
Au sein même de ces algorithmes supervisés, on oppose les algorithmes d’apprentissage par classification et par prédiction (ou de régression). Dans ce dernier cas, il s’agit de prédire de nouvelles données en fonction d’une valeur réelle spécifique, et non plus d’une catégorie.
Quels sont les principaux modèles de classification ?
La machine à vecteurs de support (SVM)
Cet algorithme est considéré comme un classificateur linéaire. Son rôle est de séparer les jeux de données à travers des lignes (appelés hyperplans). Pour cela, l’algorithme doit maximiser les distances entre la ligne séparatrice et les différents échantillons situés de part et d’autre. Les plus proches de la ligne sont appelés les vecteurs supports.
L’idée est donc de trouver l’hyperplan optimal ; celui qui distingue parfaitement les deux classes afin de minimiser les erreurs de classification. Cela permet de séparer clairement les données pour identifier facilement des classes simples. Par exemple, des grandes et des petites villes. Lorsqu’il s’agit de données plus complexes, comme le matériel génétique d’un individu, il n’est pas si simple d’identifier les différentes catégories. Cet algorithme ne sera donc pas le plus pertinent.
Bien souvent, on retrouve SVM dans le secteur de la finance, pour comparer les performances actuelles et futures, les retours sur investissement, etc.
Bon à savoir : Si cet algorithme est principalement utilisé pour la classification des données, il peut aussi être utilisé en matière de régression.
Les arbres de décision
L’arbre de décision est un algorithme classant les différentes données sous forme de branche. Il part d’une racine où chaque data prend une certaine direction en fonction de son comportement. Ce qui permet ensuite de prédire les variables de réponse.
Comme pour les arbres, les intersections sont appelées les nœuds, et leurs finalités, les feuilles. Les nœuds représentent alors les règles permettant de séparer les datas en différentes catégories, et les feuilles sont les informations elles-mêmes.
Voici un exemple très simple :
| Plus de 100 000 d’habitant | Ville en Ile-de-France | |
|---|---|---|
| Paris | Oui | Oui |
| Courbevoie | Non | Oui |
| Marseille | Oui | Non |
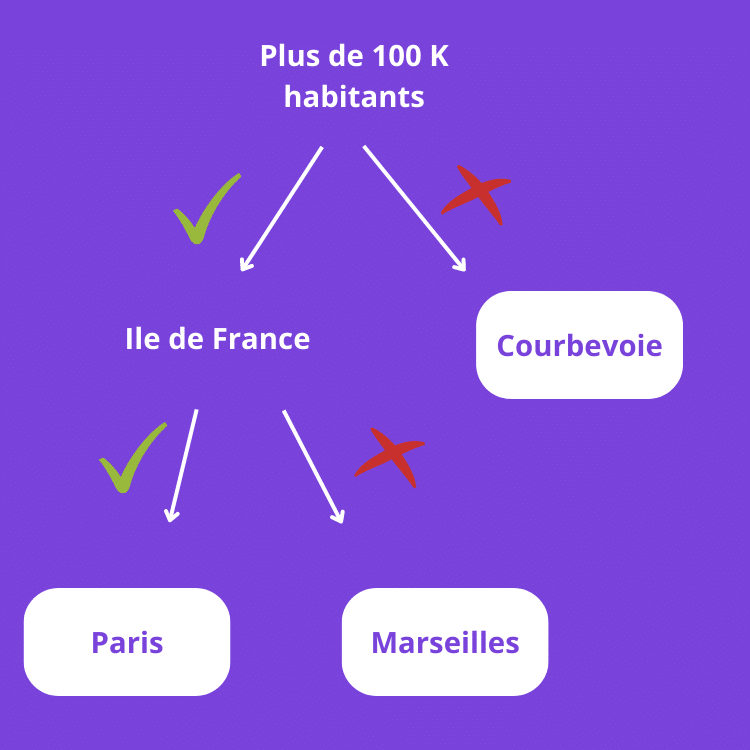
Cet algorithme de classification est très facile à comprendre, même par les non experts de la data. Cela dit, lorsqu’il représente de gros volumes de données, il devient plus difficile à appréhender.
On le retrouve pour l’anticipation de la variation du taux d’emprunt, de la réaction du marché en cas de changement, etc.
La répartition en K-moyennes (K-means)
Cet algorithme de classification trie les données en différents groupes en fonction de leurs caractéristiques.
Pour cela, il établit une moyenne de référence parmi un jeu de données, ce qui permet alors de définir un profil type.
