
Google Colab es un servicio en línea de notebooks Jupyter que permite escribir y ejecutar código en Python desde tu navegador web. Gratuito y accesible con una cuenta de Google, Colab es ideal para el análisis de datos y la ciencia de datos con Python, con sus celdas de código y bloques de texto en sintaxis Markdown, para estructurar y comentar el código.
Un notebook creado en Colab se guarda en Google Drive. En la práctica, es un archivo .ipynb que, una vez descargado en el ordenador, puede abrirse y utilizarse localmente con Jupyter notebook. Por otro lado, un archivo .ipynb creado localmente con Jupyter notebook puede subirse a Google Drive para ser editado y ejecutado en Colab, accediendo a recursos informáticos, incluyendo GPU[1] y TPU[2]. Para trabajar en equipo a distancia, es posible compartir un notebook de Colab como se haría con un documento de Google Docs. Finalmente, este notebook puede acceder a los archivos almacenados en Google Drive, por ejemplo, si trabajas con conjuntos de datos en formato .csv.
¿Pero cómo proceder para compartir tanto los notebooks que contienen tu código como los archivos que contienen los datos? Ahí es donde las cosas se complican (un poco). ¡Y hay varias maneras de proceder!
Durante su formación en DataScientest, nuestros estudiantes realizan un proyecto final destinado a poner en práctica las competencias adquiridas a través de un caso implementado de la A a la Z. Este proyecto se realiza por equipos de 2, 3 o 4, con miembros que generalmente están dispersos geográficamente. Para implementar rápidamente y de manera efectiva este trabajo colaborativo a distancia, nuestro equipo pedagógico propone una masterclass que sienta las bases y aborda las diferentes soluciones posibles. Luego, cada equipo se beneficia de un seguimiento personalizado a través de reuniones regulares con su mentor.
En este artículo, volvemos a las claves para empezar bien con Google Colab en equipo. ¿Cuáles son los trucos y consejos de los mentores de DataScientest? ¿Hay puntos de atención a tener en cuenta? En menos de 7 minutos, tendrás una visión clara de los 3 escenarios recomendados para configurar todo.
Previamente, crea y comparte tu notebook
- Desde tu artículo de trabajo en Drive, haz clic en “+ Nuevo” > Más > Google Colaboratory (o “Asociar más aplicaciones” si no aparece en la lista) y luego “Crear”.

- O bien, desde la página https://colab.google, haz clic en “New Notebook” (el archivo se almacena por defecto en tu Drive en una subcarpeta “Colab Notebooks”).
- Cambia el nombre del archivo, titulado por defecto
Untitled0.ipynb. - Haz clic en el botón


y da acceso a tus compañeros con los derechos de editor.
⚠️ Advertencia: el notebook puede ser ejecutado por una sola persona a la vez.
Escenario 1 con BytesIO y 1 archivo
Lucas recomienda este método al inicio del proyecto. Con él, todo el equipo puede utilizar el mismo archivo fuente, que puede almacenarse en cualquier cuenta al hacerse público. Así, cada miembro del equipo puede ejecutar el notebook sin modificar la celda de código que carga el conjunto de datos.
import pandas as pd
from io import BytesIO
import requests
# Ceci est uniquement utilisé pour vous montrer où obtenir le file_id
original_link = "https://drive.google.com/file/d/1fRkXUdfLzTMkscHsAI8_NJuuDptwk02W/view?usp=drive_link"
# ID du fichier (à partir du lien partagé) (LE FICHIER DOIT ÊTRE PUBLIC)
file_id = "1fRkXUdfLzTMkscHsAI8_NJuuDptwk02W"
# Télécharger un fichier CSV depuis Google Drive
download_url = f"https://drive.google.com/uc?id={file_id}"
response = requests.get(download_url)
data = BytesIO(response.content)
# Charger le fichier CSV dans un DataFrame
df = pd.read_csv(data)
df.head()
🔗 Para saber más: consulta la documentación en https://docs.python.org/3/library/io.html.
Escenario 2 con gdown (Google Drive Public File Downloader) y 1 o varios archivos
Alia propone regularmente este enfoque a los estudiantes que mentora. La librería gdown está diseñada específicamente para importar archivos desde Google Drive. De nuevo, con este método, el archivo fuente almacenado en Drive debe hacerse público. Truco: el parámetro “quiet = True” suprime la salida de progreso durante la descarga, haciéndola menos verbosa.
