El deep learning fascina tanto como intimida. Entre ecuaciones, GPU y vocabulario esotérico, podrías pensar que se necesita un doctorado en matemáticas para entender su lógica. Sin embargo, el principio es simple: aprender por el ejemplo. Para verlo con tus propios ojos — literalmente — nada supera a TensorFlow Playground.
Esta pequeña herramienta accesible en línea permite manipular una red neuronal en tiempo real, observar las reacciones y, sobre todo, entender cómo aprende. Unos minutos son suficientes para transformar una idea abstracta en una experiencia concreta.
El deep learning en pocas líneas
Desde hace una década, el deep learning — o aprendizaje profundo — domina el reconocimiento de imágenes, la traducción automática y la síntesis de texto. La idea fundacional se remonta a los años 1950: imitar (rudimentariamente) el funcionamiento de las neuronas biológicas. Una neurona artificial recibe entradas numéricas, las pondera, añade eventualmente un sesgo y aplica una función de activación. Alineadas en capas sucesivas, estas neuronas transforman poco a poco los datos brutos en representaciones aptas para separar, predecir o generar.
¿Por qué “profundo”? Porque las redes modernas apilan decenas, incluso cientos de capas, cada una capturando una abstracción más sutil que la anterior: de aristas a patrones, de patrones a objetos, luego de objetos a la escena entera. Todo se entrena mediante un método de optimización — a menudo el descenso de gradiente — que ajusta los pesos para minimizar un error medido en una muestra de ejemplos anotados.
TensorFlow Playground: un laboratorio en el navegador
Abre TensorFlow Playground y, sin instalar nada, aparece una red mínima. A la izquierda, unos puntos de colores representan los datos; en el centro, unos círculos (las neuronas) conectados por flechas (los pesos); a la derecha, los hiper-parámetros modificables con un simple clic: tasa de aprendizaje, función de activación, regularización, tamaño de lote, etc. Cuando se pulsa en Train, cada iteración actualiza la frontera de decisión en tiempo real.
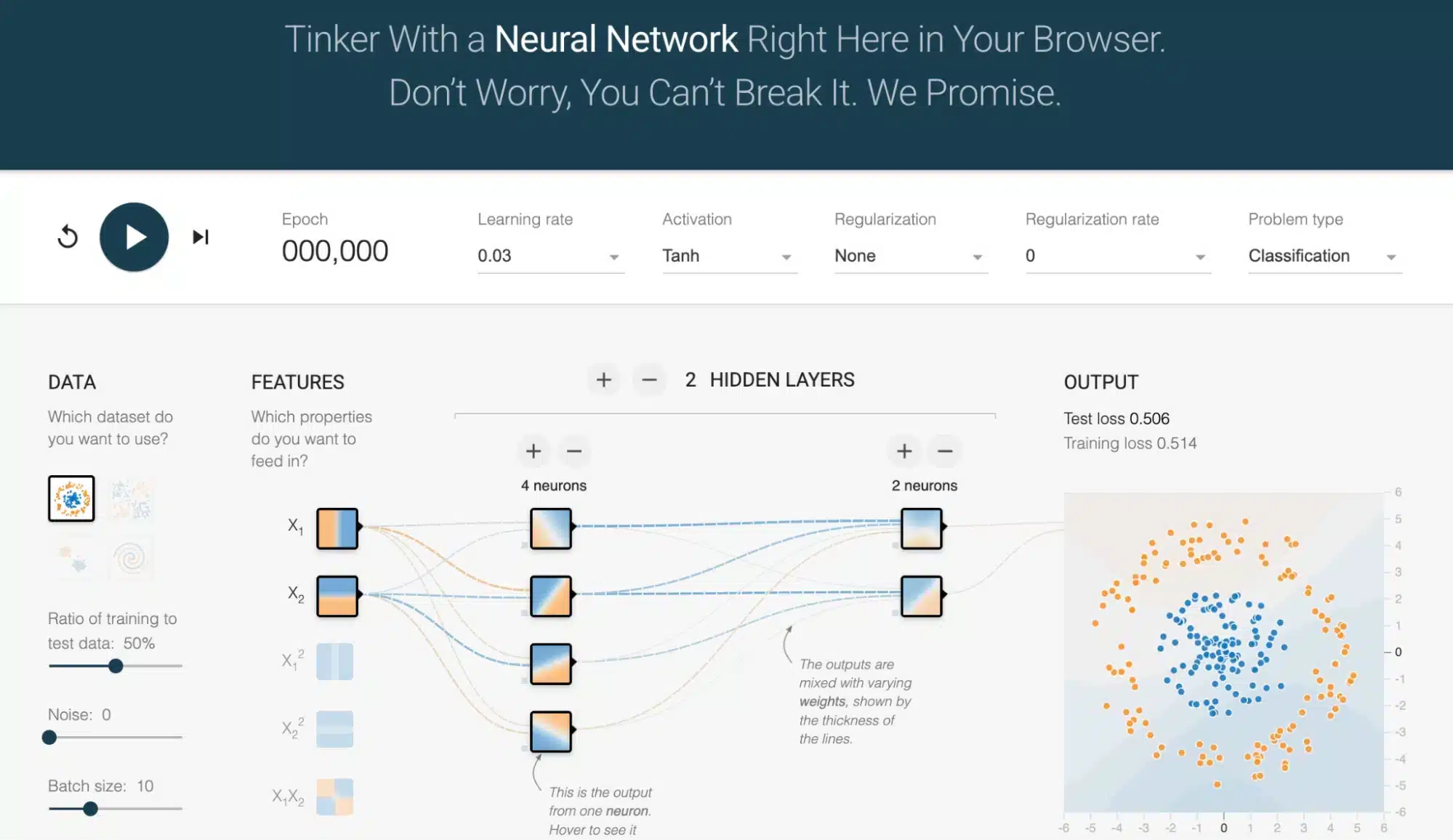
¿Por qué esta herramienta es tan poderosa para entender?
- Visualización instantánea: la frontera evoluciona ante tus ojos, ilustrando el descenso de gradiente mucho mejor que un gráfico estático.
- Seguridad: no hay riesgo de borrar un disco o de quemar un GPU.
- Fácil de compartir: todas las opciones están codificadas en la URL; basta con copiarla para compartir una configuración exacta.
Anatomía de una red desde Playground
