Cuando el aprendizaje de un modelo singular tiene dificultades para ofrecer buenas predicciones, los métodos de aprendizaje conjunto aparecen a menudo como una solución de preferencia. Las técnicas de ensemble más conocidas, el Bagging (Bootstrap Aggregating) y el Boosting, tienen ambas como objetivo mejorar la precisión de las predicciones hechas durante el aprendizaje automático combinando los resultados de modelos individuales, con el fin de extraer predicciones finales más robustas y precisas.
Bagging: La Potencia del Aprendizaje Paralelo
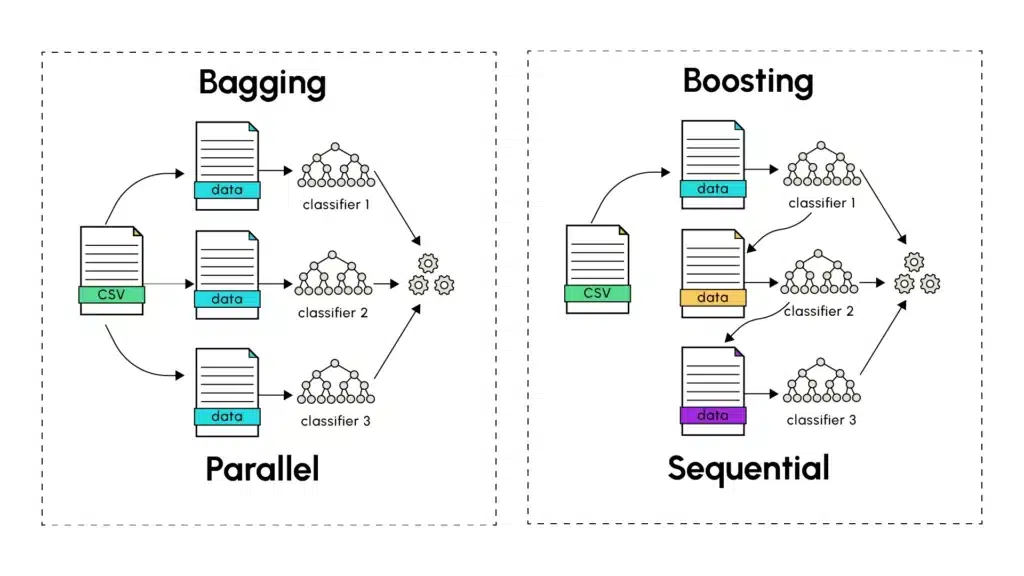
El Bagging, introducido por Leo Breiman en 1994, se basa en el entrenamiento de varias versiones de un predictor como un árbol de decisión, entrenado en paralelo de manera independiente. La primera etapa del bagging consiste en realizar un muestreo aleatorio con reemplazo (llamado bootstrapping) a partir del conjunto de datos de entrenamiento. A cada predictor se le asigna una muestra de entrenamiento sobre la cual emite predicciones. Estas posteriormente se combinan con las de todos los demás predictores distintos. Esta última etapa pasa por el cálculo del promedio de las predicciones hechas por los diferentes modelos (para predicciones cuantitativas) o mediante un método de votación (para predicciones categóricas), donde se retiene la predicción mayoritaria en términos de número de ocurrencia o de probabilidad.
La principal fortaleza del bagging reside en su capacidad para reducir la varianza sin aumentar el sesgo. Entrenando modelos sobre diferentes subconjuntos que tienen un cierto porcentaje de datos en común, cada modelo captura la diversidad presente en los conjuntos de datos aleatorios, mientras se obtienen resultados finales que generalizan bien en el conjunto de datos de prueba. Una analogía con el mundo real es la siguiente: pedir la opinión de varios expertos sobre un problema complejo. Cada experto, aunque competente, puede tener experiencias y perspectivas ligeramente diferentes. Promediar sus opiniones conduce a menudo a mejores decisiones que fiarse de un solo experto.
