¿Has echado de menos a Daniel? ¡Nosotros también! Hoy, nuestro experto en Data Science que acompaña a los alumnos a lo largo de su formación responde a esta pregunta: ¿Cómo funcionan las redes neuronales recurrentes?
Si eres un adepto a nuestro blog, ya sabrás qué es una red neuronal (si no es así, no dudes en leer este artículo antes), pero ¿qué aporta el adjetivo recurrente a este modelo? En este artículo vamos a ver cómo se han convertido las redes neuronales recurrentes, llamadas RNN, en un modelo clásico dentro del Deep Learning.
Puesta en situación
Sin embargo, si tomamos la figura 2, es evidente decir que la pelota va a seguir yendo hacia la derecha, gracias a las trayectorias anteriores, que traducen un movimiento hacia la derecha.
Hasta aquí todo parece lógico.
Al contrario que en la figura 1, tenemos más datos de entrenamiento adicionales, de ahí que seamos capaces de decidir el desplazamiento de la pelota.
De este modo, basta con darle a nuestra red neuronal los antiguos desplazamientos de la pelota y se acabó el estudio. Sin embargo, ¿cómo podemos elegir el número de neuronas de entrada? Una trayectoria puede ser compartida de la manera que queramos. Ya sea 10 o 100.

La pelota azul oscuro representa la posición actual de la pelota y las pelotas azul claro representan las antiguas trayectorias de nuestra pelota. De este modo adivinamos que la pelota se dirige hacia la derecha.
Ocultemos ese detalle por ahora, y fijemos el tamaño de nuestras muestras de entrada. Observemos la figura 3, ¿hacia dónde se va a dirigir la pelota?

