
U-NET es un modelo de red neuronal dedicado a tareas de visión artificial (Computer Vision) y más concretamente a problemas de segmentación semántica. Descubre todo lo que tienes que saber : presentación, funcionamiento, arquitectura, ventajas, cursos, etc.
La inteligencia artificial es una tecnología muy amplia con múltiples ramas. La visión artificial o visión por ordenador es una de estas subcategorías.
Se trata de un campo científico interdisciplinar que busca que los ordenadores puedan «comprender» las imágenes y los vídeos. El objetivo es automatizar las tareas que realiza el sistema visual humano.
Gracias al Deep Learning, en los últimos años se han podido conseguir grandes avances en el campo de la visión artificial. Ahora las máquinas son capaces de competir con la visión humana en algunas situaciones.
Las diferentes tareas de visión artificial
Existen diferentes tareas de visión artificial. Una de las aplicaciones más comunes es la clasificación de imágenes. Se trata de que el ordenador identifique el objeto principal de una imagen y le asigne una etiqueta para clasificarla.
También es posible dejar que el ordenador localice la ubicación del objeto en la imagen. Para ello, encierra el objeto en un «bounding box» (cuadro delimitador) que puede identificarse mediante parámetros digitales relacionados con los bordes de la imagen.
La clasificación de objetos se limita a un único objeto por imagen. La detección de objetos es aún más compleja y requiere que el ordenador detecte y localice los diferentes objetos dentro de una misma imagen.
La segmentación semántica consiste en etiquetar cada píxel de una imagen con una clase correspondiente a lo que se está representando. Esto también se conoce como «predicción densa», ya que hay que predecir cada píxel.
A diferencia de otras tareas de visión artificial, la segmentación semántica no se limita a producir etiquetas y cuadros delimitadores. Genera una imagen de alta resolución, en la que se clasifica cada píxel.
La segmentación de instancias va un paso más allá, y clasifica cada instancia de una misma clase por separado. Por ejemplo, si una imagen muestra tres perros, cada perro es una instancia de la clase «perro». Se clasificará a cada uno de ellos por separado, por ejemplo, utilizando diferentes colores.
A través de estas diferentes tareas, el ordenador «entiende» el contenido de las imágenes con un nivel de granularidad cada vez más preciso. En este número, nos centraremos en la tarea de segmentación semántica.
Las aplicaciones y casos de uso de la segmentación semántica
La segmentación semántica se usa en una gran variedad de aplicaciones. Los vehículos autónomos, por ejemplo, requieren percepción, planificación y ejecución en entornos en constante evolución.
También requieren una gran precisión, ya que la seguridad vial debe ser. Gracias a la segmentación semántica, los vehículos no tripulados pueden detectar los espacios libres en los carriles, la señalización de la carretera y las señales de tráfico.
Esta técnica de IA también se utiliza para el diagnóstico médico. Las máquinas pueden apoyar los análisis efectuados por los radiólogos y, de ese modo, reducir el tiempo necesario para realizar los diagnósticos.
Otro caso de uso es la cartografía por satélite, muy importante para controlar las zonas de deforestación o para la urbanización. La segmentación semántica permite distinguir los diferentes tipos de terreno de forma automatizada. La detección de edificios y carreteras también es muy útil para la gestión del tráfico o la planificación urbana.
Por último, los robots de agricultura de precisión pueden utilizar la segmentación semántica para distinguir las plantaciones de las malas hierbas. Eso les permite automatizar la eliminación de la maleza con menos herbicida.
¿Qué es U-NET?
Existen diferentes métodos para resolver los problemas de segmentación semántica. Los enfoques tradicionales consisten en detectar puntos, líneas o bordes. También es posible basarse en la morfología o reunir grupos de píxeles.
Las redes neuronales convolucionales de Deep Learning ahora se utilizan de manera generalizada. Pueden abordar problemas más complejos gracias a la segmentación de imágenes.
