
La matriz de confusión es una joya tecnológica en materia de Inteligencia Artificial. ¿Quieres saber cómo aprovechar el rendimiento de la matriz de confusión? Te explicamos de forma clara y concreta su modo de funcionamiento.
Para analizar y comparar fácilmente cualquier tipo de datos, es imprescindible disponer de herramientas potentes. A partir de este punto, entra en acción la matriz de confusión que se revela muy eficaz. Concretamente, el uso de la matriz de confusión puede resolver los problemas de clasificación estadística sobre un concepto de aprendizaje automático (The Machine Learning). Te decimos todo lo que debes saber.
Matriz de confusión : ¿Qué es?
La matriz de confusión, también conocida como matriz de error, es un instrumento tecnológico que sirve para calcular el rendimiento sobre un modelo de clasificación definido. De este modo, es posible predecir fácilmente por ejemplo los correos electrónicos que deben ser clasificados como spam. Es más, esta herramienta es una tabla de predicciones dotada de Inteligencia Artificial (IA) que visualiza el desempeño de un algoritmo.
En cuanto al rendimiento de la matriz de confusión (Confusion Matrix), se encuentra en su capacidad de clasificar predicciones. Visto así, su modo de funcionamiento puede parecer algo complejo. En realidad, con la ayuda de un aprendizaje supervisado, está a tu alcance sacar provecho de la matriz de confusión y sus métricas.
¿Cómo se interpreta una matriz de confusión?
Sobre la base de un modelo específico que define tu búsqueda, puedes comparar una serie de predicciones con valores reales. Al proceder de este modo, puedes tener la seguridad de que tu modelo funciona.
Para calcular tus datos con la matriz de confusión (Confusion Matrix), debes disponer de datos de prueba y valores de resultados obtenidos. En breve, el inicio de una predicción constituye la base de los valores en la matriz de confusión.
Ejemplo concreto : estructura general de la matriz de confusión
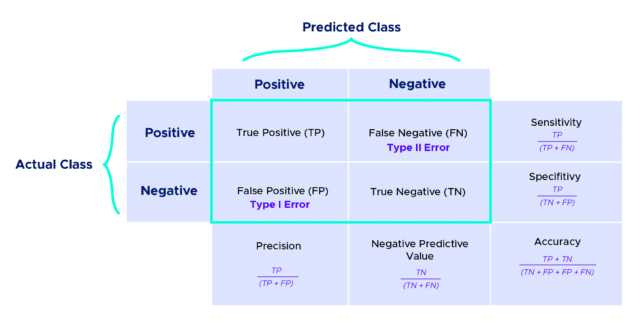
En segundo lugar, aquí viene un ejemplo concreto de la estructura general de matriz de confusión (2 x 2). Para darte una idea, supongamos que el objetivo es calcular precisamente los falsos casos negativos de los verdaderos negativos. Nuestro ejemplo de matriz de confusión se divide en 4 clases que se descomponen de la forma siguiente :
 |
Positivo | Negativo | |
| Positivo | Verdadero positivo | Falso positivo | |
| Negativo | Falso negativo | Verdadero negativo | |
¿ Cómo funciona el algoritmo de clasificación ?
¿Quieres familiarizarte con el algoritmo de clasificación de una matriz de error? Es necesario saber cómo funciona el algoritmo de clasificación y analizar antes de todo sus componentes. En primer lugar, ten en cuenta que los 2 valores principales son el Negativo (N) y el Positivo (P).
Estos 2 valores están extraídos de la matriz de confusión. Los valores predichos de la variable objetivo son representados por las filas. En cuanto a los valores reales (positivo o negativo) de la variable objetivo, están representados por las columnas.
- Verdadero Positivo : este modelo expresa una exactitud positiva perfecta. La matriz de confusión indica que el valor predicho concuerda con el valor real. Después del aprendizaje automático, se determina con precisión que el modelo predice un valor positivo. La clase del valor real es igualmente positiva.
- Verdadero Negativo : la predicción demuestra también que el valor predicho coincide con el valor real. En todo caso, la clasificación es negativa.
- Falso Positivo : el resultado expresa que el modelo predicho es incorrectamente positivo. Es decir, aunque el modelo predice un valor positivo, la clase es, en realidad, negativa. El falso positivo se conoce como error de tipo número 1.
- Falso Negativo : el resultado de la predicción del modelo está incorrectamente incluido en la clase de los negativos. El valor real es positivo. De hecho, se trata también de un error que se clasifica en categoría de tipo número 2.
Sabiendo cómo asimilar la parte analítica de la matriz de confusión, puedes calcular tus datos de forma exacta a partir de un conjunto de datos. Según el nivel de complejidad y el volumen (Big Data…) de los datos introducidos, puedes obtener resultados pertinentes. De manera general, es necesario que recuerdes lo siguiente sobre esta potente herramienta tecnológica :
- Falso Positivo (FP) : La predicción positiva es falsa.
- Falso Negativo (FN) : La predicción negativa es falsa.
- Verdadero Positivo (VP) : La predicción positiva es verdadera.
- Verdadero Negativo (VN) : La predicción negativa es verdadera.
¿ Para qué sirven las métricas ?
Todo lo visto nos lleva a pensar que la matriz de confusión puede calcular con eficacia y precisión cualquier tipo de datos. Está claro que la matriz de confusión forma parte de las herramientas fundamentales del científico de datos. En cuanto a las métricas de la matriz de confusión, sirven para evaluar con aún más exactitud su analítica de datos. Además, estas métricas se dividen en 4 categorías :
- Exactitud (Accuracy) : en comparación con todas las clases, la métrica «Exactitud» muestra cuántas se predijeron correctamente.
- Precisión : la métrica «Precisión» expresa cuántos de los resultados positivos que se han predicho son verdaderamente positivos.
- Medida F1 score : la métrica «F1 score» se revela muy útil para comparar un modelo de alta sensibilidad (recall) con otro modelo de baja precisión.
- Sensibilidad (Recall) : esta métrica indica con exactitud cuántas clases positivas se predijeron correctamente.
Ahora que sabes cómo aprovechar el rendimiento de la matriz de confusión y sus métricas, llega la etapa de poder ir más allá. ¿Quieres formar parte de los expertos en datos? Apostando por los cursos DataScientest, puedes lograr tus desafíos paso a paso. No te lo pierdas.