Es cierto que el movimiento de la pelota es más complejo que en la figura 1, pero seguimos pudiendo decir que el siguiente desplazamiento de la pelota será hacia arriba. ¿Hará el modelo la misma predicción? Por desgracia no, ya que la red neuronal no piensa como nosotros. El modelo, al contrario que nosotros, no toma en cuenta el vínculo entre las entradas. Las entradas no son independientes las unas de las otras, por lo que debemos conservar ese vínculo entre ellas cuando entrenamos a nuestra red neuronal.
Tenemos que paliar 2 problemas :
- El tamaño de nuestras muestras de entrada que no es fijo.
- Los datos de entrada no están vinculados entre ellos.
Transición hacia la RNN
Volvamos a nuestro estudio de trayectoria de pelota. Vamos a considerar un plan, de ese modo la trayectoria de la pelota tendrá dos coordenadas, que llamaremos x^1,x^2 y queremos predecir la próxima ubicación de la pelota, la predicción de las futuras coordenadas será ŷ^1,ŷ^2. Vamos a representarlo con una red neuronal tradicional.
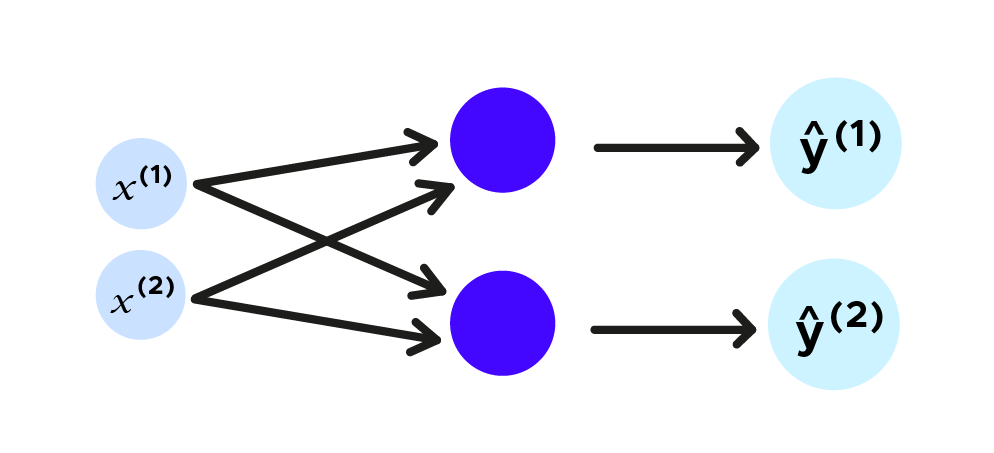
De manera sintética, si planteamos (x^1,x^2)=x_t y (ŷ^1,ŷ^2)=ŷ_t, podemos hacer el siguiente esquema de abajo:
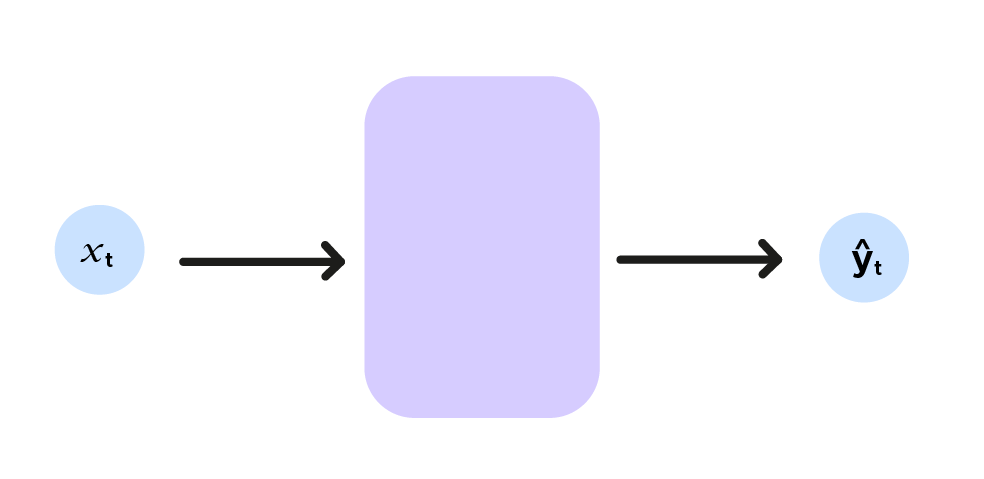
Aquí el índice t indica las coordenadas de la pelota en el momento t, representando la red neuronal con una función f, nos queda :
f(x_t)=ŷ_t (retomar el estilo matemático de la fórmula RNN (abajo en inglés))
Como hemos indicado antes, estudiamos el movimiento de la pelota de manera local. Queremos tener en cuenta varios instantes del movimiento de la pelota. Si no lo conseguimos con una red neuronal tradicional, con las RNN, todo cambia, porque se introduce el concepto de recurrencia. Efectivamente, observemos la figura de abajo. Añadimos una entrada h_t, llamada estado escondido (hidden state). Ese estado escondido encarna ŷ_t y se da como argumento para la próxima predicción además de la entrada x_t. Efectivamente hemos considerado un conjunto y por tanto, vinculamos las salidas y las entradas sin límite para nuestras muestras de entrada.
