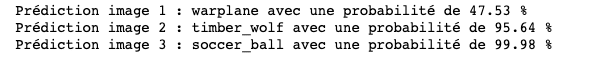En esta parte, vamos a centrarnos en uno de los algoritmos más eficaces del Deep Learning, las Convolutional Neural Network o CNN: redes neuronales convolucionales, son modelos de programación potentes que permiten principalmente el reconocimiento de imágenes atribuyendo automáticamente a cada imagen proporcionada en la entrada, una etiqueta correspondiente a la clase a la que pertenece.
Te damos la bienvenida a este tercer episodio de nuestro dossier de Deep Learning. Después de la introducción al Deep Learning y sus aplicaciones en la primera parte, abordamos ahora la estructura y el funcionamiento de las redes neuronales en esta segunda parte.
A primera vista, su modo de funcionamiento es sencillo: el usuario proporciona una imagen de entrada en forma de matriz de píxeles.
Esta dispone de 3 dimensiones:
Dos dimensiones para una imagen en niveles de gris.
Una tercera dimensión, de profundidad 3 para representar los colores fundamentales (rojo, verde, azul).
Al contrario que un modelo MLP (Multi Layers Perceptron) clásico que solo contiene una parte de clasificación, la arquitectura de la Convolutional Neural Network dispone previamente de una parte convolucional y consta por tanto de dos partes bien diferenciadas:
Un parte convolucional: Su objetivo final es extraer características propias de cada imagencomprimiéndolas para reducir su tamaño inicial. En resumen, la imagen proporcionada de entrada pasa a través de una sucesión de filtros, creando a la vez nuevas imágenes llamadas tarjetas de convoluciones. Por último, las tarjetas de convolucionesobtenidas se concatenan en un vector de características llamado código CNN.
Una parte de clasificación: El código CNN obtenido en la salida de la parte convolucional se suministra como entrada en una segunda parte, compuesta de capas totalmente conectadas llamadas perceptrón multicapa (MLP o Multi Layers Perceptron). El papel de esta parte es combinar las características del código CNN para clasificar la imagen. Para volver a esta parte, no dudes en consultar el artículo sobre este tema.
Schéma représentant l’architecture d’un CNN
Parte convolucional
En primer lugar, ¿para qué sirve la convolución?
La convolución es una operación matemática sencilla que se suele utilizar para el tratamiento y el reconocimiento de imágenes. En una imagen, su efecto se asimila a un filtrado, aquí puedes ver su funcionamiento:
Schéma du parcours de la fenêtre de filtre sur l'image
En primer lugar, se define el tamaño de la ventana de filtro situada en la parte superior izquierda.
La ventana de filtro, que representa la característica, se desplaza progresivamente de izquierda a derecha un determinado número de casillas definido previamente (el paso) hasta llegar al final de la imagen.
En cada porción de imagen que encuentra, se efectúa el cálculo de convolución permitiendo obtener en la salida una tarjeta de activación o feature map que indica dónde están localizadas las features en la imagen: cuanto más arriba esté la feature, más se parecerá a ella la porción de imagen barrida.
Durante la parte convolucional de una Convolutional Neural Network, la imagen proporcionada de entrada pasa a través de una serie de filtros de convolución. Por ejemplo existen filtros de convolución que se suelen utilizar y que permiten extraer características más pertinentes que píxeles como la detección de bordes (filtro derivador) o formas geométricas. La elección y la aplicación de los filtros la hace de forma automática el modelo.
Entre los filtros más conocidos, encontramos en particular el filtro promediador (calcula para cada píxel la media del píxel con sus 8 vecinos más cercanos) o incluso el filtro gaussiano que permite reducir el ruido de una imagen proporcionada de entrada:
Aquí puedes ver un ejemplo de esos dos filtros diferentes en una imagen que incluye un gran ruido (se puede pensar en una fotografía tomada con poca luminosidad por ejemplo). Sin embargo, uno de los inconvenientes de la reducción del ruido es que por lo general va acompañada de una reducción de la nitidez:
Effet des filtres moyenneur et gaussien - DataScientest
Como se puede observar, al contrario del filtro promediador, el filtro gaussiano reduce el ruido sin reducir significativamente la nitidez.
Además de su función de filtrado, el interés de la parte convolucional de una CNN es que permite extraer características propias de cada imagen comprimiéndolas para reducir su tamaño inicial, a través de métodos de submuestreo como el Max-Pooling.
Método de submuestreo : el Max-Pooling
El Max-Pooling es un proceso de discretización basado en muestras. Su objetivo es submuestrear una representación de entrada (imagen, matriz de salida de capa escondida, etc.) reduciendo su tamaño. Además, su interés es que reduce el coste de cálculo reduciendo el número de parámetros que tiene que aprender y proporciona una invariancia por pequeñas translaciones (si una pequeña translación no modifica el máximo de la región barrida, el máximo de cada región seguirá siendo el mismo y por tanto la nueva matriz creada será idéntica).
Para que la acción del Max-Pooling sea más concreta, aquí tienes un ejemplo: imagina que tenemos una matriz de 4×4 que representa nuestra entrada inicial y un filtro de una ventana de 2×2 que aplicaremos en nuestra entrada. Para cada región barrida por el filtro, el Max-pooling tomará el máximo y de ese modo creará a la vez una nueva matriz de salida en la que cada elemento corresponderá a los máximos de cada región detectada.
Ilustremos el proceso :
Procesamiento del Max-Pooling
La ventana de filtro se desplaza dos píxeles hacia la derecha (stride/paso = 2) y recupera en cada paso “el argmax” que corresponde al valor más alto de los 4 valores de píxeles.
