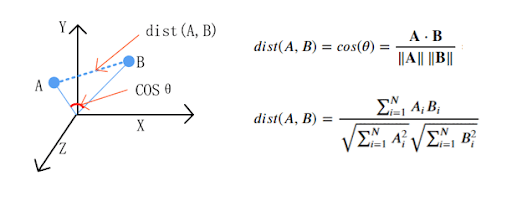El Word Embedding designa un conjunto de métodos de aprendizaje que pretende representar las palabras de un texto mediante vectores de números reales. Hoy vamos a presentarte la 3.ª parte de nuestro dosier NLP.
Esta sección pretende explicar cómo funciona el famoso algoritmo Word2vecen Python y su implementación.
Word Embedding
Como recordatorio, el Word Embedding es capaz de capturar el contexto, la similitud semántica y sintáctica (género, sinónimos, etc.) de una palabra reduciendo su dimensión.
Por ejemplo, cabría esperar que las palabras «notable» y «admirable» estuvieran representadas por vectores relativamente cercanos en el espacio vectorial donde se definen estos vectores.
El método de embedding que se usa habitualmente para reducir la dimensión de un vector consiste en utilizar el resultado que devuelve una capa densa, es decir, multiplicar una matriz de embedding W por la representación «one hot» de la palabra :
En forma vectorial :
Autocodificador
Embedding con la ayuda de Word2vec
Sin embargo, para evitar las limitaciones del primer método, es posible entrenar la matriz W de forma no supervisadasolo con texto utilizando el famoso algoritmo Word2Vec.
¿Cómo funciona word2vec?
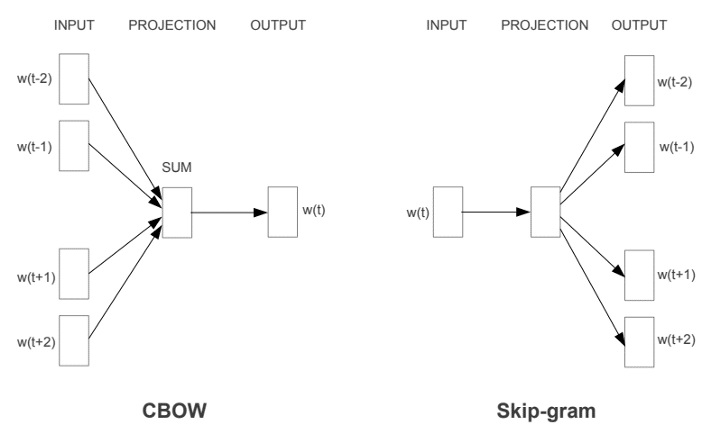
Existen dos variantes de Word2vec, ambas utilizan una red neuronal de 3 capas (1 capa de entrada, 1 capa oculta, 1 capa de salida): Common Bag Of Words (CBOW) y Skip-gram.
En la siguiente imagen, la palabra del recuadro azul se llama palabra objetivo y las palabras de los recuadros blancos se llaman palabras de contexto en una ventana de tamaño 5.
CBOW : El modelo se alimenta del contexto y predice la palabra objetivo. El resultado de la capa oculta es la nueva representación de la palabra (ℎ1, …, ℎ𝑁).
Skip Gram: El modelo se alimenta de la palabra objetivo y predice las palabras del contexto. El resultado de la capa oculta es la nueva representación de la palabra (ℎ1, …, ℎ𝑁).
Formateo de los datos :
Aquí presentaremos el modelo CBOW, es decir, el contexto es la entrada de nuestro modelo y la palabra objetivo (palabra azul) es la salida. Definimos una ventana de longitud 5 para el contexto (entrada).
Modelo :
El modelo CBOW tiene similitudes con el modelo de clasificación que acabamos de implementar en la sección anterior. Nuestro modelo estará compuesto por las siguientes capas :
Arquitectura CBOW
La capa Embedding transformará cada palabra del contexto en un vector de embedding. La matriz W de embedding se aprenderá a medida que se entrena el modelo. Las dimensiones resultantes son: (lot, context_size, embedding).
A continuación, la capa GlobalAveragePooling1D permite sumar los diferentes embbeding y obtener una dimensión de salida (batch_size, embedding).
Por último, la capa densa de tamaño «voc_size» permite predecir la palabra objetivo.