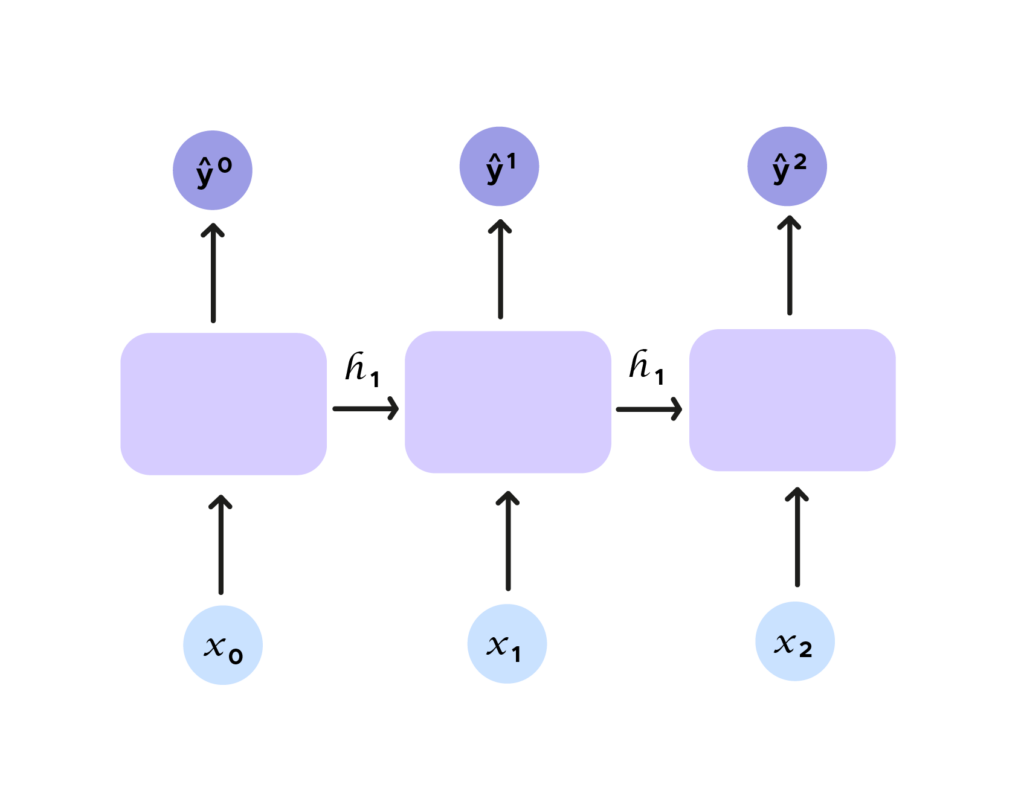
Si tratamos de simbolizarlo con una fórmula, obtenemos la siguiente ecuación :
Aquí se percibe bien el concepto de recurrencia. Para predecir el próximo término, necesitamos información previa proporcionada por h_{t-1}.
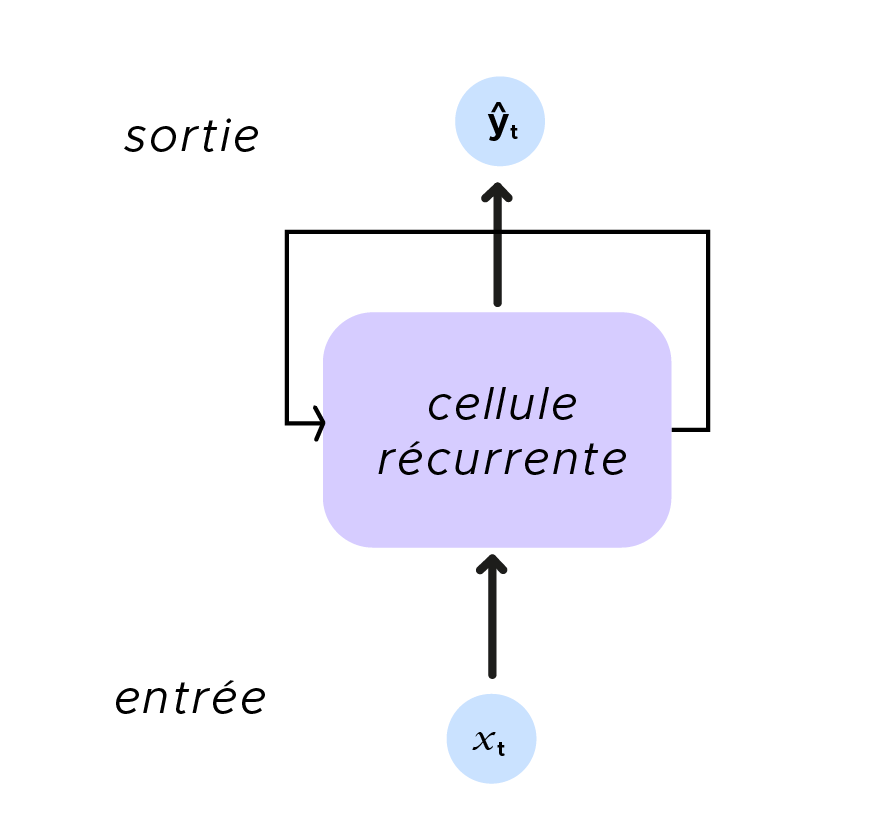
La recurrencia es aún más flagrante en este esquema recapitulativo.