En resumen, la agregación de varios modelos de alta varianza se utiliza para capturar mejor las variaciones presentes en cada conjunto de entrenamiento. Este enfoque permite suavizar los errores de predicción individuales emitidos por los diferentes modelos, a fin de construir un modelo global de baja varianza combinando las predicciones de varios modelos de altas varianzas (overfitting). El Bagging ha sido especialmente popularizado a través de los Random Forests (bosques aleatorios) que son el resultado del entrenamiento en paralelo de árboles de decisiones, un tipo de modelo conocido por su alta varianza.
Boosting: Aprendizaje Secuencial para la Reducción de Errores
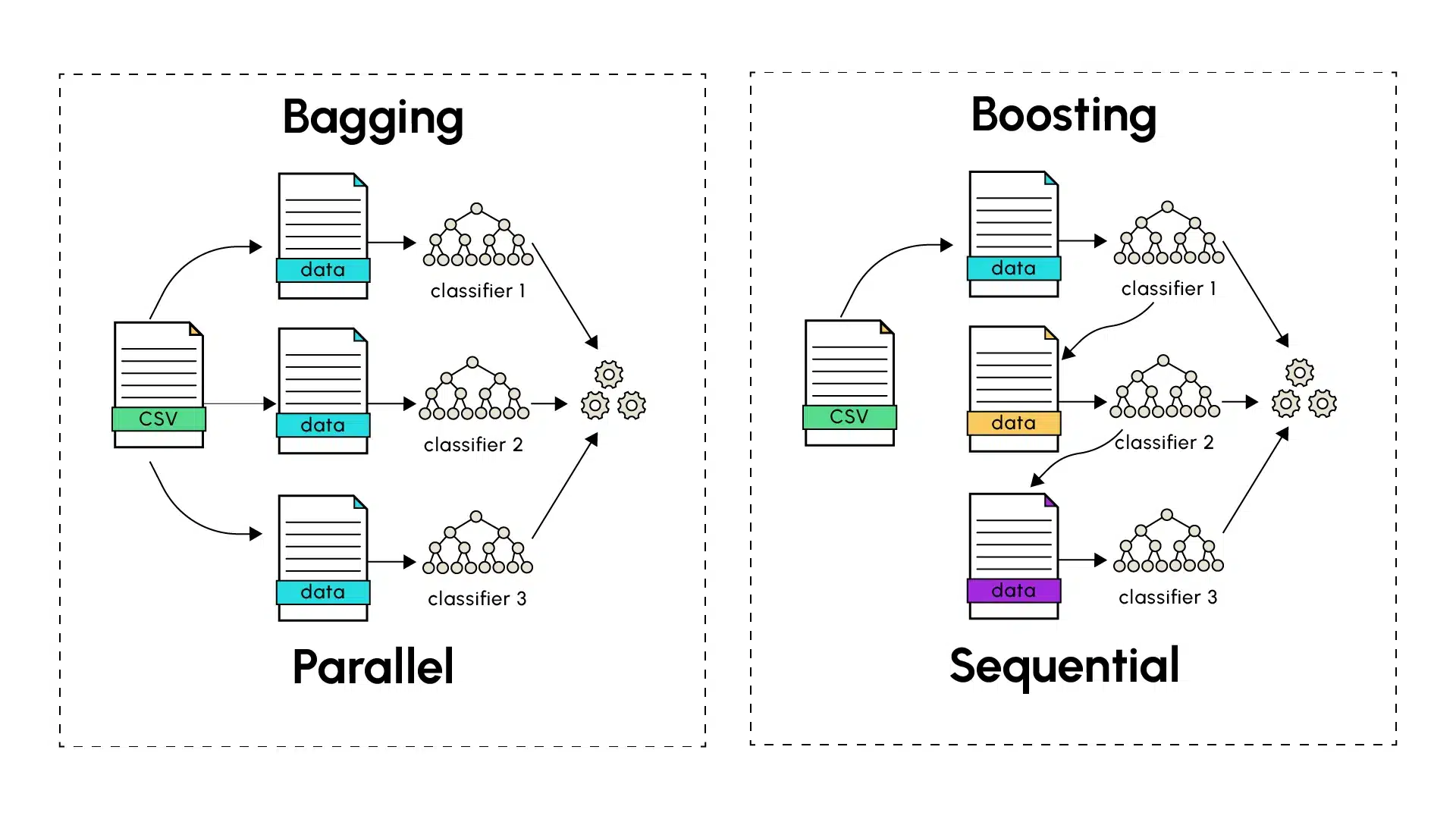
A diferencia del Bagging, el boosting sigue un método secuencial en la construcción del modelo final. Los predictores individuales se dicen débiles (underfitting) y se construyen en serie, uno tras otro. De este modo, cada modelo intenta corregir los errores del que le precede con el fin de disminuir el sesgo introducido por cada modelo débil. Los algoritmos de boosting incluyen notablemente AdaBoost (Adaptive Boosting), el Gradient Boosting y sus variantes XGBoost, LightGBM.