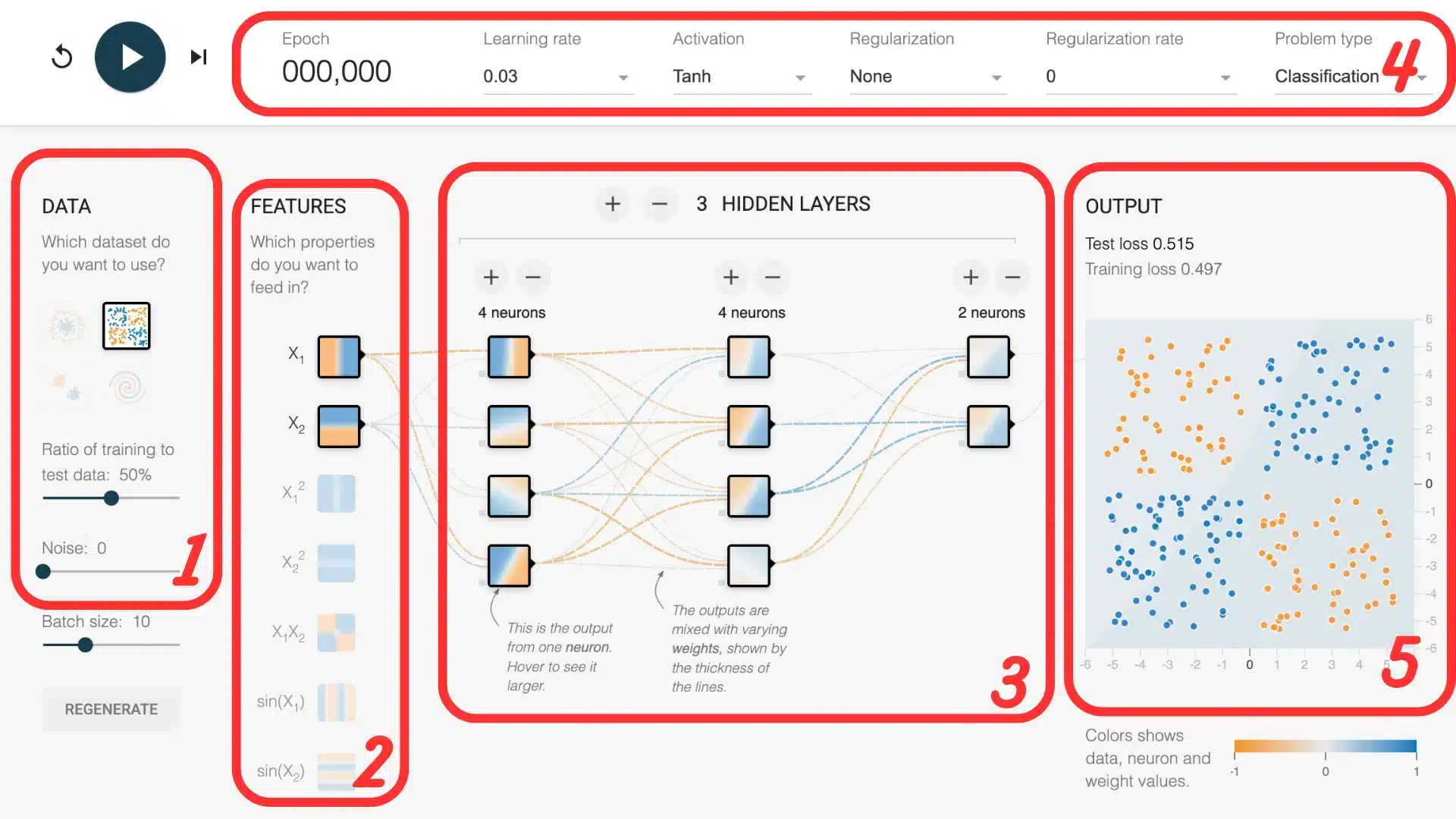
1. Los datasets
Playground ofrece cuatro datasets sintéticos: una nube linealmente separable, dos juegos no lineales (círculo y “lunas”), y la ineludible espiral apodada “el caracol”. Estos datos bidimensionales son lo suficientemente simples para caber en un gráfico, mientras que son suficientemente ricos para probar la potencia de una red profunda.
2. Las características (features)
Por defecto, solo las coordenadas x e y son usadas como entradas. Pero se pueden activar otras características derivadas: x², y², x·y, sin(x) o sin(y). Estas transformaciones permiten al modelo captar mejor patrones complejos. Por ejemplo, una nube en forma de círculo se vuelve mucho más fácil de separar si se añade x² + y² como información: la frontera de decisión puede entonces volverse circular, incluso con una red simple.
3. La arquitectura
Bajo los datos, un deslizador permite añadir capas y ajustar el número de neuronas. Una red sin capa oculta equivale a una regresión lineal: solo resuelve separaciones lineales. Con una capa de tres neuronas, el modelo ya captura curvas. Tres capas de ocho neuronas vencen al dataset en espiral, mientras que aumentar la profundidad aún más expone al sobre-aprendizaje — de ahí la importancia de la regularización.
