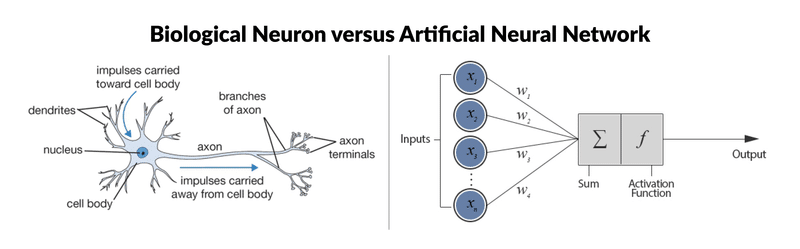
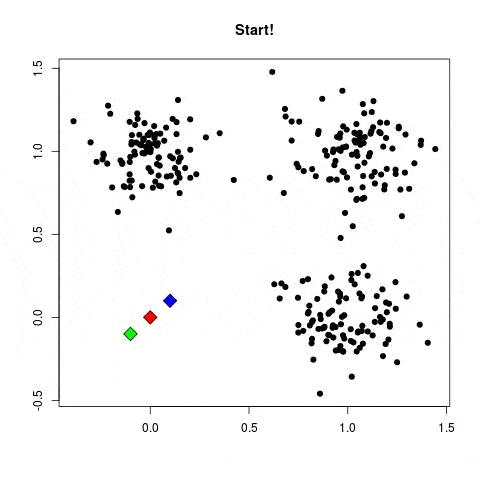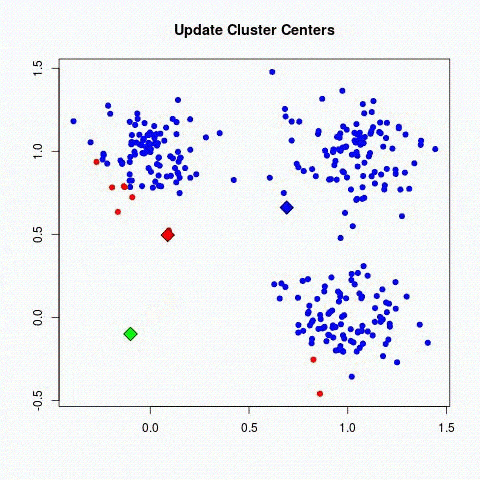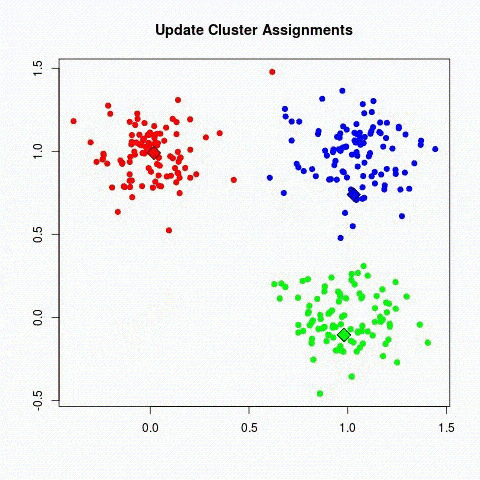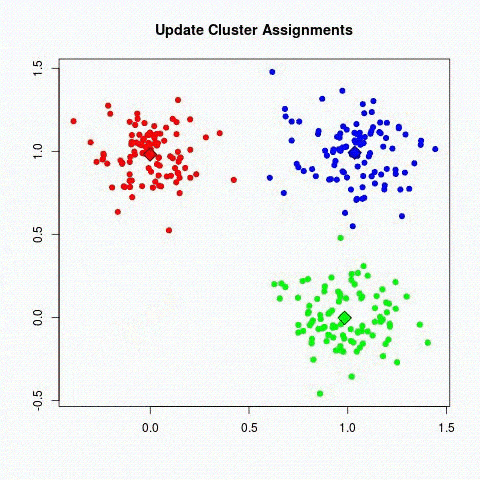

El Deep learning es una de las principales tecnologías del aprendizaje automático. Con el Deep Learning, hablamos de algoritmos que son capaces de imitar las acciones del cerebro humano mediante redes neuronales artificiales. Las redes se componen de docenas o incluso cientos de «capas» de neuronas, cada una de las cuales recibe e interpreta información de la capa anterior.