L’avantage de l’algorithme K-means est sa précision. Et ce, même en traitant de grand volume de données rapidement.
De par son efficacité, le K-means, rencontre une multitude d’applications : les moteurs de recherche pour proposer des résultats pertinents au regard des attentes des utilisateurs, les entreprises pour anticiper le comportement des prospects ou internautes, les responsables informatiques pour analyser la performance des systèmes et réseaux, etc.
Le classificateur bayésien naïf
Cet algorithme reprend le théorème de Bayes et les probabilités conditionnelles.
Il repose sur les jeux de données étiquetés, et les associe à d’autres données non étiquetées pour les classifier.
Le classificateur bayésien naïf est principalement utilisé dans le traitement du langage naturel. Autrement dit, c’est ce qui permet aux machines de comprendre plus facilement le langage humain.
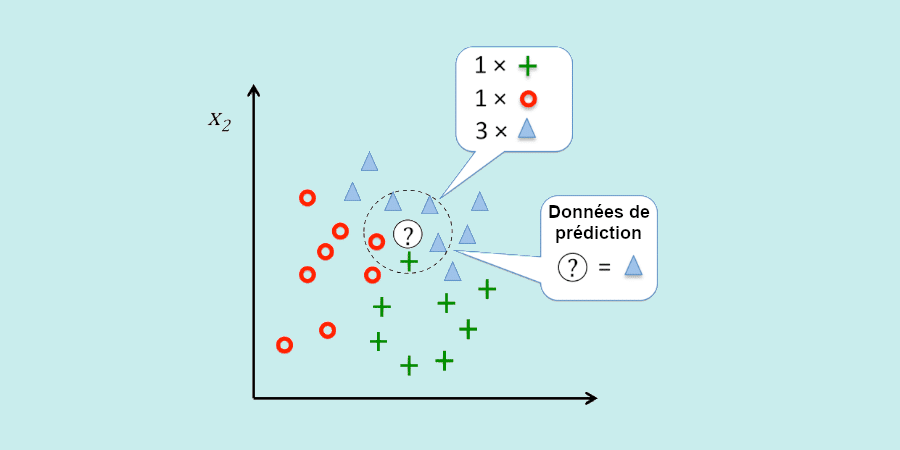
Le KNN (K-nearest neighbors)
Le K-nearest neighbors (ou algorithmes des plus proches voisins) peut être utilisé à la fois comme algorithme de régression ou de classification. Mais c’est souvent dans cette deuxième hypothèse qu’il est utilisé.
L’idée est alors de classifier les variables d’un jeu de données en analysant les similitudes entre elles. Pour cela, le KNN utilise un graphique et calcule la distance entre les différents points. Ceux qui sont les plus proches sont enregistrés dans la même catégorie.
La régression linéaire
C’est l’un des algorithmes de classification les plus utilisés. L’idée est d’effectuer des corrélations simples entre les entrées et les sorties. Cela permet ainsi d’expliquer comment le changement d’une variable peut affecter l’autre.
C’est la simplicité de ce modèle qui en fait son succès auprès des data scientists. Et pour cause, il ne nécessite que peu de paramètres, est facile à représenter sur un graphique et à expliquer auprès des décideurs.
À ce titre, il est souvent utilisé dans le domaine commercial pour prévoir le nombre de ventes, ou plus globalement pour anticiper les risques.
Bon à savoir : À l’inverse, de la régression logistique qui prédit la catégorie de la variable dépendante en fonction de la variable indépendante, la régression linéaire traite des variables indépendantes.
Perceptron
C’est l’un des algorithmes les plus simples, et surtout l’un des plus anciens, puisqu’il a été inventé en 1957 par Frank Rosenblatt.
Plus précisément, il s’agit d’un algorithme de classification binaire. Il va alors comparer la somme de plusieurs signaux d’entrée. Si le montant dépasse un certain seuil ou non, Perceptron conclut à un résultat en fonction de la règle définie en amont. Cette règle est appelée Perceptron Learning Rule qui permet au réseau neuronal d’apprendre de manière automatique.
Cet algorithme se révèle très utile pour détecter des tendances issues des données d’entrées.
Au-delà de ces différents algorithmes de classification, il en existe encore d’autres qui vous permettent de classer les datas.
Comment connaître les algorithmes de machine learning ?
Indispensable au machine learning, les algorithmes de classification sont des outils maîtrisés par les data scientists et data analysts. Pour les comprendre, il convient toutefois de suivre une formation spécialisée en data. C’est justement le cas de nos formations chez DataScientest.