4. Los hiper-parámetros
La tasa de aprendizaje gobierna la magnitud de las actualizaciones: demasiado grande, la pérdida oscila; demasiado pequeña, el modelo se estanca. Las funciones de activación — ReLU, tanh, sigmoid — inyectan la no linealidad necesaria; ReLU converge a menudo más rápido, tanh a veces se muestra más estable. La regularización L2 añade una penalización sobre los pesos para impedir que la red memorice el ruido.
5. Visualizar los resultados
Una vez iniciado el entrenamiento, hay dos elementos a vigilar: la frontera de decisión, que evoluciona visualmente en el plano, y la curva de pérdida en la esquina inferior derecha. La frontera muestra cómo la red aprende a separar las clases; cuanto más se ajusta a la forma de los datos, mejor entiende el modelo. La curva de pérdida, por su parte, indica si el error disminuye — una buena señal de que el aprendizaje progresa.
Dos desafíos a reproducir
Todos los parámetros de los ejercicios a continuación ya están codificados en los enlaces, solo hay que hacer clic para aterrizar en la configuración descrita.
Desafío 1: Primeros Pasos
Enlace: Desafío – Primeros Pasos
Inicia el entrenamiento: en pocos segundos, la frontera comienza a dibujar una separación en dos zonas bien definidas. Luego intenta reducir la tasa de aprendizaje y observa cómo el modelo aprende más lentamente. Cambia también la función de activación, por ejemplo, cambiando de tanh a ReLU: la velocidad y la forma de convergencia pueden variar, incluso si la tarea sigue siendo simple. Es un buen primer ejercicio para familiarizarse con los parámetros sin perderse en la complejidad.
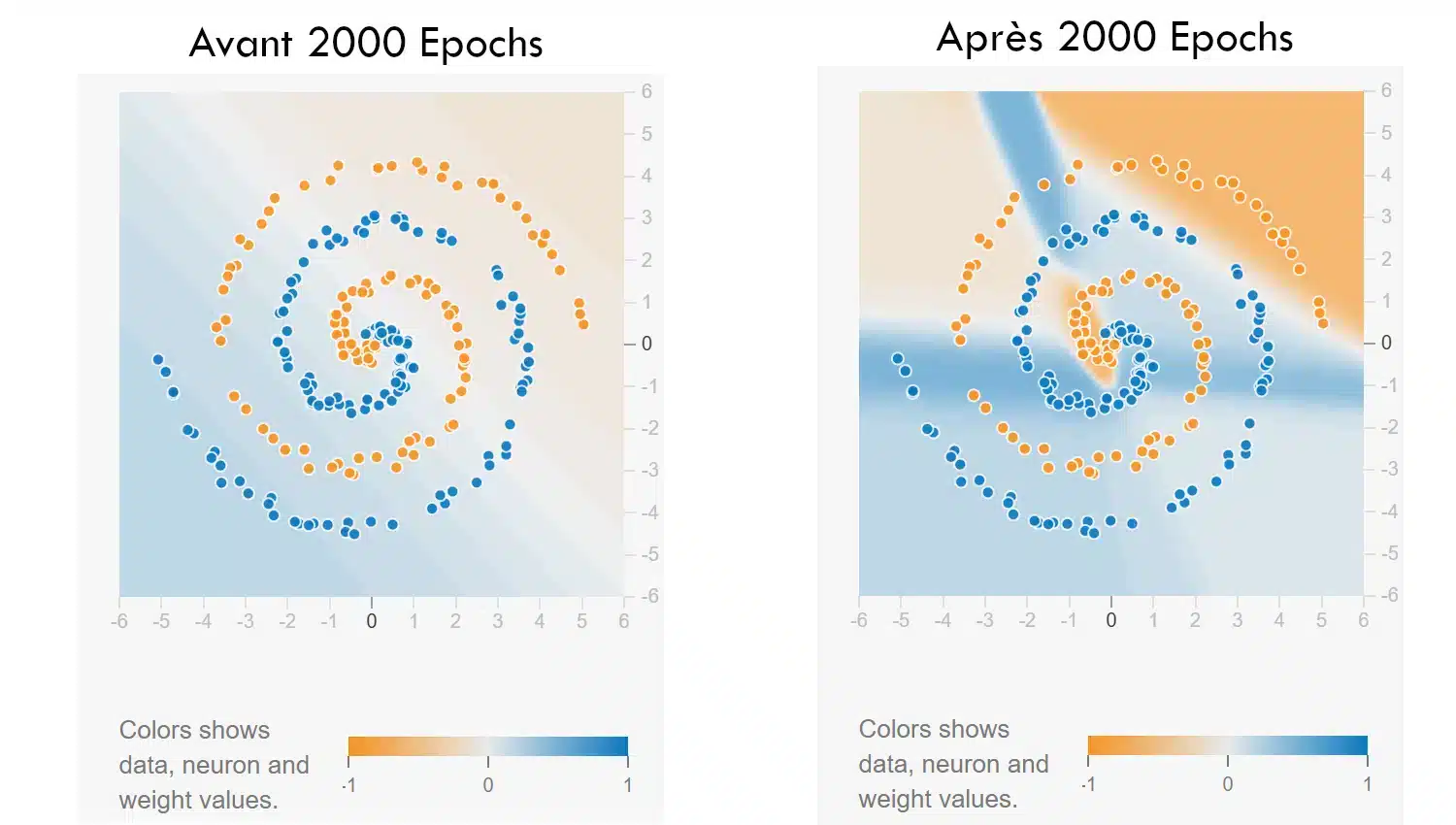
Desafío 2: Espiral
Enlace: Espiral
En este segundo ejercicio, la red debe aprender a clasificar un conjunto de datos en forma de espiral — un patrón conocido por ser difícil. La configuración de partida intencionalmente limitada (solo las features x e y) obliga a jugar con la arquitectura y los hiper-parámetros para tener éxito.
