
Desde los años 2010, gracias a los progresos del Machine Learning y en particular del Deep Learning con las redes neuronales profundas, los errores son cada vez más raros. Hoy en día son incluso muy excepcionales. Sin embargo, esos modelos siguen equivocándose a veces, sin que los investigadores consigan desarrollar sistemas de defensa eficaces.
Los Adversial Examples o ejemplos contradictorios forman parte de esos inputs que el modelo va a clasificar mal. Frente a ello, se ha desarrollado una técnica de defensa, llamada Adversarial Training o entrenamiento contradictorio. Pero, ¿cómo funciona esa técnica de defensa? ¿Es realmente eficaz?
¿Qué es un Adversarial Example?
El Adversarial Training es una técnica que se ha desarrollado para proteger los modelos de Machine Learning de los Adversarial Examples. Recordemos brevemente en qué consisten los Adversarial Examples. Son inputs alterados muy ligeramente y con juicio (como una imagen, un texto, un sonido), de una manera imperceptible para el ser humano, pero que un modelo de Machine Learning va a clasificar mal.
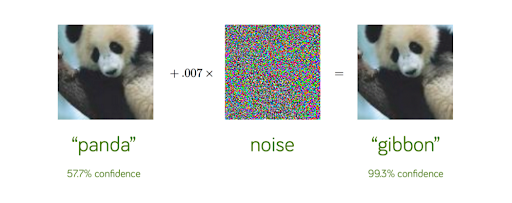
Lo que sorprende con esos ataques, es la garantía que tiene el modelo de su falsa predicción. El ejemplo de arriba lo muestra a la perfección : mientras el modelo admite una tasa de confianza de solo un 57,7 % para la predicción correcta, para la predicción incorrecta admite una tasa de confianza muy elevada, de un 99,3 %. Si quieres saber más sobre esos sorprendentes ataques, descubre el artículo dedicado :
Esos ataques son muy problemáticos. Por ejemplo, un artículo publicado en Science en 2019 por investigadores de Harvard y del MIT muestra cómo podrían ser vulnerables a los ataques adversos los sistemas de IA médicos. Por ese motivo es necesario defenderse. Ahí es cuando aparece el Adversarial Training. Se trata, junto con la “Defensive Distillation”, de la principal técnica para protegerse de esos ataques.
¿Cómo funciona el Adversarial Training?
¿Cómo funciona esa técnica? Se trata de volver a entrenar el modelo de Machine Learning con numerosos Adversarial Examples. En efecto, en la fase de entrenamiento de un modelo predictivo, si el modelo de Machine Learning clasifica mal el input, el algoritmo aprende de sus errores y reajusta sus parámetros con el fin de no volver a cometerlos.
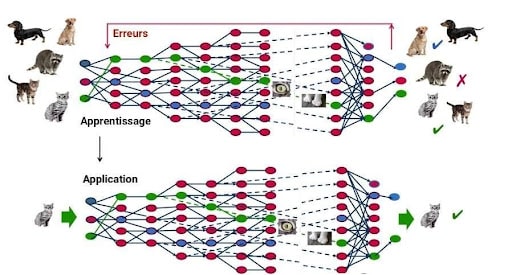
De este modo, después de haber entrenado una vez al modelo, sus desarrolladores van a generar numerosos Adversarial Examples. Van a enfrentar a su propio modelo a esos ejemplos contradictorios para que no cometa más errores.
Si ese método va a defender a los modelos de Machine Learning contra algunos Adversarial Examples, ¿permite generalizar la solidez del modelo a todos los Adversarial Examples? La respuesta es no. Ese enfoque es globalmente insuficiente para detener todos los ataques, ya que el abanico de ataques posibles es demasiado amplio y no se puede generar de antemano. De este modo, a menudo nos enfrentamos a una carrera entre los hackers que generan nuevos adversarial examples y los desarrolladores que se protegen de ellos lo más rápido posible.
De manera más general, es muy difícil proteger los modelos de los adversarial examples, porque es prácticamente imposible construir un modelo teórico a partir de la elaboración de esos ejemplos. Se trataría de resolver problemas de optimización particularmente complejos, y no disponemos de las herramientas teóricas necesarias.
Todas las estrategias probadas hasta ahora fracasan porque no se adaptan : pueden bloquear un tipo de ataque, pero dejan otra vulnerabilidad abierta a un atacante que conoce la defensa utilizada. El diseño de una defensa capaz de proteger contra un hacker potente y adaptable es un importante campo de investigación.
Para terminar, el Adversarial Training fracasa de manera global en la protección de los modelos de Machine Learning contra los Adversarial Attacks. Si tuviéramos que elegir un motivo, es porque esta técnica propone una defensa contra una serie de ataques particulares, sin conseguir desarrollar un método generalizado.
¿Quieres más información sobre los desafíos de la inteligencia artificial? ¿Ganas de dominar las técnicas de Deep Learning mencionadas en este artículo? Infórmate sobre nuestro curso de Machine Learning Engineer.
