
Si estudias datos y quieres extraer información de ellos, a menudo tendrás que procesarlos , modificarlos y, sobre todo, construir modelos capaces de determinar cuáles son los patrones de tus datos para un problema determinado. Muchas bibliotecas de código abierto permiten hacer esto hoy en día, pero la más conocida de ellas es seguramente Scikit-Learn.
¿Qué es Scikit-Learn?
Es una biblioteca de Python que proporciona acceso a versiones eficaces de muchos algoritmos comunes. También proporciona una API propia y estandarizada. Por tanto, una de las grandes ventajas de Scikit-Learn es que una vez que se entiende el uso básico y su sintaxis para un tipo de modelo, cambiar a un nuevo modelo o algoritmo es muy sencillo. La biblioteca no solo permite hacer el modelado, sino que también puede garantizar los pasos de preprocesamiento que veremos en el siguiente artículo.
Historia y objetivo
El proyecto fue lanzado inicialmente en 2007 por David Cournapeau y muy rápidamente muchos miembros de la comunidad científica de Python se involucraron en él. El proyecto avanzó rápidamente en el contexto de los trabajos sobre imágenes cerebrales funcionales realizados por el INRIA (Instituto Nacional de Investigación en Informática y Automática). Así, en 2009 se lanzó una primera versión de Scikit-Learn. Desde entonces, se han lanzado no menos de cuarenta versiones hasta llegar a la actual versión 0.24.1. Esta cifra dice mucho sobre la implicación, sobre el trabajo realizado en el proyecto por los desarrolladores de todo el mundo, cada versión mejora o añade nuevos métodos estadísticos innovadores. Desde el principio, el objetivo era ambicioso: facilitar el uso de la biblioteca en varias plataformas y dotarla de una documentación exhaustiva con ejemplos concretos sobre cada herramienta desarrollada. Hoy en día Scikit-Learn es una de las bibliotecas más populares en Github. Por los objetivos marcados al inicio del proyecto, uno de los puntos fuertes de Scikit-Learn es su flexibilidad y la facilidad con la que se puede utilizar en un gran número de problemas como por ejemplo la segmentación de clientes, la recomendación de productos, la detección de fraudes… Por último, es importante destacar que Scikit-Learn es un proyecto de código abierto disponible para todos bajo la licencia BSD. En la web de la biblioteca encontrarás documentación muy precisa de los métodos estadísticos disponibles con ejemplos para entenderlos, pero también casos prácticos para comparar los métodos entre sí y comprenderlos mejor.
Nos cheat sheets




La API de Scikit-Learn
Se ha construido siguiendo ciertos principios para que sea fácilmente aplicable a un gran número de dominios :
- Coherencia : Todos los objetos comparten una interfaz común extraída de un conjunto limitado de métodos, con una documentación coherente.
- Inspección : todos los valores de los parámetros especificados se exponen como atributos públicos.
- Jerarquía de objetos limitada : los algoritmos son los únicos que se representan mediante clases de Python; los conjuntos de datos se representan en formatos estándar (arrays de NumPy, DataFrames de Pandas, matrices dispersas de SciPy) y los nombres de los parámetros utilizan cadenas estándar de Python.
- Composición : muchas tareas de aprendizaje automático pueden expresarse como secuencias de algoritmos más fundamentales, y Scikit-Learn hace uso de esto siempre que sea posible.
- Valores predeterminados razonables : Cuando los modelos requieren parámetros especificados por el usuario, la biblioteca define un valor predeterminado adecuado. Estos principios se describen directamente en este documento que presenta los principios de la API de Scikit-Learn.
Estos 5 principios permiten en la práctica un uso sencillo y fluido de la biblioteca, incluso para perfiles que no tienen una sólida formación matemática.