Quelques applications des RNN

- one to many: la RNN recibe una única entrada y devuelve varias salidas,
el ejemplo clásico de este procedimiento es la leyenda de la imagen.
- many to one: tenemos varias entradas y solo hay una salida. Una ilustración de este modo es el análisis de sentimiento en textos. Esto permite identificar un sentimiento a partir de un grupo de palabras, determinar la palabra que falta para terminar la frase recibida en entrada. Para aprender más sobre el análisis de sentimientos, consulta este artículo.
- many to many: por ultimo, podemos tomar varias entradas y obtener varias salidas. No tenemos por qué tener el mismo número de neuronas de entrada y de salida. Aquí podemos citar, la traducción de textos, pero también ser ambiciosos y prever el fin de una obra musical a partir de su comienzo.
Perfecto, hemos visto el funcionamiento de una RNN y sus múltiples aplicaciones, pero ¿es perfecto? Por desgracia, presenta un gran inconveniente, llamado memoria a corto plazo, de la que veremos un ejemplo en TALN (Tratamiento automático del lenguaje natural).
¿Tiene la RNN memoria de pez?
Retomemos el caso de completa una frase.
Me gusta el sushi, me voy a comer a…
La RNN no es capaz de retener la palabra sushi para predecir Japón, ya que no ha retenido la palabra sushi. Para llegar a determinar Japón, es necesario que la RNN posea una memoria mejor. Para ello hay que conseguir que las neuronas sean más complejas. En particular, vamos a ver el caso de la LSTM (Long Short Term Memory). Además del estado escondido convencional h_t, vamos a añadir un segundo estado c_t. Aquí, h_t representa la memoria corta neuronal y c_t la memoria larga.
No vamos a entrar en las consideraciones técnicas de este esquema aterrador. Lo esencial es observar que tenemos una célula mucho más compleja, que nos permite solucionar el problema de memoria. Con la LSTM, vamos a pasar las h_t y c_t por puertas, 4 en total.
- La primera puerta permite eliminar la información inútil, es la forget gate.
- La segunda puerta, almacena la información nueva, la store gate.
- La tercera puerta actualiza la información que vamos a dar a la RNN con el resultado de la forget gate y la store gate, es la update gate.
- Y la última puerta (output gate), nos da y_t y h_t.
Este largo proceso permite controlar la información que conservamos y transmitimos a través del tiempo.
La RNN llega a saber qué hay que guardar y qué hay que olvidar, gracias a su aprendizaje. La LSTM (Long Short Term Memory) no es única, también podemos usar GRU (Gated Recurrent Unit), solo cambia la arquitectura de la célula.
Ahora resumamos lo que hemos visto. Las RNN son un tipo particular de redes neuronales que permiten tratar datos que no son independientes y que no tienen un tamaño fijo. No obstante. las RNN estándar están bastante limitadas con el problema de memoria corta, pero lo podemos resolver utilizando células más complejas como las LSTM o GRU.
Además, podemos hacer un paralelismo con otro sistema de red neuronal: las redes neuronales convolucionales (CNN en inglés). Efectivamente las CNN son conocidas por compartir la información espacial mientras que las RNN comparten la información temporal. Encontrarás más información sobre las CNN en este artículo. Y por último, si quieres poner en práctica las RNN, no dudes en apuntarte a nuestro curso de Data Scientist.