# import de packages
import subprocess
import sys
import pandas as pd
# Ce code permet de s'assurer que gdown est bien installé.
# Si ce n'est pas le cas, il l'installe automatiquement.
# Cela évite des erreurs au moment de l'utiliser, surtout sur Colab où certaines bibliothèques ne sont pas déjà présentes.
try:
import gdown
except ImportError:
# Si gdown n'est pas installé, l'importer en utilisant pip
subprocess.check_call([sys.executable, "-m", "pip", "install", "gdown"])
# Remplacez l'ID par le vôtre (tout ce qui se trouve entre /d/ et /view)
# Par exemple avec https://drive.google.com/file/d/1ptwmJbk8ToMt4BvQeG5ni37IeNAOoAsb/view?usp=drive_link
file_id = '1ptwmJbk8ToMt4BvQeG5ni37IeNAOoAsb' # Remplacer par un fichier plus léger!
url= f'https://drive.google.com/uc?id={file_id}'
# Téléchargement du fichier csv
gdown.download(url, 'your_file_name.csv', quiet=True)
# Chargement du fichier csv dans un dataframe
df = pd.read_csv('your_file_name.csv')
df.head()
🗃️ ¿Tienes varios archivos que importar? gdown también permite importar un artículo de Drive y su contenido en bloque, antes de abrir el o los conjuntos de datos que te interesen.
import gdown
url = "https://drive.google.com/drive/folders/1HWFHKCprFzR7H7TYhrE-W7v4bz2Vc7Ia"
gdown.download_folder(url, quiet=True, use_cookies=False)
La salida de código enumera entonces las rutas de acceso de cada uno de los archivos del artículo:
Output
['https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/special_general.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/remain_person.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/general.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/eunuch.csv',
'https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/civil_servant.csv']
Abrimos entonces el archivo deseado con Pandas:
# Nous ouvrons le premier fichier avec pandas et vérifions les premières lignes
import pandas as pd
df = pd.read_csv('https://94fa3c88.delivery.rocketcdn.me/content/ihpperson_data_with_rules/special_general.csv')
df.head()
🔗 Para saber más: la documentación está disponible en https://pypi.org/project/gdown y nuestro script retoma la demo propuesta por Google Colab en la página https://colab.research.google.com/github/intodeeplearning/blog/blob/master/_notebooks/2022-05-08-how-to-download-files-in-gdrive-using-python.ipynb#scrollTo=I4vv49erlMC3
Escenario 3 con un atajo de Drive para archivos privados
¿Tus archivos fuente deben permanecer privados? Puedes compartir un notebook con tu equipo y ejecutarlo por turnos para analizar un conjunto de datos compartido únicamente con los demás miembros. El siguiente procedimiento busca armonizar la ruta de acceso a los archivos, para que cada miembro pueda ejecutar la misma celda de importación de los conjuntos de datos al inicio del notebook.
Veamos qué sucede para los usuarios A, B y C.
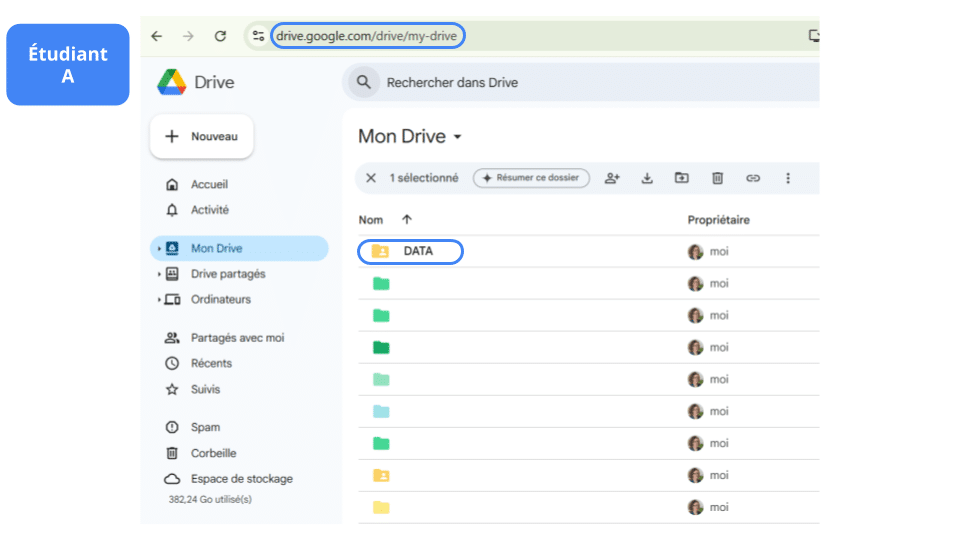
A deposita el conjunto de datos data.csv en un artículo «Data» creado en la raíz de su Drive y cuya ruta completa es la siguiente:
python '/content/drive/My Drive/Data/dataset.csv'
A comparte el artículo «Data» con sus compañeros B y C.
