
Introduit en 2014, AWS Lambda est une plateforme serverless de Function as a Service. Qu’est-ce que cela signifie ? Quels sont les cas d’usages principaux ? C’est ce que nous allons détailler dans cet article, afin d’expliquer la popularité croissante du service.
Qu’est-ce AWS Lambda ?
Fondamentalement, le principe de AWS Lambda est très simple. Il s’agit de déployer des fonctions (c’est-à-dire du code), qui vont réagir à des événements, sans s’occuper de l’infrastructure sous-jacente.
En clair, il n’est pas nécessaire d’instancier des machines virtuelles (serveurs) sur lesquelles tournera notre application. AWS se charge pour vous de l’environnement d’exécution. C’est pour cette raison que l’on parle de service serverless (sans serveur) : même s’il existe bien sûr des serveurs qui permettent d’héberger l’application, ils sont totalement abstraits pour le client.
Ceci a trois avantages principaux :
- Réduire (et même supprimer) le temps passé sur la gestion des serveurs : maintenance, mise à jour, patch de sécurité, etc.
- Permettre une scalabilité quasi infinie par défaut : que la fonction soit exécutée une fois par jour ou plus d’un millions de fois, AWS adaptera le service en fonction, sans que vous ayez besoin de gérer le load balancing et l’auto scaling.
- Le load balancing (ou répartition de charge) consiste à répartir des tâches (par exemple des requêtes à traiter) sur un ensemble de serveurs plutôt qu’un seul, afin de rendre le processus global plus efficient.
- L’auto scaling consiste à ajuster automatiquement la capacité de calcul (c’est-à-dire le nombre de serveurs derrière le load balancer) en fonction de la charge (que l’on peut par exemple mesurer grâce au nombre de requêtes par minute).
- Permettre une facturation en fonction de l’usage : la facturation est faite par milliseconde d’exécution. Si la fonction n’est pas exécutée, vous ne serez tout simplement pas facturé.
Comme il n’y a pas de serveur qui tourne en permanence, l’exécution des fonctions doit être déclenchée à partir d’événements. Les sources d’événements peuvent être très diverses : on peut déclencher l’exécution d’une fonction lorsqu’un fichier est téléversé sur un bucket S3, qu’un enregistrement est ajouté à une table DynamoDB, en réponse à une requête HTTP (via une intégration avec le service API Gateway), ou bien simplement via un scheduling (on peut décider d’invoquer la fonction périodiquement, toutes les minutes ou heures par exemple).
Quelques cas d’usages
Les cas d’usages des fonctions AWS Lambda sont très variés, du fait de la grande quantité d’intégrations avec d’autres services en tant qu’événement source. On peut notamment faire du traitement de données en temps réel, de la transformation de fichier, ou même des backends pour des applications web ou mobiles.
Génération d'aperçus d’image
Un des exemples les plus communément évoqués de cas d’usage est la génération de thumbnails (aperçu) lors du téléversement d’une image sur un bucket (compartiment) S3.
Supposons que vous développiez une application qui permet à des utilisateurs de téléverser des images, et de les partager. Vous souhaitez que l’utilisateur puisse importer des photos en très grande résolution, mais vous souhaitez afficher des aperçus en faible résolution sur la galerie d’image, afin que celle-ci se charge rapidement.
Pour ce faire, vous pouvez utiliser S3 et Lambda : un premier compartiment S3 peut être utilisé pour stocker les images de vos utilisateurs. En utilisant la notification d’événement, vous pouvez invoquer une fonction Lambda à chaque fois qu’un fichier est créé dans ce compartiment. Cette fonction peut alors générer un aperçu à partir de l’image, puis la stocker dans un nouveau compartiment, qui contiendra donc l’ensemble des thumbails :
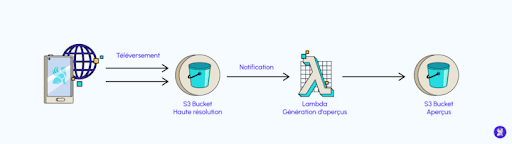
Grâce à cette architecture serverless et event-driven, votre application passera à l’échelle automatiquement en fonction du nombre de téléversements effectués par les utilisateurs.
On pourrait facilement imaginer d’autres applications similaires :
- Génération d’une transcription automatique (via AWS Transcribe) lors de l’upload d’un fichier audio.
- Traitement en temps réel de données provenant d’un stream (Kinesis, Kafka).
Backends d'applications web et mobiles
Une autre application très courante des fonctions AWS Lambda est le développement de backend pour des applications mobiles ou web.
En effet, il est possible d’utiliser une fonction Lambda pour traiter des requêtes vers API Gateway.
En utilisant également une base de données telle que DynamoDB, vous pouvez développer des backend entièrement serverless (couches web, applicative et base de données), qui passera à l’échelle parfaitement en fonction de l’utilisation :

Pour aller plus loin
Vous l’avez compris, AWS Lambda permet des applications très variées, et c’est ce qui explique en partie sa popularité croissante.
Il existe néanmoins certaines limitations et complexités inhérentes à l’utilisation des fonctions Lambda.
Parmi les limitations, on peut citer le temps d’exécution maximal d’une fonction, qui est de 15 minutes : les fonctions Lambda ne sont pas conçues pour effectuer des tâches longues. Par exemple, si vous souhaitez effectuer un entraînement de modèle de Machine Learning, AWS Lambda ne sera probablement pas le bon choix. La mémoire des fonctions est également limitée à 10Go, et la puissance CPU à 6 vCPUs.
Une autre complexité que l’on peut citer est la difficulté de développer et déployer des applications complexes avec Lambda.
En effet, pour créer une fonction assez simple, vous pouvez simplement passer par la console AWS :
Pour aller plus loin
Vous l’avez compris, AWS Lambda permet des applications très variées, et c’est ce qui explique en partie sa popularité croissante.
Il existe néanmoins certaines limitations et complexités inhérentes à l’utilisation des fonctions Lambda.
Parmi les limitations, on peut citer le temps d’exécution maximal d’une fonction, qui est de 15 minutes : les fonctions Lambda ne sont pas conçues pour effectuer des tâches longues. Par exemple, si vous souhaitez effectuer un entraînement de modèle de Machine Learning, AWS Lambda ne sera probablement pas le bon choix. La mémoire des fonctions est également limitée à 10Go, et la puissance CPU à 6 vCPUs.
Une autre complexité que l’on peut citer est la difficulté de développer et déployer des applications complexes avec Lambda.
En effet, pour créer une fonction assez simple, vous pouvez simplement passer par la console AWS :
Mais quand le code de l’application croît, passer par l’environnement de développement intégré à la console AWS s’avère peu efficient, voire impossible.
Dans ce cas, il est nécessaire de développer son application en local sur son ordinateur, et d’avoir un processus répétable pour packager son code et le déployer sur AWS, ce qui peut s’avérer complexe.
Pour simplifier cette tâche (et bien plus), vous pouvez notamment utiliser le framework Serverless, qui vous permettra de définir vos fonctions Lambda et le code associé, leurs intégrations, ainsi que d’autres ressources serverless (par exemple des tables DynamoDB). Une fois cette stack définie, vous pourrez la déployer sur AWS très simplement à l’aide du framework.
Conclusion
Si vous souhaitez en savoir plus sur les fonctions AWS Lambda, et plus généralement sur l’architecture des systèmes IT dans le cloud AWS, vous pouvez vous inscrire à l’une de nos formations sur ce cloud provider.






