
Las Restricted Boltzmann Machines (RBM) son un tipo de red de neuronas artificiales diseñadas para el aprendizaje no supervisado. Permiten aprender una distribución de probabilidad a partir de un conjunto de datos de entrada.
Inventadas por Geoffrey Hinton y Terry Sejnowski en 1985, y luego popularizadas en los años 2000, las RBM son particularmente adecuadas para la reducción de dimensiones, la extracción de características y la predicción de datos faltantes. A menudo se utilizan como bloques de construcción para arquitecturas más profundas como las Deep Belief Networks (DBN).
¿Cuál es el origen de las RBM?
Las RBM son una versión restringida de las Boltzmann Machines (BM), que son redes neuronales energéticas donde todas las neuronas están interconectadas. Sin embargo, en una RBM, las conexiones entre neuronas de una misma capa están prohibidas, lo que simplifica el cálculo y el entrenamiento del modelo. Esta restricción permite que las RBM aprendan representaciones latentes útiles en diversos campos como la visión por computadora, el procesamiento del lenguaje natural y la recomendación de contenidos.
¿Cómo funcionan las RBM?
Las Restricted Boltzmann Machines (RBM) funcionan según una arquitectura particular compuesta de dos capas de neuronas: una capa visible, que representa los datos de entrada, y una capa oculta, que extrae de ellos características relevantes. A diferencia de las redes neuronales clásicas, no poseen una capa de salida, ya que su objetivo es modelar una distribución de probabilidad de los datos. El aprendizaje se basa en el ajuste de los pesos que conectan estas dos capas, sin conexiones internas dentro de una misma capa.
1. Arquitectura de una RBM
Las RBM son grafos bipartitos simétricos donde cada neurona de la capa visible está conectada a cada neurona de la capa oculta, pero no existe ninguna conexión entre las neuronas de una misma capa. Cada conexión está asociada a un peso que se actualiza durante el aprendizaje.
2. Fase de aprendizaje
Durante la fase de aprendizaje, se utiliza una técnica llamada Contrastive Divergence (CD-k) para actualizar estos pesos. El proceso comienza con la presentación de un vector de entrada a la capa visible, que luego transmite la información a la capa oculta utilizando una función de activación sigmoidea. A partir de esta capa oculta se genera una nueva muestra para reconstruir una versión aproximada de la entrada inicial. La diferencia entre esta reconstrucción y la original permite evaluar un error que luego se utiliza para ajustar los pesos del modelo. Este proceso se repite de manera iterativa hasta que los ajustes de pesos se vuelvan insignificantes.

3. Función de energía y distribución de probabilidad
Las RBM se basan en una función de energía que determina la probabilidad de un estado dado. La probabilidad conjunta de las capas visibles y ocultas es dada por la distribución de Boltzmann.
La ecuación de la distribución de Boltzmann describe la probabilidad Ρ(Ε) de que una partícula ocupe un estado de energía Ε a una temperatura Τ. Se da por la siguiente fórmula:
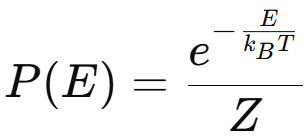
Donde:
- P(E) es la probabilidad de un estado con la energía E,
- E es la energía del estado,
- kB es la constante de Boltzmann,
- T es la temperatura en kelvins,
- Z es la función de partición.
Por lo tanto, cuanto menor es la energía de un estado, más probable es que ocurra.
4. Actualización de pesos
Los pesos de las conexiones entre las neuronas se actualizan minimizando el error de reconstrucción. La ecuación de actualización se da por:
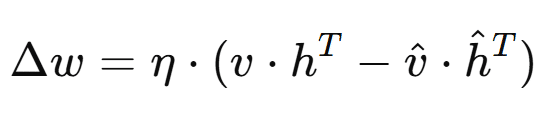
donde Δω es la actualización de los pesos, η es la tasa de aprendizaje, v y h son las activaciones de las neuronas visibles y ocultas, respectivamente, y v̂ y ĥ son las activaciones reconstruidas. Esta actualización ajusta los pesos para reducir el error entre las activaciones reales y reconstruidas.
¿Cuáles son las ventajas e inconvenientes de las RBM?
1. Ventajas
Las RBMs tienen varias ventajas. Sus principales beneficios son:
- Aprendizaje no supervisado: El hecho de que las RBMs operen con aprendizaje no supervisado las hace muy efectivas para extraer características a partir de datos brutos.
- Capacidad para modelar datos complejos y de alta dimensión: Son capaces de modelar distribuciones complejas y de alta dimensión.
- Usadas como bloques base para arquitecturas profundas (DBN): Constituyen un elemento fundamental en el diseño de arquitecturas más profundas, como las Deep Belief Networks.
2. Inconvenientes
- Dificultades para encontrar buenos hiperparámetros: La tasa de aprendizaje debe ajustarse adecuadamente. Un valor demasiado alto puede provocar oscilaciones e impedir la convergencia del modelo, mientras que una tasa demasiado baja ralentiza considerablemente el aprendizaje. Además, el número de neuronas ocultas influye directamente en la capacidad del modelo para aprender representaciones relevantes. Por último, un número insuficiente puede limitar la riqueza de las características extraídas, mientras que un número demasiado alto aumenta el riesgo de sobreajuste.
- El proceso de aprendizaje puede ser largo para grandes conjuntos de datos: Debido al gran número de iteraciones necesarias para ajustar los pesos de manera óptima. Esta restricción también se vuelve más problemática cuando se trabaja con grandes conjuntos de datos, donde cada actualización de pesos requiere muchas operaciones de cálculo.

¿Cómo se utilizan las RBM?
Las RBM han encontrado numerosas aplicaciones en diversos campos:
- Filtrado colaborativo: Utilizadas en sistemas de recomendación para predecir las preferencias de los usuarios.
- Visión por computadora: Reconocimiento de objetos, eliminación de ruido y reconstrucción de imágenes.
- Procesamiento del lenguaje natural: Modelado del lenguaje, clasificación de textos y análisis de sentimientos.
- Bioinformática: Predicción de estructuras proteicas, análisis de expresión génica.
- Finanzas: Predicción de precios de acciones, análisis de riesgos y detección de fraudes.
- Detección de anomalías: Identificación de transacciones fraudulentas, monitoreo de redes y diagnóstico médico.
Las aplicaciones de las RBM son variadas y cubren muchos campos. En los sistemas de recomendación, permiten optimizar el filtrado colaborativo al predecir las preferencias de los usuarios. En visión por computadora, se utilizan para el reconocimiento de objetos, la reducción de ruido de imágenes y la reconstrucción de datos visuales. En procesamiento del lenguaje natural, sirven para el modelado del lenguaje, el análisis de sentimientos o incluso la clasificación de textos. También encuentran su lugar en bioinformática, especialmente para el análisis de expresión génica y la predicción de estructuras proteicas, así como en finanzas para la predicción de precios de acciones o la detección de fraudes. Finalmente, se emplean en ciberseguridad y diagnóstico médico, donde facilitan la identificación de anomalías y la detección de comportamientos inusuales.
Conclusión
Las Restricted Boltzmann Machines son herramientas poderosas para el aprendizaje no supervisado y la extracción de características. Su capacidad para aprender representaciones útiles las hace indispensables para muchas aplicaciones en inteligencia artificial. Aunque presentan algunos desafíos en términos de entrenamiento y configuración, siguen siendo un componente clave en el diseño de modelos más avanzados como las Deep Belief Networks y otras arquitecturas neuronales profundas.
