En data science y más específicamente en los data warehouses, los términos tabla de dimensión y tabla de hechos son conceptos clave en cualquier modelo de datos, entre otros, para fines de análisis.

Recordatorio: ¿qué es un data warehouse?
Un data warehouse es una plataforma centralizada de almacenamiento de datos, diseñada para facilitar el análisis y la toma de decisiones. Reúne datos de diferentes fuentes y los organiza de manera que permita realizar análisis rápidos y eficientes. A diferencia de las bases de datos operacionales, un data warehouse está optimizado para el análisis de datos históricos, ofreciendo así una mejor visión de los rendimientos pasados y presentes.
¿Qué es una tabla de dimensión?
Una dimensión es una tabla que almacena atributos cualitativos de un elemento clave del proceso de la empresa. Estos atributos se utilizan para describir los hechos numéricos, que a su vez se registran en las tablas de hechos.
Por ello, las dimensiones permiten proporcionar un contexto a las medidas cuantitativas. Ofrecen detalles sobre los eventos, por ejemplo, quién, cuándo, dónde o a qué producto se realizó una venta.
Estos atributos pueden incluir elementos como el producto, la fecha, el cliente o incluso el lugar. Estas tablas están organizadas de manera que hacen que el análisis de datos sea más intuitivo, facilitando así la comprensión de las tablas de hechos, que contienen en cambio las medidas cuantitativas.
Los tipos de esquemas utilizados
Existen varios modelos para organizar las tablas de hechos y de dimensiones, especialmente los modelos en estrella (star schema) y en copo de nieve (snowflake schema).

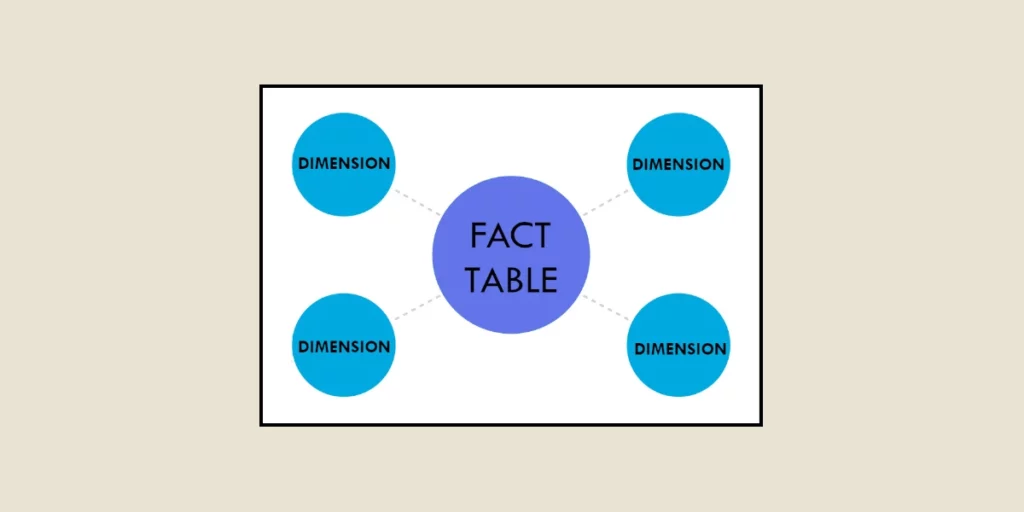
Star Schema
Este tipo de esquema es el más simple y el más comúnmente utilizado en data warehousing. Aquí, las tablas de hechos se colocan en el centro y están conectadas a las tablas de dimensiones que las rodean, formando una estructura en forma de estrella. Esto facilita el análisis de datos porque las relaciones entre tablas son claras y poco complejas. Generalmente, es el enfoque aconsejado cuando sea posible.
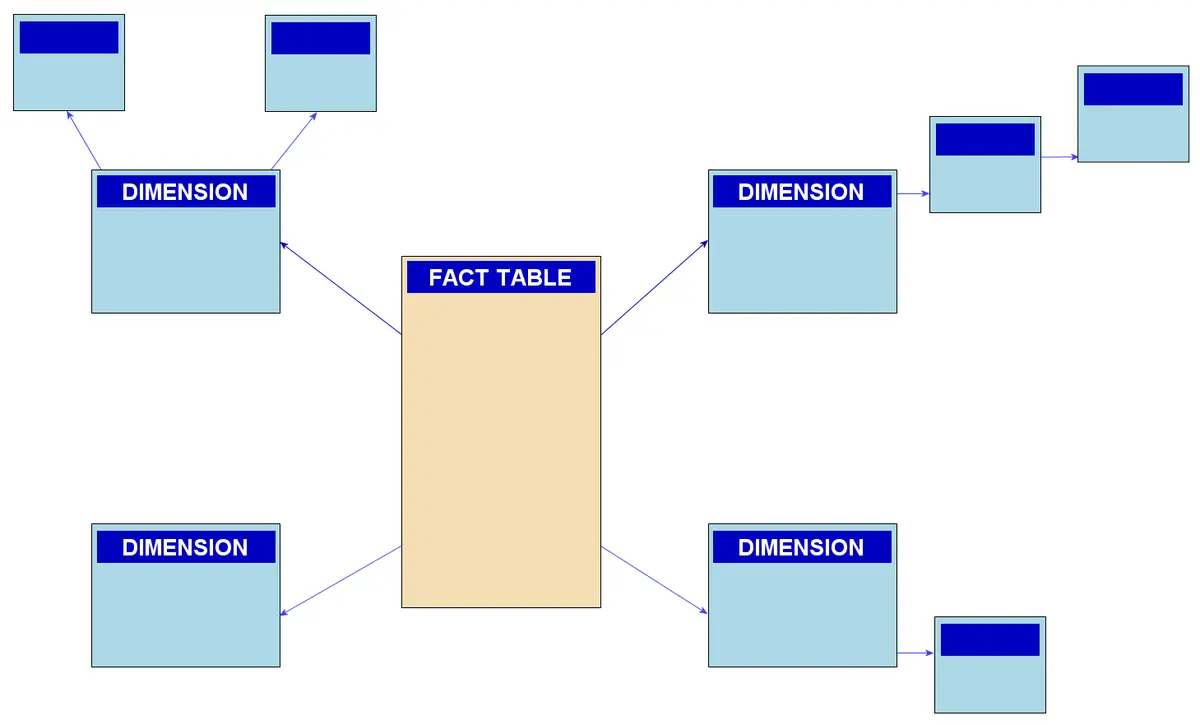
Snowflake Schema
El esquema en copo de nieve es una extensión del star schema, en el que las tablas de dimensiones están normalizadas a varios niveles. Esto significa que los atributos de una dimensión están a su vez conectados a otras tablas, formando una estructura más compleja que se asemeja a un copo de nieve. Esto permite reducir la redundancia de datos, pero aumenta la complejidad de las consultas.