Los fundamentos de Scikit-Learn
Como la API está estandarizada, sea cual sea el modelo que se vaya a utilizar, los pasos de modelado suelen ser los mismos :
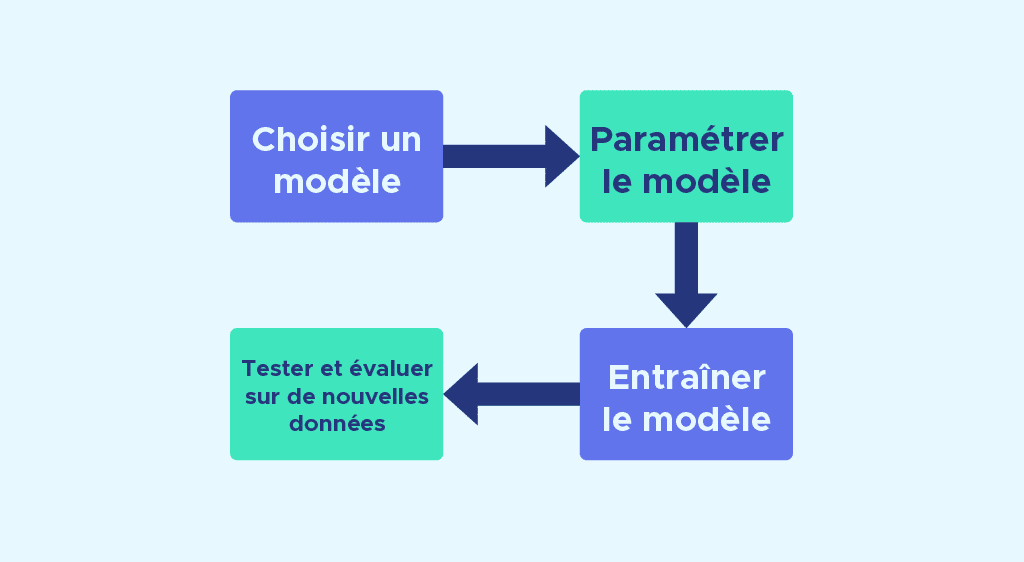
- Elegir un modelo importando la clase adecuada de Scikit-Learn.
- Establecer los parámetros del modelo. Si ya estás seguro de los parámetros que quieres utilizar, puedes rellenarlos a mano, de lo contrario, la biblioteca también ofrece técnicas como GridSearchCV para encontrar los parámetros óptimos.
- Entrenar el modelo en el conjunto de aprendizaje utilizando el método de ajuste.
- Probar el modelo con nuevos datos:
◦ Para el aprendizaje supervisado, utilizamos el método de predicción en los datos de prueba.
◦ Para el aprendizaje no supervisado, utilizamos los métodos de transformación o predicción.
Estos 4 pasos suelen ser comunes a la utilización de un gran número de modelos disponibles en la biblioteca, lo que permite, una vez que se ha comprendido la lógica de construcción de un modelo, poder utilizar otros modelos muy fácilmente.
Scikit-Learn : muchas posibilidades
En un artículo anterior hablamos de los 5 pasos cruciales de un proyecto de datos :
- Conocer los entresijos
- Recuperar y explorar los datos
- Preparar las bases de trabajo
- Seleccionar y entrenar un modelo
- Evaluar los resultados
En los últimos 3 pasos Scikit-Learn es una librería muy utilizada que te proporciona todas las herramientas necesarias :
- Para preparar los datos, la biblioteca ofrece un arsenal de métodos para:
◦ Separar los datos en conjuntos de prueba y de aprendizaje utilizando la función train_test_split.
◦ Codificar variables categóricas con métodos como OneHotEncoder.
◦ Normalizar los datos antes de modelizarlos con métodos como StandardScaler.
◦ Manejar los valores perdidos con métodos de imputación sencillos como SimpleImputer o métodos más avanzados como IterativeImputer.
◦ Realizar la selección de variables con, por ejemplo, SelectKBest.
◦ Reducir el tamaño de la serie de datos mediante métodos como el PCA o el TSNE.