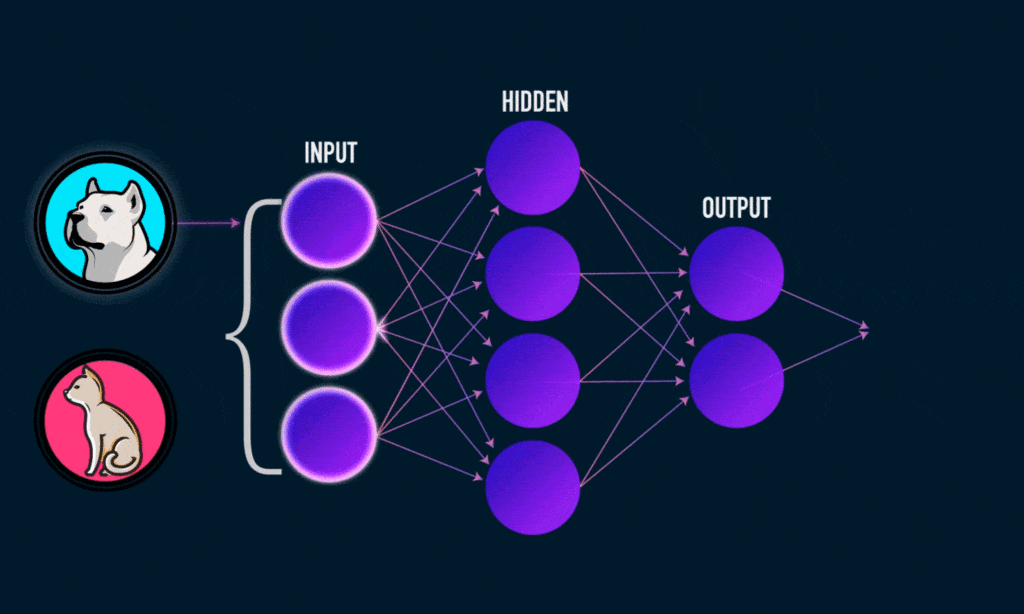
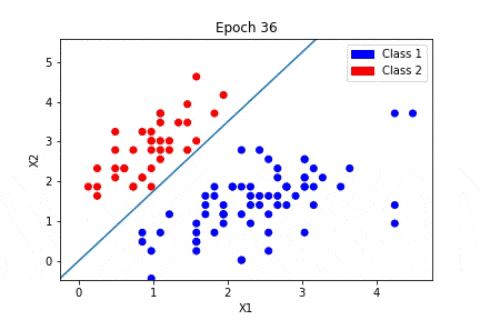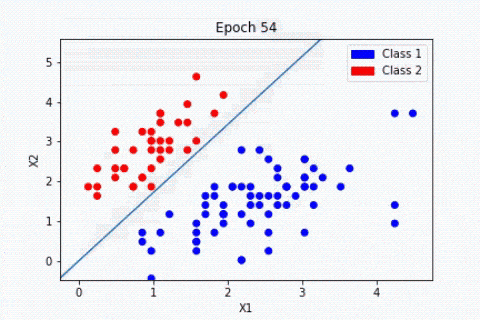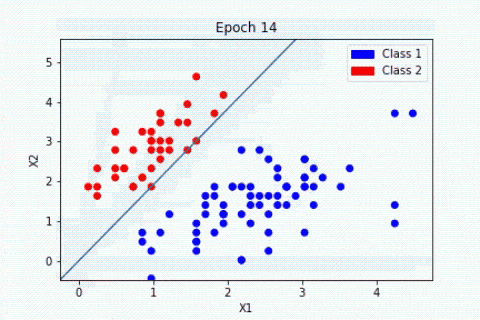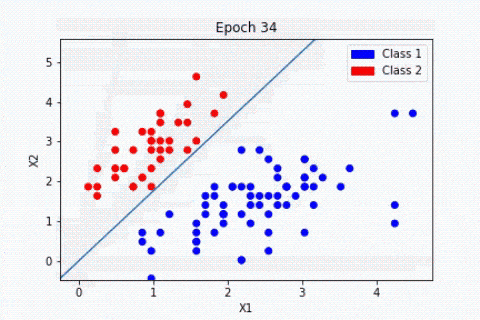
Cada neurona artificial, representada en la imagen anterior por un círculo, puede verse como un modelo lineal. Al interconectar las neuronas en una capa, transformamos nuestra red neuronal en un modelo no lineal muy complejo.