La función de pérdida cross-entropy se suele utilizar para entrenar al modelo :
Métrica en este espacio :
Ahora que el modelo está entrenado, puede ser interesante comparar la distancia entre las palabras.
La “Cosine similarity” se utiliza por lo general como métrica para medir la distancia cuando la norma de los vectores no tiene importancia. Esta métrica capta la similitud entre dos palabras.
Cuanto más se acerque la cosine similarity a 1, más relacionadas estarán las dos palabras.
Con esta métrica y en este subespacio vectorial, las 5 palabras más cercanas a «body» son :
intestines — 0.30548161268234253
bodies — 0.2691531181335449
arm — 0.24878980219364166
chest — 0.2261650413274765
leg — 0.2193179428577423
Los números anteriores representan las distancias de similitud coseno entre la palabra «body» y las palabras más cercanas.
Para la palabra « zombie » :
slasher — 0.3172745406627655
cannibal — 0.28496912121772766
zombies — 0.2767203450202942
horror — 0.2607246935367584
zombi — 0.25878411531448364
Para la palabra « amazing » :
brilliant — 0.3372475802898407
extraordinary — 0.319326251745224
great — 0.29579296708106995
breathtaking — 0.2907085716724396
fantastic — 0.2871546149253845
Para la palabra « god » :
heavens — 0.268303781747818
jesus — 0.26807624101638794
goodness — 0.2618488669395447
gods — 0.24795521795749664
doom — 0.22242328524589539
Propiedades aritméticas :
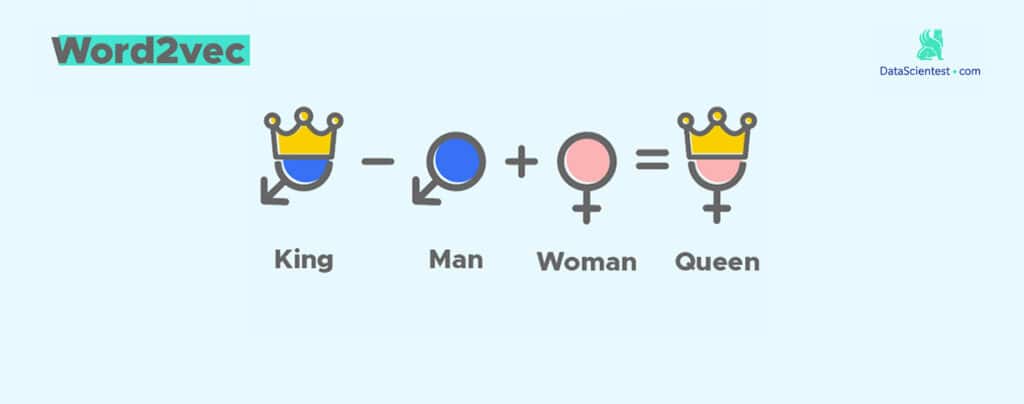
Ahora podemos preguntarnos si nuestro subespacio vectorial de palabras tiene propiedades aritméticas. Veamos el siguiente ejemplo famoso :
𝐾𝑖𝑛𝑔 − 𝑀𝑎𝑛 + 𝑊𝑜𝑚𝑎𝑛 = 𝑄𝑢𝑒𝑒𝑛
En este ejemplo la propiedad aritmética es la realeza. Queremos comprobar si esta propiedad se propagará a «woman». Es decir, buscaremos las palabras más cercanas al siguiente vector :