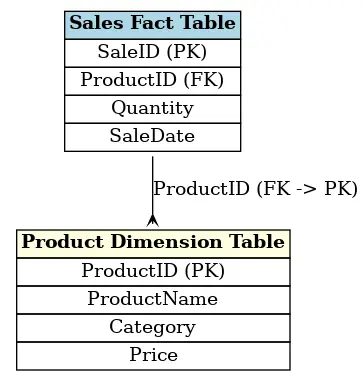
Primary Keys y Foreign Keys
En un modelo dimensional, las tablas de dimensiones disponen de una clave primaria (primary key) que identifica de manera única cada fila. Esta primary key se utiliza a su vez en la clave foránea (foreign key) de la tabla de hechos para crear una relación entre las tablas.
Por ejemplo, una tabla de hechos de ventas (sales fact table) puede tener una columna «ProductID» que es una foreign key que apunta a la primary key de la tabla de dimensión producto. Estas relaciones permiten cruzar los datos de diferentes tablas para obtener análisis ricos y detallados.
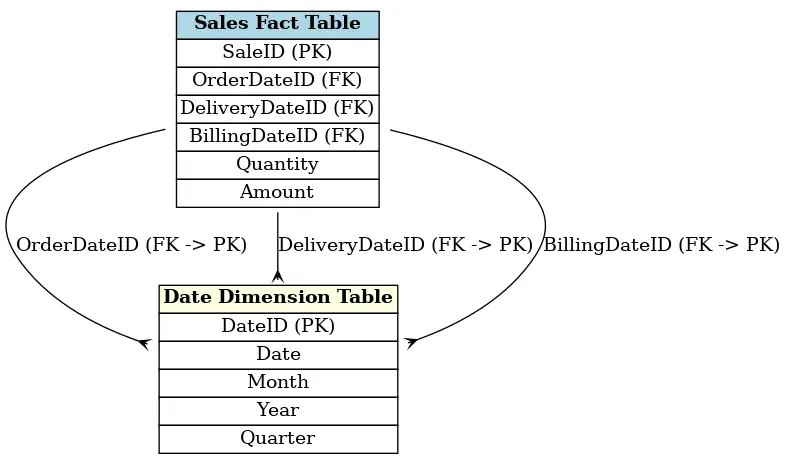
Role-Playing Dimensions
Algunas dimensiones pueden desempeñar diferentes roles en el modelo de datos. Por ejemplo, una dimensión de fecha puede ser utilizada para representar la fecha de pedido, la fecha de entrega, o la fecha de facturación. Se habla entonces de role-playing dimensions. Esto permite evitar la duplicación de datos utilizando una sola dimensión para diferentes usos.
Dimensiones de Cambio Lento (Slowly Changing Dimensions)
Las dimensiones pueden evolucionar con el tiempo, y a menudo es necesario seguir estos cambios en el data warehouse. Por ejemplo, un cliente puede cambiar de dirección. Estos cambios deben ser gestionados para ser capaces de entender en qué momento estas modificaciones ocurrieron y cómo afectaron a los hechos.
Las slowly changing dimensions (SCD) permiten gestionar este tipo de variación. Existen varios tipos, entre ellos:
- Tipo 1: El cambio simplemente reemplaza el valor anterior.
- Tipo 2: Se añade una nueva fila para cada modificación, permitiendo conservar el historial.
- Tipo 3: Se añade una nueva columna para conservar el valor anterior.
La importancia de las dimensiones en el análisis de datos
Las dimensiones permiten transformar valores numéricos en información utilizable. Ayudan a responder a preguntas estratégicas en el contexto de business process, tales como:
- ¿Qué producto se vende mejor?
- ¿Quiénes son nuestros mejores clientes?
- ¿Cuál es el momento más rentable del año?
Usando dimensiones pertinentes como el producto, la fecha o el cliente, los analistas pueden segmentar los datos de ventas o producción y así obtener una visión más precisa de los rendimientos de la empresa. Es esta asociación entre facts y dimensiones lo que permite un análisis de datos bien informado.
Conclusión
Las dimensiones son extremadamente importantes en un data warehouse y no deben ser subestimadas, ya que permiten dar sentido a los datos cuantitativos contenidos en las tablas de hechos. Al organizar los datos con esquemas en estrella o en copo de nieve, utilizando las claves primarias y foráneas, y aprovechando role-playing dimensions, un data warehouse puede proporcionar una base sólida para un análisis de datos profundo.