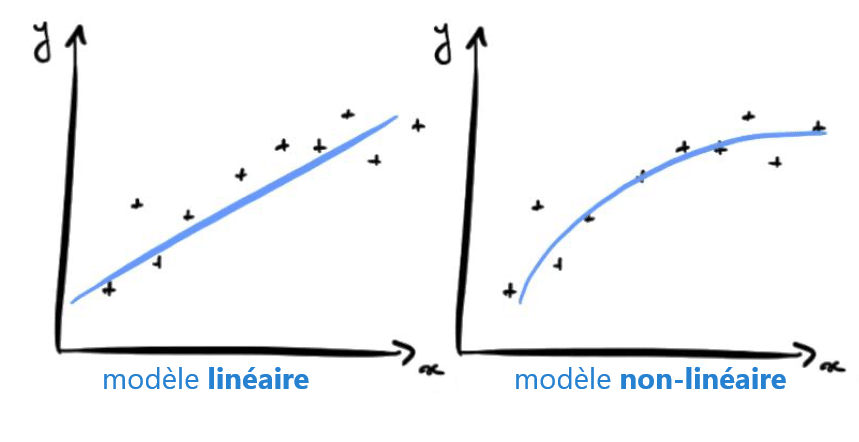
Para ilustrar el concepto, tomemos un problema de clasificación entre perro y gato a partir de imágenes. Durante el entrenamiento, el algoritmo ajustará los pesos de las neuronas para reducir la diferencia entre los resultados obtenidos y los esperados. El modelo podrá aprender a detectar triángulos en una imagen, ya que los gatos tienen las orejas mucho más triangulares que los perros.
Los modelos de aprendizaje profundo tienden a funcionar bien con grandes cantidades de datos, mientras que los modelos de aprendizaje automático más tradicionales dejan de mejorar después de un punto de saturación
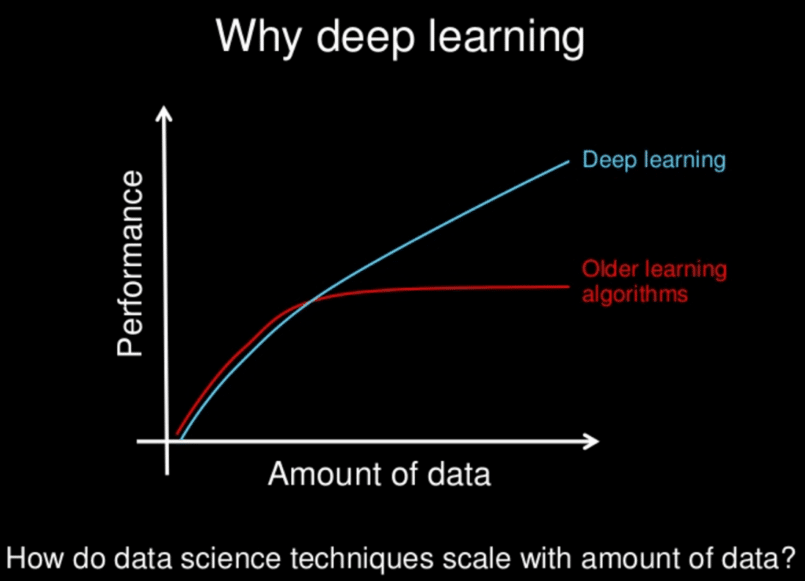
A lo largo de los años, con la aparición del big data y de componentes informáticos cada vez más potentes, los algoritmos de aprendizaje profundo que requieren mucha potencia y datos han superado a la mayoría de los demás métodos. Parecen estar preparadas para resolver muchos problemas: reconocer caras, ganar a jugadores de go o de póquer, permitir la conducción de coches autónomos o buscar células cancerígenas.
Casi todos los sectores se ven afectados por la IA. El aprendizaje automático y el aprendizaje profundo juegan un gran papel.
Ya sea usted un profesional de la medicina o un abogado, es posible que un día un modelo altamente autónomo le asista o incluso le sustituya.