Todos estos métodos permiten preparar los datos de manera eficiente, un paso crucial en un proyecto y Scikit-Learn ofrece todas las herramientas necesarias para conseguirlo. Hemos citado a modo de ejemplo una pequeña parte de los métodos disponibles, encontrarás muchos más en la web.
Aprendizaje supervisado y no supervisado en Scikit-Learn
- Para seleccionar y entrenar un modelo, Scikit-Learn cubre dos tipos principales de aprendizaje:
◦ Aprendizaje supervisado : existen muchos modelos, como la regresión logística, la regresión lineal, las regresiones lineales penalizadas, como Ridge, Lasso o la red elástica, los árboles de decisión, los métodos de conjunto, como los bosques aleatorios, o los métodos de boosting, que son fácilmente utilizables para tratar los problemas de clasificación y regresión.
◦ Aprendizaje no supervisado : También en este caso, el algoritmo k-means, la clasificación jerárquica ascendente, DBSCAN, las mezclas gaussianas son modelos disponibles y fácilmente utilizables.
Para la mayoría de estos modelos, especialmente en el aprendizaje supervisado, no conocemos de antemano los parámetros más adecuados para obtener el mejor rendimiento posible. Por eso, Scikit-Learn ofrece herramientas como GridSearchCV o RandomizedSearchCV que nos permiten determinar los parámetros más adecuados de nuestro modelo mediante validación cruzada. Estas dos funciones son muy utilizadas por la comunidad a la hora de modelar datos.
La gran variedad de modelos propuestos en una sola biblioteca hacen de Scikit-Learn un imprescindible para la fase de modelado de datos en un project data.
En cuanto a la evaluación de los resultados, Scikit-Learn vuelve a obtener un resultado excepcional. Cuenta con más de 40 métricas disponibles para analizar los resultados de tus modelos. Algunos como RMSE, MAE, MSE, r2_score permiten evaluar y comparar los resultados de los modelos de regresión. Otros como confusion_matrix, accuracy_score, classification_report permiten evaluar y comparar los resultados de los modelos de clasificación. Por último, también hay otros como silhouette_score para evaluar el rendimiento de los algoritmos de partición, como la clasificación jerárquica ascendente.
Es importante añadir que Scikit-Learn gracias a un método llamado pipeline permite instanciar los 3 últimos pasos de un proyecto en muy pocas líneas de código. Por supuesto, esta herramienta se utiliza después de probar diferentes modelos y determinar el mejor para nuestro problema.
Un poco de práctica
Veamos un ejemplo concreto para entender la capacidad de Scikit-Learn para ofrecernos herramientas estadísticas para llevar a cabo un proyecto de datos con un mínimo de líneas de código.
En este ejemplo, utilizaremos la serie de datos de precios de viviendas de Boston proporcionado por la biblioteca y trabajaremos con él. Esta serie de datos no contiene valores perdidos y nuestro objetivo será probar 3 modelos diferentes, encontrar para cada uno los parámetros óptimos y luego comparar las puntuaciones obtenidas para determinar el mejor.
Ejemplo de código de Gist :
El código puede dividirse en 4 pasos :
- Importación y escalamiento de datos mediante la clase StandardScaler.
- Selección de variables mediante la clase SelectKBest.
- Entrenamiento de 3 modelos diferentes y búsqueda de los mejores parámetros mediante la clase GridSearchCV.
- Comparación y elección del modelo óptimo.
Un último paso consiste en instanciar todos estos pasos en una sola línea de código con el mejor modelo utilizando la clase pipeline, y predecir y evaluar en el conjunto de prueba.
La librería Scikit-Learn ofrece en la actualidad un gran número de algoritmos con campos de aplicación en muchos sectores como la industria, los seguros, la comprensión de datos de clientes, etc. En Datascientest te enseñaremos a utilizar, entender, interpretar y evaluar un gran número de algoritmos de la librería en problemas concretos. Anímate a descubrir nuestros cursos.