B y C, cada uno por su parte, encontrarán «Data» entre sus artículos compartidos, crearán el atajo a «Data» (haciendo clic derecho) y lo colocarán en la raíz de sus respectivos Drives (cada uno en «Mi Drive»).

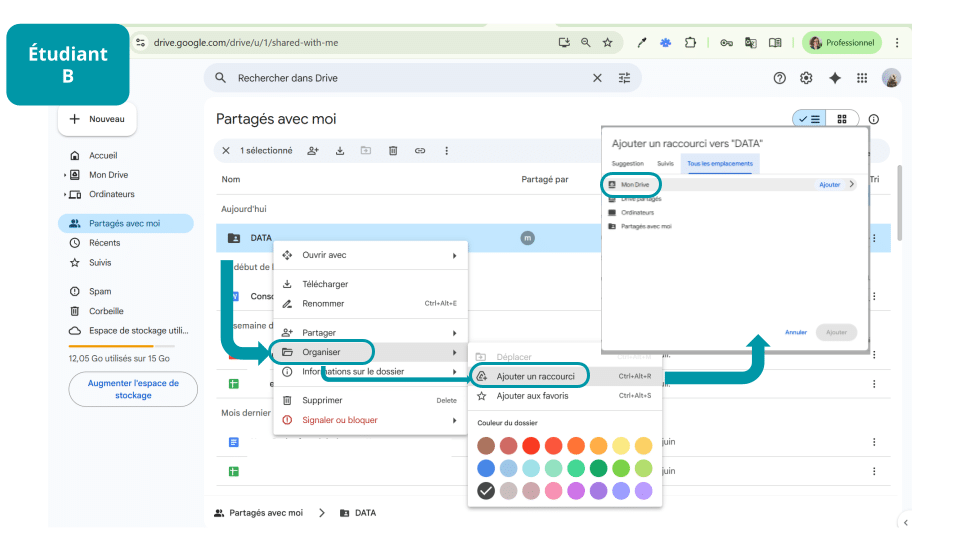

Entonces podrán usar la misma ruta que A:
python '/content/drive/My Drive/Data/dataset.csv'
El notebook incluirá entonces una celda de código para conectar Colab a Drive (cada estudiante trabajando por turnos deberá conectar el notebook a su Drive):
from google.colab import drive
drive.mount('/content/drive')
Luego la siguiente celda, para ejecutar y activar la ruta hacia el archivo:
# File path for A, B, C
import pandas as pd
pathA='/content/drive/My Drive/Data/dataset.csv'
df = pd.read_csv(pathA)
En resumen
- Al inicio de un proyecto final, durante la fase de exploración de un conjunto de datos abierto (por lo tanto, público), BytesIO ofrece la sintaxis más sencilla.
- En mitad del proyecto gdown ofrece una solución más interesante para limpiar, combinar y transformar datos provenientes de varios archivos de un mismo artículo.
- Si los conjuntos de datos deben permanecer privados, la solución alternativa consiste en organizar el intercambio de un único artículo que contenga todos los datasets, con un atajo idéntico para todos los demás miembros, de modo que usen una ruta de acceso común en Colab.
Para profundizar
- Google Colab: https://colab.google/
- Video introductorio a Google Colab (3 minutos): https://www.youtube.com/watch?v=inN8seMm7UI&ab_channel=TensorFlow
[1]: Graphic Processing Unit
[2]: Tensor Processing Unit
