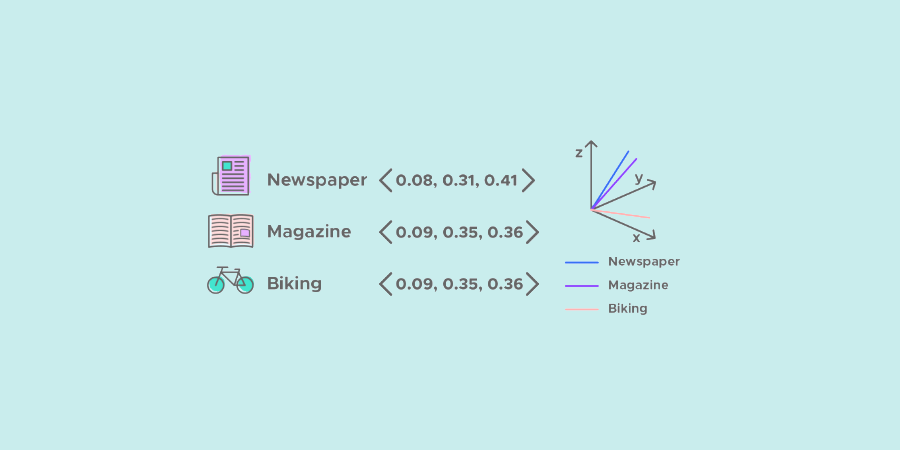
En un artículo anterior, definimos NLP – Procesamiento del Lenguaje Natural. En este artículo, nos centraremos en uno de sus principales métodos, el Word Embedding. El Word Embedding (incrustación de palabras) designa un conjunto de métodos de aprendizaje destinados a representar las palabras de un texto mediante vectores numéricos reales. En este artículo, vas a explorar tres de los métodos principales para representar una palabra como vector :
Método 1 : One Hot Encoding
Método 2 : Image Embedding
Método 3 : Word Embedding
One hot encoding
La representación vectorial más clásica de las palabras es la one hot encoding. Se asigna una dimensión a cada palabra del vocabulario. Cada palabra del vocabulario se representa como un vector binario con todos sus valores a cero, excepto el índice de la palabra.

Para ilustrar la codificación, analicemos la siguiente frase :
«I think therefore I am»
El principio es asignar un índice a cada palabra del vocabulario. El vocabulario se presenta entonces en forma de diccionario :
{'am': 0, 'i': 1, 'therefore': 2, 'think': 3} Aquí, el vocabulario está compuesto por las 4 palabras únicas de nuestro corpus. El método consiste entonces en representar la palabra del vocabulario como un vector de dimensión 4 (tamaño del vocabulario) que tiene todos sus valores a cero excepto el índice de la palabra.
Onehot(‘i’)=0 1 0 0
Con esta representación, todas las palabras tienen la misma distancia y similitud. Por tanto, la codificación one hot solo proporciona información según la cual una palabra es diferente de otra.
Image Embedding
El tamaño de una imagen se define por su número de píxeles. Como vimos en un artículo anterior [enlace a la sección CNN del dosier DL], utilizamos convoluciones para extraer las características más relevantes que el valor de los píxeles. Por ejemplo, los núcleos utilizados para detectar bordes podrían ser útiles para clasificar determinadas formas geométricas.
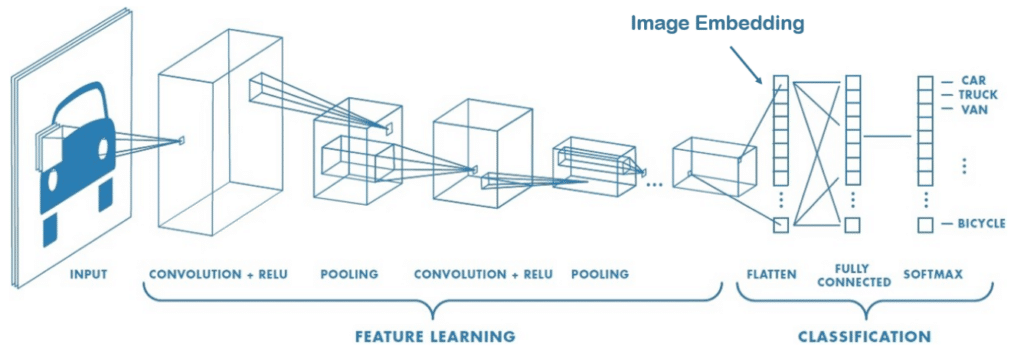
El image embedding es capaz de utilizar las convoluciones/pooling para codificar la imagen y extraer las relaciones de linealidad entre las propiedades (estilo artístico, forma específica, etc.) y las nuevas características de nuestra imagen.

