Les nombreux progrès en NLP permettent à ce jour de l’appliquer à de nombreuses tâches : traduction, génération de texte, résumé… Dans cet article, nous allons aborder un aspect simple du résumé : le résumé extractif. Il ne s’agit pas d’un résumé de synthèse mais plutôt d’une extraction des phrases les plus intéressantes, porteuses de sens.
Nous allons pour cela introduire la notion de TF-IDF qui est au cœur de l’algorithme pour résumer, puis nous allons ensuite étudier pas à pas les étapes qui permettent de résumer.
Qu’est ce TF-IDF ? Définition
Term Frequency – Inverse Document Frequency est une mesure qui permet, à partir d’un ensemble de textes, de connaître l’importance relative de chaque mot.
La mauvaise idée serait de penser que plus un mot est fréquent et plus il est important dans une phrase.
Or, avec cela, on se retrouverait très vite avec des mots clés tels que « le », « du », « a »… qui sont tout sauf utiles ! TF-IDF permet de rectifier cela.
A partir de maintenant, imaginez que nous avons un ensemble de textes (par exemple l’ensemble des œuvres de Molière). Et nous voulons extraire les mots les plus importants de ses œuvres.
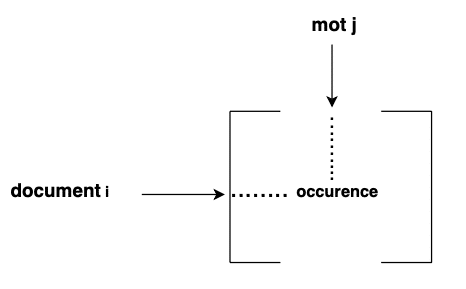
TF permet de mesurer l’importance relative d’un mot dans un document, par exemple, quelle est l’importance de pingre dans l’avare. Elle est définie par la formule
où {i le mot et j le documentLj le nombre total de mot dans le texte jFreqi,jla fréquence du mot i dans le doc j
i le mot et j le document Lj le nombre total de mot dans le texte j Freqi,j la fréquence du mot .
IDF mesure la signification d’un terme non pas en fonction de sa fréquence dans un document particulier, mais en fonction de sa distribution et de son utilisation dans l’ensemble des documents. Plus un terme a de potentiel, plus l’Inverse Document Frequency est élevée.
Idéalement, un terme apparaît très fréquemment dans quelques textes seulement. Les mots qui apparaissent dans presque tous les documents ou très rarement n’ont que peu d’importance. On obtient le score par la formule suivante :
où {ND le nombre total de documents dans le corpus fi nombre de documents où le mot i apparaît
On prend le logarithme car pour un gros corpus, la valeur de ce terme peut exploser.
Une fois les deux termes calculés, on calcule sa valeur par :
Nettoyer, nettoyer…
Le plus laborieux et chronophage en NLP est le preprocessing – la tâche qui consiste à travailler notre dataset pour qu’il puisse être exploité efficacement. Il faut penser à harmoniser le texte au maximum pour faciliter la tâche de l’algorithme. Les étapes les plus importantes pour notre étude de cas sont :
Remplacer les caractères spéciaux par des espaces
Remplacer des espaces supplémentaires en un espace classique
Le calcul dans l’idée est simple, mais il faut prêter attention au code. Il faut commencer par créer un vocabulaire de tout notre corpus. Ensuite, il faut créer ce qu’on appelle une count matrix qui pour chaque document compte l’occurrence de chaque mot.
Count Matrix
Une fois cette matrice créée, on peut calculer le score TF-IDF de cette matrice.
On finit par construire un dictionnaire qui associe la valeur TF-IDF à chaque mot.
Le résumé
On va calculer le score de chaque phrase des documents basé sur la valeur TF-IDF de chaque mot qui la compose.
Une fois le score de chaque phrase obtenue, on peut faire un résumé d’un texte.
Voici un exemple de résultat sur un texte :
Le résumé est déjà de qualité convenable. Comme on peut le voir, il nous a fallu quelques fonctions et ne pas se perdre dans le code pour calculer le score de chaque mot. Tout est question d’organisation. Cependant, cela reste un résumé assez classique. Des nouvelles méthodes comme les Transformers, ou des méthodes plus classiques comme les n-gram, permettent de réaliser de vrais résumés.
Cependant, cela devient plus compliqué et nécessite un réel background en terme de connaissances et d’applications. Notre formation s’est d’ailleurs dotée, récemment, de cours sur ces nouvelles méthodes, pour permettre de à ses utilisateurs de réaliser des projets avec une plus grande ambition!