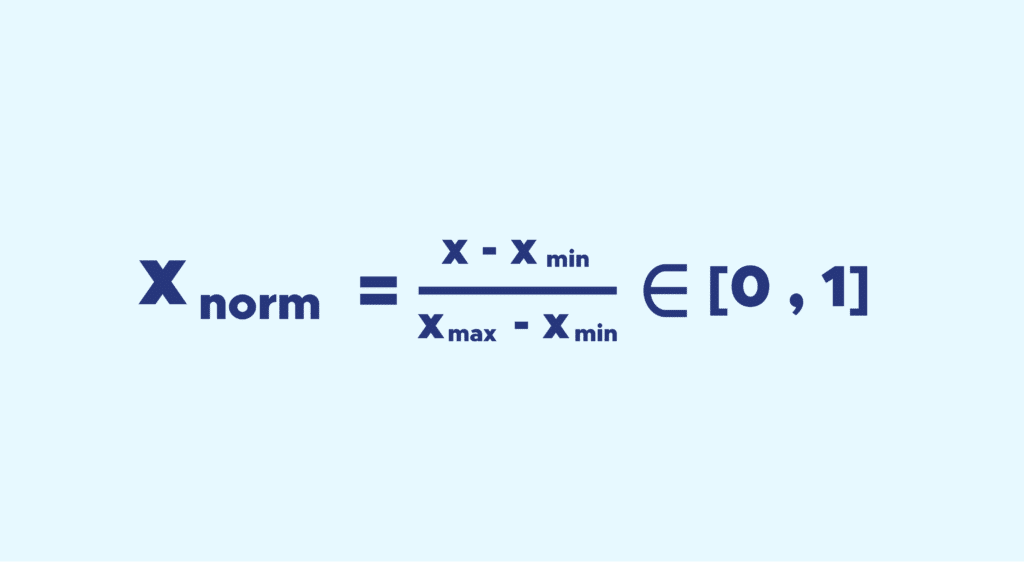
Daniel es el soporte técnico de los cursos de DataScientest. Es el experto en todos los temas de Data Science y acompaña a los alumnos durante su formación. Hoy, logramos quitarle unos minutos de su precioso tiempo para que pueda responder nuestras preguntas sobre la estandarización de datos.

Yo : Hola, Daniel, sé que te han debido de hacer esta pregunta muchas veces, pero veo que se habla constantemente de la estandarización de datos, ¿puedes ayudarme a entender el concepto en pocas palabras?
Y matemáticamente ¿cómo es?
Si cogemos una variable numérica con n observaciones que se puede escribir :

Como tenemos un número finito de valores reales, podemos extraer varias informaciones estadísticas como el mínimo, el máximo, la media y la desviación tipo.
El proceso de normalización solo necesita el mínimo y el máximo.
La idea es la siguiente, llevamos todos los valores de la variable entre 0 y 1, y mantenemos las distancias entre los valores.
Se hace muy fácil, hay que aplicar la siguiente fórmula :
Daniel : Pues efectivamente, la estandarización, tal como la entendemos en el sector, es un concepto clave en el preprocesamiento de datos cuando tenemos que trabajar en un proyecto de Machine Learning.
En realidad, cuando hablamos de estandarización, hay dos procesos principales implícitos: la normalización y la normalización estándar, más comúnmente conocida como estandarización. Por lo general, estos dos procesos tienen la misma finalidad: redimensionar las variables numéricas para que sean comparables en una escala común.

En cuanto a la estandarización, la transformación es más sutil que llevar el conjunto de valores entre 0 y 1. Su finalidad es llevar la media μ a 0 y la desviación estándar σ a 1.Una vez más, el proceso no es nada complicamos si tenemos disponible la media μ y la desviación estándar σ de una variable determinada X = x1 x2 xn entonces la variable estandarizada se escribirá:

Todo esto es genial, pero en el sector de los data, ¿para qué sirve?
Trabajar con datos de escala variable puede suponer un problema para su análisis, ya que una variable numérica con un rango de valores incluido entre 0 y 10 000 será más pesada en el análisis que una variable cuyos valores estén entre 0 y 1, lo que causaría en consecuencia un problema de sesgoSin embargo, hay que tener cuidado de no considerar la estandarización como un paso obligatorio en el procesamiento de nuestros datos, ¡constituye una pérdida inmediata de información y puede ser perjudicial en ciertos casos!
Ahora lo entiendo mejor, pero hay una pregunta que sigue sin respuesta, ¿cómo se estandarizan concretamente los datos?
En Python es muy sencillo, muchas bibliotecas lo permiten. Solo mencionaré Scikit-learn porque es la más utilizada en Data Science. Esta biblioteca proporciona funciones que realizan las normalizaciones deseadas en unas pocas líneas de código muy simples.
Sin embargo, es importante poner los casos de uso en contexto, porque en la práctica no basta con aplicar una normalización sin más a todos los datos que nos llegan cuando ya hemos normalizado nuestros datos de entrenamiento.
¿Por qué? Por la sencilla razón de que no es posible aplicar esta misma transformación a una muestra de prueba o a nuevos datos.
Por supuesto, es posible centrar y reducir cualquier muestra de la misma manera, pero con una media y una desviación tipo que serán diferentes a las usadas en el conjunto de entrenamiento.
Los resultados obtenidos no serían una representación justa del rendimiento del modelo en su conjunto, ya que se aplica a datos nuevos.
Entonces, en vez de aplicar directamente la función de normalización, es mejor usar una función de Scikit-Learn llamada Transformer API, que permite ajustar (fit) un paso de preprocesamiento utilizando los datos de entrenamiento.
De ese modo, cuando la normalización, por ejemplo, se aplica a otras muestras, utilizará las mismas medias y desviaciones tipo ya guardadas.
Para crear ese paso de preprocesamiento “ajustado”, basta con usar la función StandardScaler y luego ajustarla usando los datos de entrenamiento. Finalmente, para aplicarlo a una tabla de datos después, solo habrá que aplicarle scaler.transform().
Sería igual para una normalización MinMax :
Si queremos formarnos en Data Science con tus consejos, ¿cómo lo hacemos?
Es muy fácil, solo tienes que empezar uno de nuestros cursos en Data Science 🙂. Si quieres descubrir la contribución de Daniel a lo largo de uno de nuestros cursos, descubre la entrevista a dos de nuestros antiguos alumnos:
