El algoritmo de las K vecinas más cercanas o K-nearest neighbors (kNN) es un algoritmo de Machine Learning que pertenece a los algoritmos de aprendizaje supervisado simples y fáciles de aplicar que pueden ser utilizados para resolver problemas de clasificación y de regresión. En este artículo veremos la definición de este algoritmo, su funcionamiento así como también una aplicación directa en programación.
Definicion de KNN
Antes de concentrarnos en el algoritmo KNN, es necesario retomar las bases. ¿Qué es un algoritmo de aprendizaje supervisado?
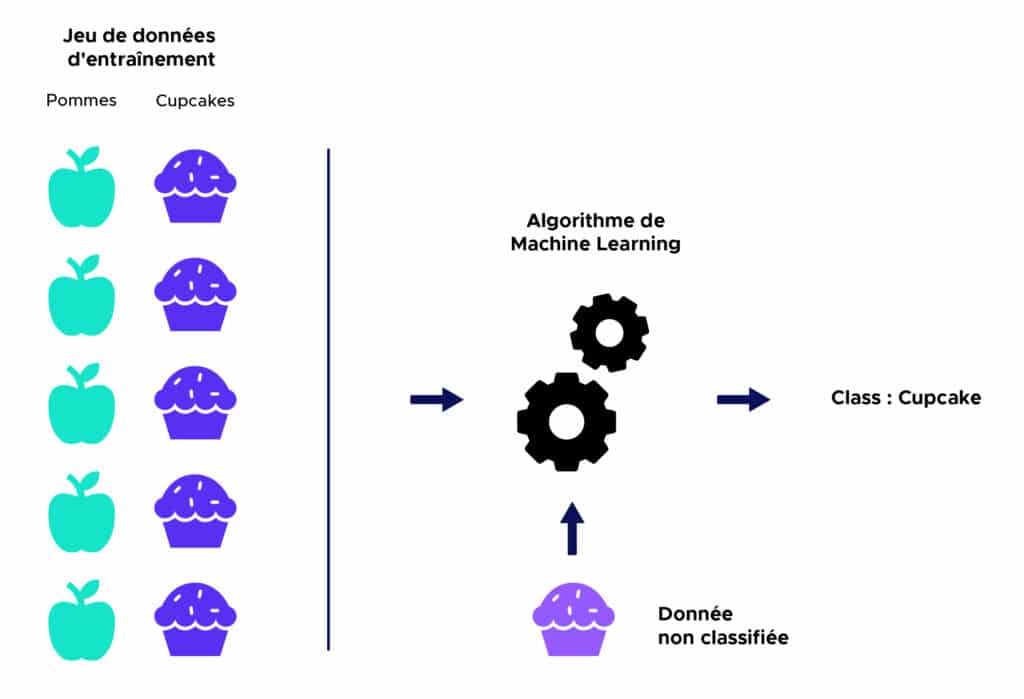
En aprendizaje supervisado, un algoritmo recibe un conjunto de datos que están etiquetados con los valores de salida correspondientes sobre los que puede entrenarse y definir un modelo de predicción. Este algoritmo podrá luego ser utilizado sobre datos nuevos para predecir sus valores de salida correspondientes.
A continuación, una ilustración simplificada :
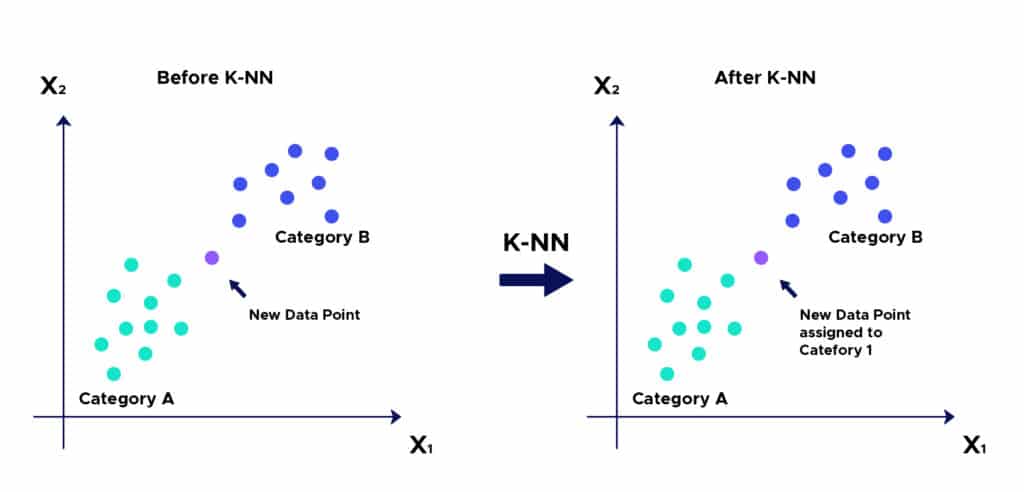
La lógica detrás del algoritmo de las K vecinas más cercanas es una de las más sencillas de todos los algoritmos de Machine Learning supervisados:
Etapa 1: Seleccionar el número de K vecinas
Etapa 2: Calcular la distancia
Euclidienne
Manhattan
Desde un punto no clasificado a otros puntos:
Etapa 3: tomar las K vecinas más cercanas según la distancia calculada
Etapa 4: entre las K vecinas, contar el número de puntos en cada categoría.