Exemple d’effet du Max-Pooling
Se comprende mejor la utilidad de la parte convolucional de una CNN: al contrario que un modelo MLP clásico, añadir previamente la parte convolucional permite obtener en la salida una “tarjeta de características” o “código CNN” (matriz de píxeles situada a la derecha en el ejemplo) cuyas dimensiones son más pequeñas que las de la imagen inicial lo cual va a tener la ventaja de disminuir en gran medida el número de parámetros que tiene que calcular el modelo.
Después de la parte convolucional de una CNN, viene la parte de clasificación. Esa parte de clasificación, común para todos los modelos de redes neuronales, corresponde a un modelo de perceptrón multicapas (MLP).
Su objetivo es atribuir a cada muestra de datos una etiqueta que describa la clase a la que pertenezca.
Representación de un perceptrón multicapas
El algoritmo que utilizan los perceptrones para actualizar sus pesos (o coeficientes de redes) se llama la retropropagación del gradiente del error, famoso algoritmo de descenso de gradiente que veremos más en detalle después.
Ejemplo de arquitectura de una CNN
Por lo general, la arquitectura de una Convolutional Neural Network es prácticamente igual:
Capa de convolución (CONV): El papel de esta primera capa es analizar las imágenes proporcionadas en la entrada y detectar la presencia de un conjunto de features. A la salida de esa capa se obtiene un conjunto de features maps (ver más arriba: ¿para qué sirve la convolución?).
Capa de Pooling (POOL): La capa de Pooling es una operación que por lo general se aplica entre dos capas de convolución. Esta recibe en la entrada las features maps formadas en la salida de la capa de convolución y su papel es reducir el tamaño de las imágenes y, a la vez, preservar sus características más esenciales. Entre las más utilizadas, encontramos el Max-pooling mencionado más arriba o incluso el Average pooling cuyo manejo consiste en conservar en cada paso, el valor medio de la ventana de filtro.
Finalmente, se obtiene en la salida de esa capa de Pooling el mismo número de feature maps que en la salida, pero considerablemente comprimidas.
La capa de activación ReLU (Rectified Linear Units): Esa capa sustituye todos los valores negativos recibidos en la entrada por ceros. El interés de esas capas de activación es hacer que el modelo sea no lineal y por tanto, más complejo.
Función de activación ReLU
Capa Fully Connected (FC): Estas capas se colocan al final de la arquitectura de la CNN y se conectan por completo a todas las neuronas de salida (de ahí el término fully-connected). Después de haber recibido un vector en la entrada, la capa FC aplica sucesivamente una combinación lineal y una función de activación con la finalidad de clasificar el input imagen (ver el siguiente esquema). Finalmente en la salida devuelve un vector de tamaño correspondiente al número de clases en el que cada componente representa la probabilidad de que el input imagen pertenezca a una clase.
Funcionamiento de una red neuronal con 2 capas escondidas
Implementación de una CNN preentrenada en Python :
Para usos prácticos y considerando la complejidad de creación de las eficaces CNN “hechas a mano”, vamos a utilizar las redes preentrenadas disponibles en el módulo Torchvision. Veamos cómo se puede implementar en Python:
Aplicación de una CNN : Identificación de imágenes genéricas a partir del dataset ImageNet: diez millones de imágenes etiquetadas
ImageNet es una base de datos de más de diez millones de imágenes etiquetadas creada por la organización del mismo nombre, y destinada a trabajos de investigación de visión por computador.
Aquí tienes un extracto de ese voluminoso dataset:
Extrait de la base de données ImageNet
Etapa 0 : Primero, importamos todas las bibliotecas que serán necesarias para los siguientes pasos
Etapa 1 : Entrenamiento del modelo preentrenado VGG16
Etapa 2 : Importación de las 3 imágenes que hay que predecir
Etapa 3 : Pretratamiento de las imágenes
Etapa 4 : Predicción del modelo
Visualización de las predicciones del modelo VGG16
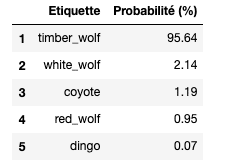
También se pueden visualizar las 5 etiquetas que VGG16 estime como más probables :
Top 5 des labels jugés les plus probables par VGG16
→ Por tanto VGG16 ha conseguido predecir con gran confianza (95,6 %) no solo que la imagen proporcionada en la entrada era un lobo, sino que ha ido un paso más allá y ha precisado su raza, es decir un lobo gris del Este (timber wolf). Impresionante, ¿no?
Por último, el principio de funcionamiento de una CNN es bastante fácil de comprender, pero paradójicamente, la implementación de un procedimiento como este para clasificar imágenes sigue siendo muy complejo debido al número considerable de parámetros que hay que definir: número, tamaño, desplazamiento de filtros, elección del método de pooling, elección del número de capas neuronales, número de neuronas por capas, etc.
Para paliar ese obstáculo, Python ofrece, a través del módulo de Torchvision, la posibilidad de explotar modelos de CNN preentrenados eficaces como VGG16, Resnet101, etc.
En este artículo hemos definido el funcionamiento y la arquitecturade las Convolutional Neural Network, centrándonos en su especificidad: la parte convolucional.
Todavía nos queda por descubrir una etapa de la clasificación: la retropropagación del gradiente del error, famoso algoritmo de descenso de gradiente. No te preocupes, pronto podrás leer el próximo capítulo sobre el tema en nuestro blog.