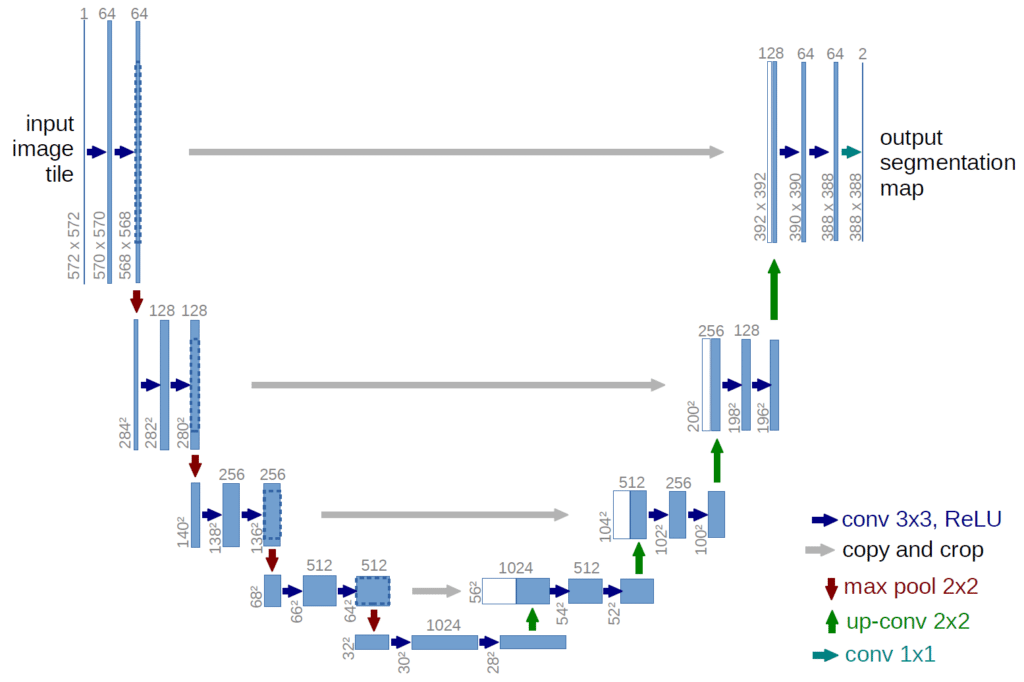
Una de las redes neuronales más utilizadas para la segmentación de imágenes es U-NET. Se trata de un modelo de red neuronal totalmente convolucional. Este modelo fue desarrollado originalmente por Olaf Ronneberger, Phillip Fischer y Thomas Brox en 2015 para la segmentación de imágenes médicas.
La arquitectura de U-NET consta de dos «vías». La primera es la de la contracción, también llamada codificador. Se utiliza para captar el contexto de una imagen.
En realidad, se trata de un conjunto de capas de convolución y de capas de «max pooling» que permiten crear un mapa de características de una imagen y reducir su tamaño para disminuir el número de parámetros de la red.
La segunda vía es la de la de expansión simétrica, también llamada descodificador. También permite una localización precisa mediante la convolución transpuesta
Las ventajas de U-NET
En el campo del Deep Learning, es necesario emplear grandes series de datos para entrenar modelos. Puede resultar difícil reunir esos volúmenes de datos para resolver un problema de clasificación de imágenes, en términos de tiempo, presupuesto y recursos de hardware.
El etiquetado de datos también requiere los conocimientos y la experiencia de varios desarrolladores e ingenieros. Este caso se da sobre todo en los campos de gran especialización, como en el diagnóstico médico.
U-NET permite solucionar esos problemas, ya que es eficaz incluso con una serie de datos limitada. También ofrece una mayor precisión que los modelos convencionales.
Una arquitectura de autocodificador clásico reduce el tamaño de la información de entrada y las capas siguientes. La descodificación empieza después, se aprende la representación lineal de características y el tamaño de la trama aumenta gradualmente. Al final de esta arquitectura, el tamaño de salida es igual al de entrada.
Esta arquitectura es ideal para preservar el tamaño inicial. El problema es que comprime la entrada de forma lineal, lo que impide la transmisión de todas las características.
Aquí es donde U-NET se impone con su arquitectura en forma de U. La deconvolución se realiza en el lado del decodificador, lo que permite evitar el problema del cuello de botella que se produce con una arquitectura de autocodificador y, por tanto, evita la pérdida de características.
¿Cómo aprender a utilizar U-NET?
Como la IA y la visión artificial cada vez se explotan más en todos los sectores, dominar el Deep Learning y varios modelos como U-NET es una competencia de valor y muy demandada.
Para adquirirla, puedes recurrir a los cursos de DataScientest. El Machine Learning y el Deep Learning son la parte central de nuestro itinerario de Data Scientist.
A través de este curso, también aprenderás la programación en Python, la DataViz, y el uso de bases de datos y herramientas de Big Data. Al finalizar el itinerario, tendrás todas las competencias necesarias para ejercer el perfil profesional en pleno auge de Data Scientist.
Nuestros cursos de formación profesional están diseñados para responder a las necesidades reales de las empresas y organizaciones. Se pueden hacer en BootCamp o en Formación Continua.
Ofrecemos un enfoque innovador de Blended Learning, que combina el aprendizaje presencial y a distancia. Al final del programa, recibirás un diploma certificado por la Universidad de La Sorbonne.
Entre nuestros antiguos alumnos, el 93 % encontró trabajo de inmediato. ¡No esperes más y descubre el curso de Data Scientist!
Ya sabes todo sobre U-NET. Descubre nuestro dosier completo sobre la Computer Vision y nuestro dosier más general sobre el Deep Learning.