Etapa 5: atribuir un nuevo punto a la categoría más presente entre las K vecinas
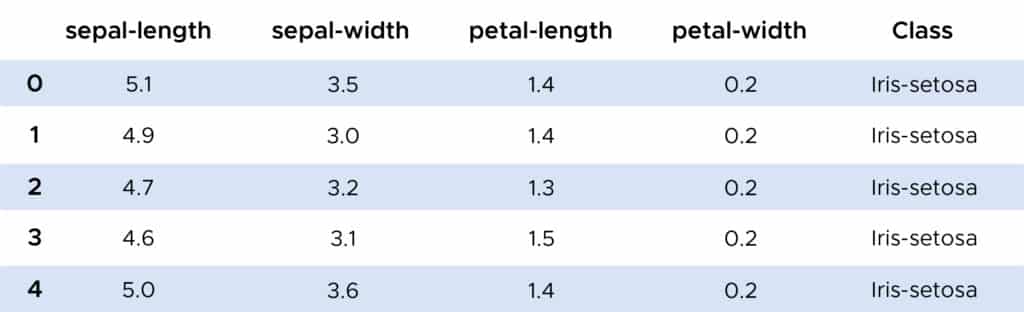
A partir de ahora podemos analizar un ejemplo sobre el uso del algoritmo de las K vecinas. Gracias a la biblioteca Scikit-Learn, podemos importar la función Neighbors Classifier que utilizaremos sobre un conjunto de datos IRIS.
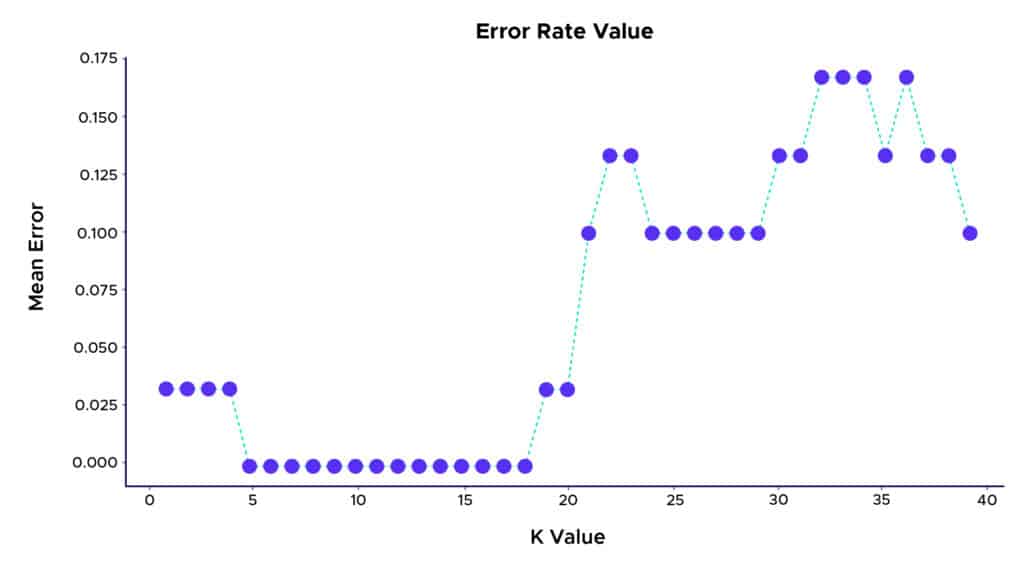
En el ejemplo, gracias al algoritmo KNN, obtenemos una excelente tasa de clasificación correcta de las plantas cercana al 100%. Podemos también considerar una forma de elegir la K que hace que la clasificación sea aún mejor. Una forma de encontrarla consiste en trazar el gráfico del valor K y la tasa de error correspondiente al conjunto de datos :
Así, podemos ver que la mejor tasa de predicción se obtiene con una K entre 5 y 18. Por encima de este valor, podemos observar un fenómeno llamado “overlifting”, o sobre aprendizaje en espanol, que se produce cuando los datos de aprendizaje utilizados para construir el modelo explican demasiado bien los datos pero no logran hacer predicciones útiles para nuevos datos.
Algunos usos :
Puede utilizarse en tecnologías como OCR (Optical Character Recognizer), que intenta detectar la escritura manuscrita, las imágenes e incluso los videos.
Puede utilizarse en el campo de las notaciones de crédito. En ese caso, intenta hacer corresponder las características de un individuo con el grupo de personas existentes para atribuirle la cotización de crédito correspondiente. Obtendrá entonces con la misma nota que las personas que corresponden a las mismas características.
Se utiliza también para predecir si el banco debe otorgar un préstamo a un particular. Busca evaluar si el individuo dado corresponde a los mismos criterios que otras personas que han sido rechazadas anteriormente y sino, no es rechazado para el préstamo.
Ventajas :
El algoritmo es simple y fácil de aplicar.
No es necesario crear un modelo, configurar varios parámetros o formular hipótesis suplementarias.
El algoritmo es polivalente. Puede ser utilizado para la clasificación o la regresión.
Desventajas :
El algoritmo se vuelve más lento a medida que el número de observaciones aumenta y las variables independientes aumentan.
Al tratarse de uno de los algoritmos más simples de Machine Learning, es muy implementado por los desarrolladores de sistemas basados en el aprendizaje, intuitivos e inteligentes que pueden efectuar y tomar pequeñas decisiones solos.
Esto hace que sea aún más práctico para el aprendizaje y el desarrollo y puede servir para toda industria que utilice sistemas, soluciones o servicios inteligentes.
Existen muchos otros algoritmos de Clustering supervisado o no Supervisado que son más o menos utilizados según la situación, como el de K-means, el de CAH (Clasificación ascendente jerárquica), DBSCAN (density-based spatial clustering of applications with noise), y muchos más que puedes descubrir en nuestro blog!