Si te interesa, aunque sea mínimamente, el span Machine Learning y los problemas de clasificación, ya has tenido que lidiar con el modelo de regresión logística. ¡Y con razón! Se trata de uno de los modelos de Machine Learning más sencillos e interpretables que existen, toma datos a la vez continuos o discretos y los resultados obtenidos con él son muy acertados.
Pero, ¿qué hay detrás de ese método milagroso? Y sobre todo, ¿cómo utilizarlo en Python? La respuesta está en este artículo.
Definición
La regresión logística es un modelo estadístico para estudiar las relaciones entre un conjunto de variables cualitativas Xi y una variable cualitativa Y. Se trata de un modelo lineal generalizado que utiliza una función logística como función de enlace.
Un modelo de regresión logística también permite predecir la probabilidad de que ocurra un evento (valor de 1) o no (valor de 0) a partir de la optimización de los coeficientes de regresión. Este resultado siempre varía entre 0 y 1. Cuando el valor predicho supera un umbral, es probable que ocurra el evento, mientras que cuando ese valor está por debajo del mismo umbral, no es así.
Matemáticamente, ¿cómo se traduce/escribe?
Considérons une entrée X= x1x2x3… xn, la régression logistique a pour objectif de trouver une fonction h telle que nous puissions calculer :
y= {1 si hX≥ seuil , 0 si hX< seuil}
Por tanto, entendemos que se espera que nuestra función h sea una probabilidad entre 0 y 1, parametrada por = 1 2 3 n para optimizar, y que el umbral que definimos corresponda a nuestro criterio de clasificación, por lo general se toma como igual a 0,5.
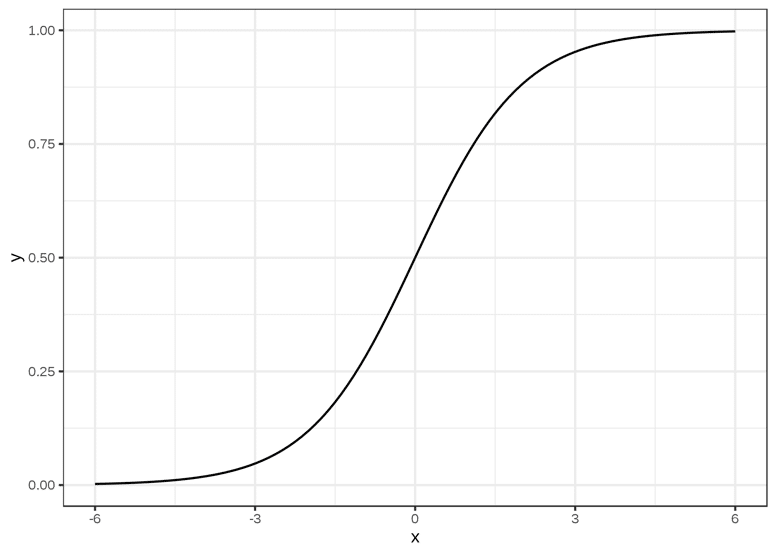
La función que mejor cumple estas condiciones es la función sigmoide, definida en R con valores en [0,1]. Se escribe de la siguiente manera :
Gráficamente, esto corresponde a una curva en forma de S cuyos límites son 0 y 1 cuando x tiende respectivamente a – y + ∞ pasando por y = 0,5 en x = 0.
Función sigmoide
¿Y nuestra clasificación en todo esto?
La función h que define la regresión logística se escribe entonces :
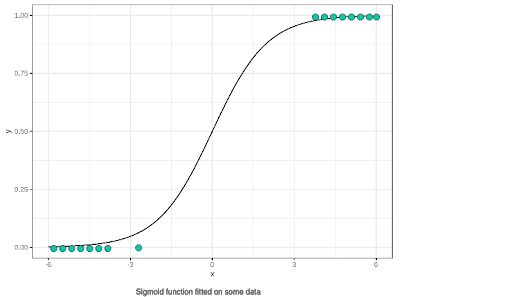
Todo el problema de la clasificación por regresión logística aparece entonces como un simple problema de optimización en el que, a partir de los datos, tratamos de obtener el mejor conjunto de parámetros Θ lo que permite que nuestra curva sigmoide se adhiera lo mejor posible a los datos. Aquí es donde entra el Machine Learning.
Una vez realizado este paso, así se vería el resultado que se puede obtener :
Solo queda, una vez definido el umbral, clasificar los puntos según sus posiciones en relación con la regresión y ya tenemos nuestra clasificación hecha.
La regresión logística en la práctica
EnPython es bastante sencillo, usamos la clase LogisticRegression del módulo sklearn.linear_model como un clasificador normal y lo entrenamos con datos ya limpios y separados en conjuntos de entrenamiento y de prueba, y listo.
En cuanto a código, es bastante básico :
Para aplicaciones más avanzadas, ¿por qué no seguir el curso ofrecido por el equipo de DataScientest?