Aquí, la palabra «queen» no está muy representada en nuestra serie de datos, lo que explica la escasa representación. Por esta razón, nos centraremos en la propiedad numérica :
Men − 𝑀𝑎𝑛 + 𝑊𝑜𝑚𝑎𝑛 = Women
Utilizando la operación definida anteriormente y una métrica de similitud coseno, las 5 palabras más cercanas son :
women — 0.2889893054962158
females — 0.272260844707489
strangers — 0.24558939039707184
teens — 0.2443128377199173
daughters — 0.24117740988731384
El resultado para Zombies − Zombie + 𝑊𝑜𝑚𝑎𝑛 :
women — 0.2547883093357086
females — 0.23258551955223083
ladies — 0.22764989733695984
stripper — 0.22274985909461975
develops — 0.2202150821685791
El resultado para Men − Man + Soldier :
soldiers — 0.3547001779079437
daughters — 0.21896378695964813
letters — 0.21452251076698303
backyard — 0.21437858045101166
veterans — 0.21067838370800018
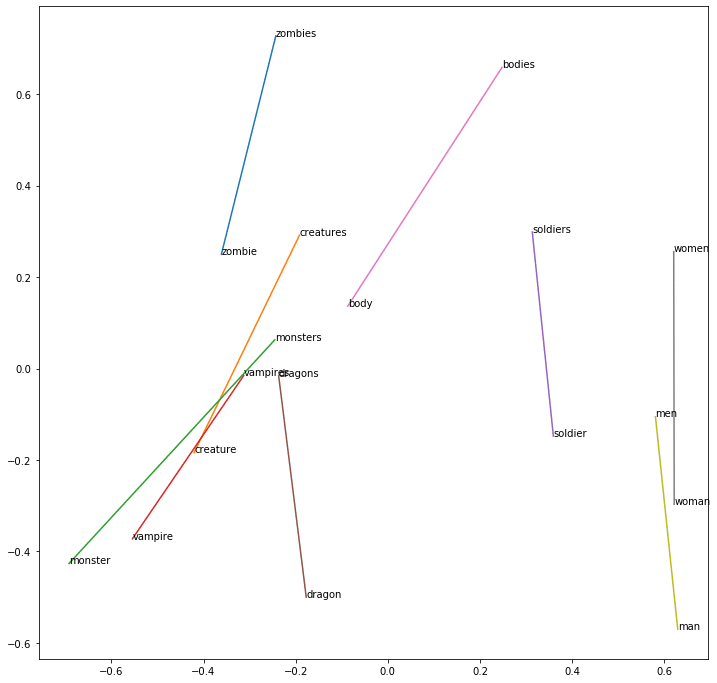
El resultado para Zombies − Zombie + monster :
werewolves — 0.2724993824958801
monsters — 0.25695472955703735
creature — 0.24453674256801605
dragons — 0.22363890707492828
bloke — 0.21858260035514832
Aquí la palabra «monsters» y «werewolves» parecen estar muy cerca en el contexto de nuestra serie de datos.
Utilizando un ACP, podemos encontrar la dimensión de la propiedad numérica :
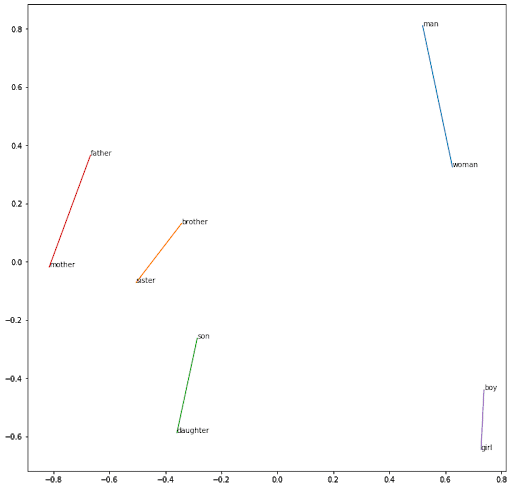
Utilizando el mismo razonamiento para captar el género :
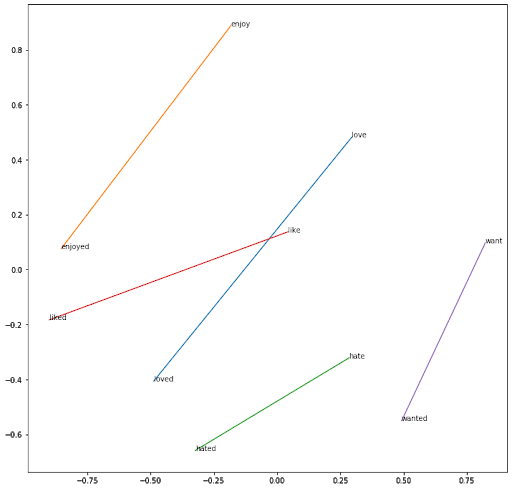
Utilizando el mismo razonamiento entre los verbos en infinitivo y los verbos terminados en -ed :
“Word2vec embedding” captura eficazmente las propiedades semánticas y aritméticas de una palabra. También permite reducir el tamaño del problema y, por tanto, la tarea de aprendizaje.
Podemos imaginarnos el uso del algoritmo word2vec para preentrenar la matriz de embedding del modelo de clasificación. Como resultado, nuestro modelo de clasificación tendrá una representación mucho mejor de las palabras en la fase de aprendizaje de los sentimientos.