Un random forest (o bosque aleatorio en español) es una técnica de Machine Learning muy popular entre los Data Scientist y con razón : presenta muchas ventajas en comparación con otros algoritmos de datos.
Es una técnica fácil de interpretar, estable, que por lo general presenta buenas coincidencias y que se puede utilizar en tareas de regresión o de clasificación. Cubre, por tanto, gran parte de los problemas de Machine Learning.
En random forest primero encontramos la palabra “forest” (bosque, en español). Se entiende que ese algoritmo se basa en árboles que se suelen llamar árboles de decisión.
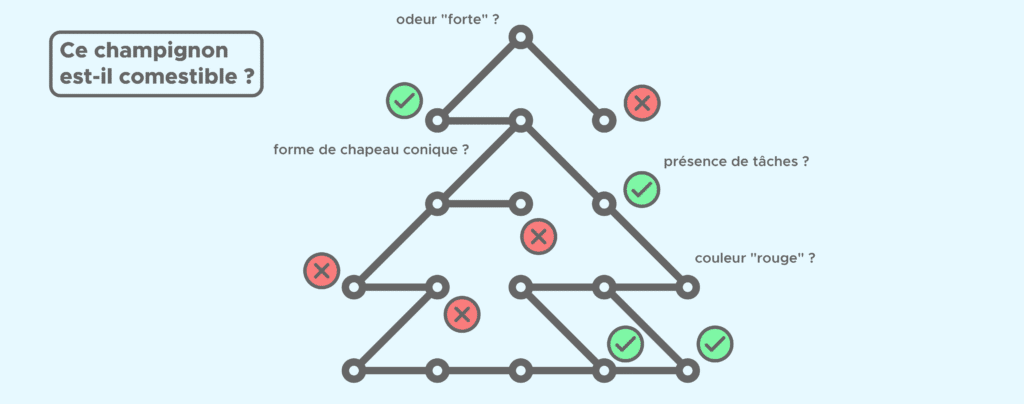
Un ejemplo de árbol de decisión
Como su nombre indica, un árbol de decisión ayuda al Data Scientist a tomar una decisión gracias a una serie de preguntas (también llamadas tests) cuya respuesta (sí o no) llevará a la decisión final.
Tomemos un ejemplo de clasificación binaria: queremos saber si una seta es comestible en función de los siguientes criterios (o features, en inglés): color, tamaño de la seta, forma del sombrero, olor, tamaño del pie, presencia de manchas, etc.
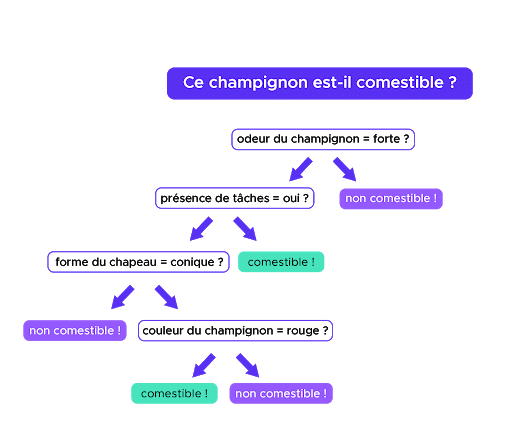
En el árbol, cada pregunta corresponde a un nudo, es decir, un lugar en el que una rama se bifurca en dos. En función de la respuesta a cada pregunta, vamos a dirigirnos hacia tal o tal rama del árbol para llegar a una hoja (o extremidad) que contenga la respuesta a nuestra pregunta.
Tal vez te preguntarás cómo se elige el orden de las preguntas: ¿por qué empezar por una u otra?
En cada nudo, el algoritmo se pregunta qué pregunta debería hacer, es decir si hay que interesarse más bien por el olor, la forma del sombrero o el tamaño de la seta. Por tanto, calculará para cada feature la ganancia de información que se obtendría si eligiésemos ese feature. Queremos maximizar la ganancia de información, por eso el árbol elige la pregunta y de ese modo el feature maximiza la ganancia.
El bosque como la combinación de árboles
Random forest es lo que se llama un método de conjunto (o ensemble method, en inglés), es decir que “pone junto” o combina resultados para obtener un superresultado final.
Pero, ¿los resultados de qué? Simplemente de los diferentes árboles de decisión que la componen.
Los random forest pueden constar de varias decenas, incluso centenas de árboles, el número de árboles es un parámetro que por lo general, se ajusta mediante validación cruzada (o cross-validation, en inglés). Para abreviar, la validación cruzada es una técnica de evaluación de un algoritmo de Machine Learning que consiste en entrenar y probar el modelo en fragmentos de la serie de datos de partida.
Cada árbol se entrena en un subconjunto de la serie de datos y da un resultado (sí o no, en el caso de nuestro ejemplo de las setas). Posteriormente, se combinan los resultados de todos los árboles de decisión para dar una respuesta final. Cada árbol “vota” (sí o no) y la respuesta final es la que tenga la mayoría de votos.
Es lo que se llama un método de bagging:
Dividimos nuestra serie de datos en varios subconjuntos compuestos aleatoriamente de muestras, de ahí el “random” de random forest.
Se entrena un modelo en cada subconjunto: habrá tantos modelos como subconjuntos.
Se combinan todos los resultados de los modelos (con un sistema de voto, por ejemplo) lo que nos da un resultado final.
De ese modo, se construye un modelo robusto a partir de varios modelos que no tienen por qué ser tan robustos.
Para resumir, este algoritmo es muy popular por su capacidad de combinar los resultados de sus árboles para obtener un resultado final más fiable. Su eficacia ha permitido que se utilice en muchos ámbitos como por ejemplo, el marketing telefónico para predecir el comportamiento de los clientes o incluso, las finanzas para la gestión de riesgos.
¿Quieres empezar un curso de Machine Learning? Descubre nuestros cursos especializados de Data Analyst, Data Scientist o Data Engineer.