Inicia el entrenamiento: la frontera es caótica al principio. Depende de ti encontrar una combinación de capas, neuronas, función de activación, incluso regularización, que permita a la red seguir las curvas del patrón. Es una buena manera de ver hasta qué punto la profundidad o un pequeño cambio de parámetro pueden hacer toda la diferencia.
Dificultad extra: prohibido añadir características derivadas. Todo debe pasar por la estructura del modelo.
Lo que se aprende del Playground
Unos diez minutos pasados en Playground bastan para extraer tres enseñanzas fundamentales:
- La red aprende ajustando sus pesos para reducir el error; el descenso de gradiente no es más que un ciclo de ensayo y error automatizado.
- La no linealidad — ya sea a través de características o activaciones — es indispensable en cuanto una línea no es suficiente.
- Los hiper-parámetros son cruciales: una mala tasa de aprendizaje o una arquitectura sobredimensionada pueden arruinar el entrenamiento tan seguramente como un error en el código.
- La red aprende ajustando sus pesos para reducir el error; el descenso de gradiente no es más que un ciclo de ensayo y error automatizado.
Estas observaciones se aprecian, no se adivinan: la imagen en movimiento imprime en la mente lo que tres páginas de álgebra resumen menos claramente.
TensorFlow Playground no sirve para producir un modelo industrial, sino para visualizar el núcleo del deep learning: la transformación progresiva de un espacio de datos bajo el impacto de un aprendizaje iterativo. Reduciendo el tema a puntos de colores y a unos cuantos botones, la herramienta pone la mecánica al alcance de cualquiera que disponga de un navegador, de ahí, dar el paso hacia Keras o PyTorch se convierte en un simple cambio de interfaz. Entonces, abre la página, juega unos minutos, ajusta un parámetro, observa el resultado y siente cómo la teoría cobra vida. El aprendizaje automático, por complejo que sea, siempre comienza con un primer clic en Train.