El proceso comienza con un aprendiz débil realizando predicciones sobre el conjunto de datos de entrenamiento. Las instancias mal predichas son entonces identificadas por el algoritmo de Boosting que les asigna pesos más elevados. El siguiente modelo se concentra más en estos casos previamente difíciles de identificar durante su entrenamiento para hacer sus predicciones más robustas. El proceso continúa y cada modelo subsiguiente intenta corregir los errores de los aprendices débiles anteriores, hasta que el último modelo de la serie sea entrenado. Al igual que para el Bagging, el número de modelos a entrenar para contribuir a las predicciones finales puede ser determinado empíricamente teniendo en cuenta la complejidad, el tiempo de entrenamiento y la precisión de las predicciones finales.
El Gradient Boosting lleva el concepto de Boosting más lejos utilizando un enfoque basado en la minimización de gradientes para ajustar las predicciones. Cada nuevo modelo se entrena para corregir los residuos de las predicciones anteriores siguiendo la dirección del gradiente de la función de pérdida, lo que permite una optimización más precisa y efectiva.
Diferencias Clave y Compromisos
1. Enfoque de Entrenamiento:
- Bagging: Los modelos se entrenan independientemente y en paralelo.
- Boosting: Los modelos se entrenan secuencialmente, cada uno aprendiendo de los errores anteriores.
2. Gestión de Errores:
- Bagging: Reduce la varianza mediante promediado.
- Boosting: Reduce tanto el sesgo como la varianza mediante aprendizaje secuencial.

3. Riesgo de Sobreaprendizaje:
- Bagging: Generalmente más resistente al sobreaprendizaje.
- Boosting: Más sensible al sobreaprendizaje, especialmente cuando intenta clasificar correctamente datos ruidosos.
4. Velocidad de Entrenamiento:
- Bagging: Más rápido, ya que los modelos pueden ser entrenados en paralelo.
- Boosting: Más lento, debido a su naturaleza secuencial.
Aplicaciones Prácticas
Ambas técnicas se destacan en diferentes escenarios. El Bagging suele funcionar bien cuando:
- Los modelos base son complejos (alta varianza).
- El conjunto de datos contiene mucho ruido.
- Hay capacidades de procesamiento paralelo disponibles.
- La interpretabilidad es importante.
El Boosting sobresale típicamente cuando:
- Los modelos base son simples (alto sesgo).
- Los datos son relativamente poco ruidosos.
- Alcanzar una máxima precisión en la predicción es crucial.
- Los recursos informáticos permiten un procesamiento secuencial.

Consideraciones para la Implementación
Durante la implementación de estas técnicas, varios factores merecen atención:
- Tamaño del Dataset: Los grandes conjuntos de datos suelen beneficiarse más del bagging
- Recursos Computacionales: El bagging puede aprovechar el procesamiento paralelo
- Configuración de Parámetros: El boosting generalmente requiere una configuración más precisa
- Interpretabilidad: Los modelos bagging tienden a ser más interpretables
Conclusión
El bagging y el boosting son ahora técnicas fundamentales en aprendizaje automático. Mientras que el bagging ofrece robustez y simplicidad mediante aprendizaje paralelo, el boosting proporciona potentes capacidades de mejora secuencial. Comprender sus fortalezas y debilidades respectivas permite a los practicantes elegir el enfoque apropiado para su caso de uso específico.