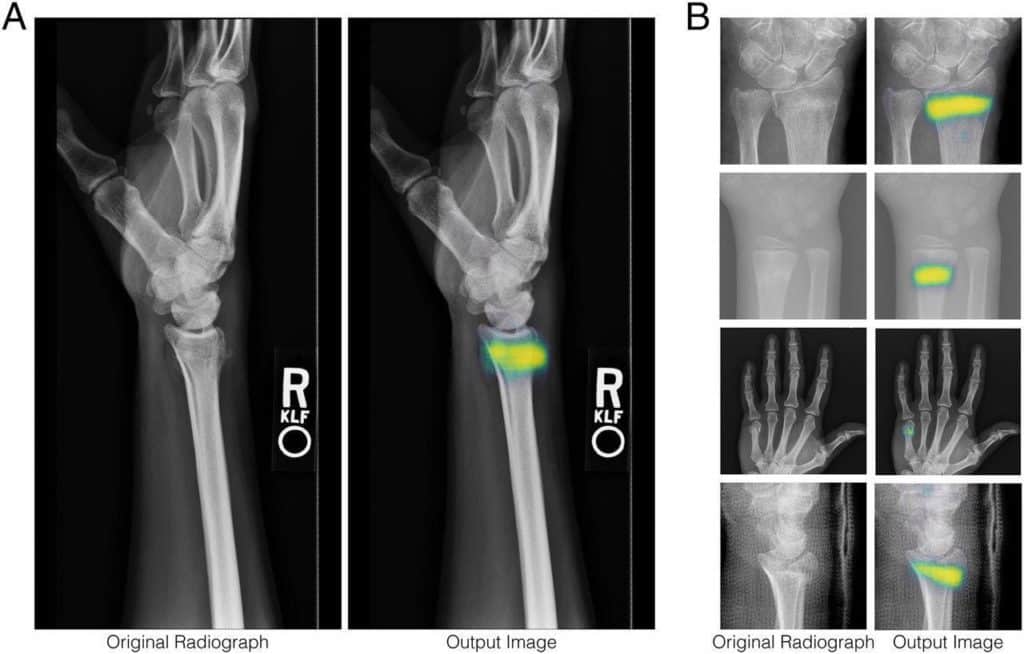
En el sector de la salud , ya existen aplicaciones para diagnosticar automáticamente a un paciente.
La industria del automóvil también se ve sacudida por la llegada de la conducción asistida.
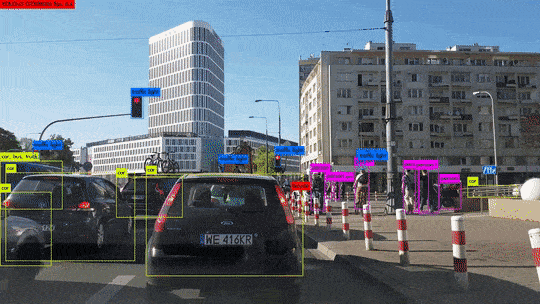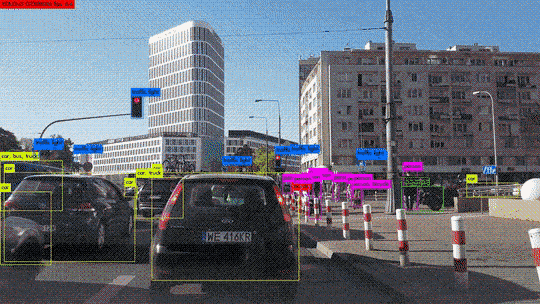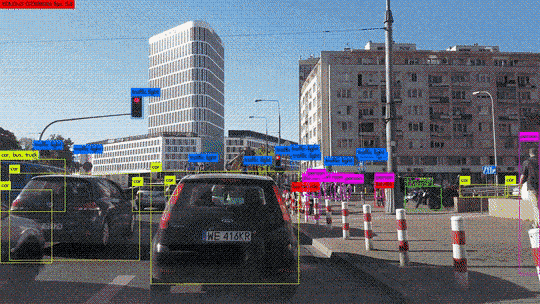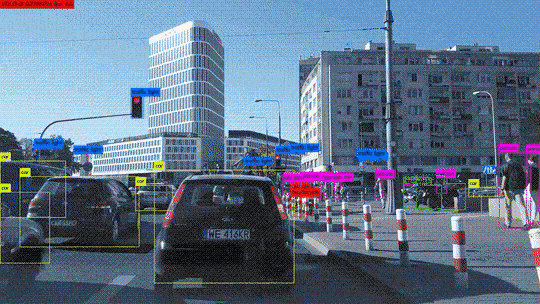
Hoy en día, el aprendizaje profundo es incluso capaz de «crear» cuadros por sí mismo. Esto se llama Transferencia de Estilo. Si está interesado en este tema, pronto estará disponible en nuestro blog un artículo enteramente dedicado a él.
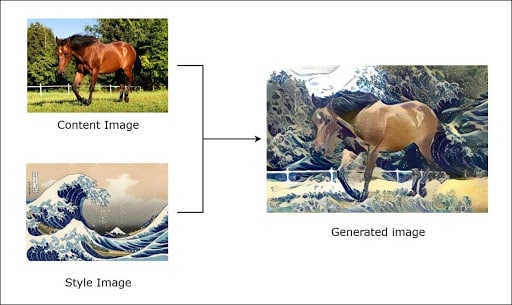
A continuación, le presentaremos las redes neuronales con un nuevo enfoque, ¡esperamos que le guste!