
Entre todos los ataques informáticos que existen contra los sistemas, el Data Poisoning se caracteriza por la falsificación de datos de entrenamiento de modelos de Machine Learning. ¿Qué significa esto? ¿Representa esto un verdadero peligro? Aquí encontrarás una breve explicación de este ataque tan particular, de las amenazas que implica y los medios para defenderse.
¿Qué es el Data Poisoning?
Los ataques de Data Poisoning aparecen con la llegada masiva de los modelos de Machine Learning al final del siglo XX.
Estos ataques intervienen en la fase de entrenamiento de los modelos de Machine Learning. Un modelo debe ser efectivamente entrenado con datos para funcionar. Progresivamente, el modelo de Machine Learning va aprendiendo de sus errores y realiza su tarea cada vez mejor.
Un modelo predictivo, es un programa que es capaz de realizar una tarea particular.
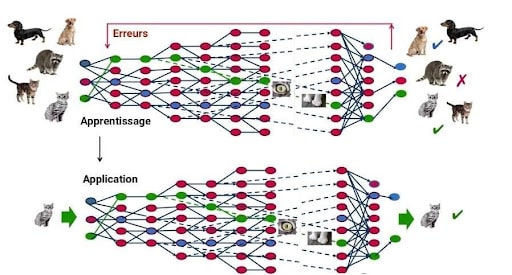
Como el ataque de Data Poisoning se realiza en fase de entrenamiento, altera e invalida completamente los resultados del modelo predictivo. Los ataques dirigidos contra el modelo Antispam de Google entre 2017 y 2018 son un ejemplo de cómo funcionan estos ataques. El modelo antispam de Google es entrenado con datos llamados pares de input/etiquetas.
El input es un mail o un mensaje de texto y la etiqueta indica si el mensaje es spam o no.
Es aquí donde el Data Poisoning interviene. Este corrompe y falsifica masivamente los datos de entrenamiento indicando por ejemplo como spam algo que no lo es. Estos ataques alteran la precisión del modelo de Machine Learning. En el caso de Google, los spammers pueden enviar spams sin que el modelo antispam de Google los detecte. Los ataques de Data Poisoning también se dirigen a modelos de reconocimiento de carteles de tráfico, utilizados por los vehículos autónomos por ejemplo. Si este modelo es envenenado, podría causar que se confunda un cartel de alto con uno de límite de velocidad.

¿Cuáles son los peligros del Data Poisoning?
El hecho de que un ataque de Data Poisoning se haya vuelto accesible, lo vuelve un verdadero peligro. Una vez que la fase de entrenamiento de un modelo de Machine Learning ha terminado, es muy difícil corregir el modelo. Se necesitaría un análisis exhaustivo de todos los inputs que hayan entrenado el modelo, detectar los fraudulentos y eliminarlos. Pero si el conjunto de datos es demasiado grande, este análisis es simplemente imposible. La única solución es entrenar nuevamente el modelo.
Las fases de entrenamiento son extremadamente costosas: en el caso del sistema de inteligencia artificial GPT-3 desarrollado por Open IA, la fase de entrenamiento costó alrededor de 16 millones de euros.
Más allá de un simple costo económico, el Data Poisoning puede representar un peligro aún más grande. La inteligencia artificial y los modelos de machine learning ocupan un lugar cada vez más importante en nuestras vidas y en nuestra sociedad y son utilizados para las tareas más importantes, como la salud, el transporte, las investigaciones criminales, etc. Por ejemplo, la policía de Chicago utiliza la IA para luchar contra el crimen, para prevenir cuándo y dónde sucederán los crímenes. ¿Qué pasaría si sus modelos de Machine Learning estuvieran envenenados? La lucha contra el crimen sería ineficaz y los modelos dirigirán a los policías tras pistas falsas.
¿Cómo protegerse del Data Poisoning?
Por suerte, existen medios para luchar contra el Data Poisoning.
- La primera técnica consiste en controlar las bases de datos antes de inyectar en los datos de entrenamiento de un modelo. Para ello se pueden utilizar métodos estadísticos para detectar las anomalías en los datos, tests de regresión e incluso la moderación manual.
- También se puede monitorear cualquier cambio en el desempeño del modelo durante la fase de entrenamiento para reaccionar lo antes posible, gracias a herramientas de control como Azure Monitor o Amazon SageMaker.
- Por último, como el envenenamiento de los datos supone conocer previamente el modelo, se deben guardar las informaciones de su funcionamiento en secreto durante la fase de entrenamiento.
El Data Poisoning representa una verdadera amenaza informática, y aún más porque estos ataques son cada vez más accesibles para los hackers. Pero frente al progreso de las técnicas de los hackers el desafío es hacer progresar también los sistemas de prevención. Los Data Scientists y los Data Engineers están en primera línea para combatir estos ataques. Son ellos quienes deben recolectar datos seguros o detectar ataques durante las fases de entrenamiento.
Si quieres saber más sobre el funcionamiento y la protección de estos modelos, ve a echar un vistazo a nuestras formaciones en las profesiones de la data.