Word Embedding
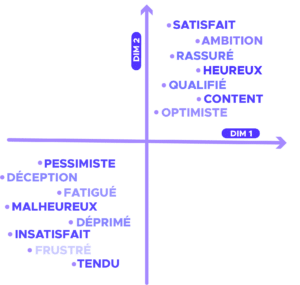
Por analogía, el word embedding es capaz de capturar el contexto, la similitud semántica y sintáctica (género, sinónimos, etc.) de una palabra reduciendo el tamaño. Por ejemplo, cabría esperar que las palabras «perro» y «gato» estuvieran representadas por vectores relativamente cercanos en el espacio vectorial donde se definen esos vectores.
Al igual que con las imágenes, queremos que el modelo elija las características más relevantes para representar la palabra. Por ejemplo, la característica «ser vivo» podría ser interesante para diferenciar «perro» y «ordenador», y para acercar «perro» y «gato».
Matrice d’embedding
El método de embedding que se suele utilizar para reducir la dimensión de un vector es utilizar el resultado que devuelve una capa densa como embedding, es decir, multiplicar una matriz de embedding W por la representación «one hot» de la palabra :

En forma de vector :
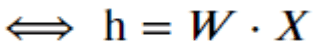
Ahora que hemos definido el método de reducción de la dimensión (compresión de la información), ¿cómo entrenamos la matriz de embedding W?
Entrenamiento de la matriz de embedding: problema de clasificación
Una primera forma de encontrar la matriz de embedding es entrenarla en un problema supervisado. Por tanto, utilizaremos esa representación de palabras para resolver un problema de análisis de sentimientos en las reseñas de IMBD. La serie de datos contiene 25.000 críticas de películas (más información sobre la serie de datos aquí).
Entonces se puede entrenar la matriz W del word embedding a la vez que se entrena el problema de clasificación.
Formateo de los datos :
Para formatear los datos, es necesario vectorizar el corpus de texto, transformando cada reseña en una secuencia de enteros (cada número entero es el índice de una palabra) :
tokenizer.texts_to_sequences([‘hello my dear readers’]) -> [[4422, 10, 2974, 6117]]

Nuestro modelo será un simple bag of word con un método de embedding :
- La capa de embedding transformará cada índice de palabras en un vector de embedding. La matriz W del embedding se aprenderá a medida que se entrene el modelo. Las dimensiones resultantes son: (lote, secuencia, embedding).
- A continuación, la capa GlobalAveragePooling1D devuelve un vector de salida de longitud fija para cada ejemplo, sacando la media de la dimensión de la secuencia. Esta transformación consiste en hacer una bag of word y permite que el modelo gestione entradas de longitud variable.
- Por último, como estamos ante un problema de clasificación (reseña positiva o negativa), es necesario añadir capas densas para clasificar el sentimiento de la reseña.
¿Y si pasamos a la práctica?
De este modo, hemos conseguido en la serie de datos de prueba una precisión de 0,88. Esta puntuación es difícil de conseguir con ayuda de los métodos clásicos. Además, también podríamos haber utilizado un método tf-idf (en lugar de la bag of word) para transformar nuestra secuencia en un vector.
Conclusión
Un modelo de este tipo suele dar mejores resultados que los enfoques tradicionales. También permite reducir el tamaño del problema y, por tanto, la tarea de aprendizaje. Sin embargo, como solo damos información sobre el sentimiento, al word embedding le cuesta captar cualquier otra relación.
En un próximo artículo, entrenaremos la matriz de embedding de forma no supervisada utilizando el conocido algoritmo word2vec. Como el entrenamiento se realiza sin supervisión, evitaremos el sesgo asociado a la resolución de un problema supervisado.
¿Te ha gustado este artículo? ¿Quieres saber más sobre la Data Science?
