
De vuelta de Daniel, el personaje emblemático de nuestras formaciones que guía a nuestros alumnos hacia su diploma. Hoy les va a presentar un modelo muy utilizado en Visión por Computador : VGG.
Ya tuvimos ocasión, hace tiempo, de detallar la noción de Transfer Learning. Si se perdió nuestro artículo sobre el tema, le invito a leerlo de nuevo aquí. Lo que hay que tener en cuenta es que el transfer Learning (aprendizaje por transferencia) es la capacidad de utilizar los conocimientos ya adquiridos, desarrollados para resolver un problema determinado, para resolver un problema nuevo.
Un poco de historia
VGG es una red neuronal convolucional propuesta por K. Simonyan y A. Zisserman, de la Universidad de Oxford, y adquirió notoriedad al ganar el Desafío de Reconocimiento Visual a Gran Escala de ImageNet (ILSVRC) en 2014. El modelo alcanzó una precisión del 92,7% en Imagenet, que es una de las puntuaciones más altas logradas. Supone una mejora respecto a los modelos anteriores al proponer núcleos de convolución más pequeños (3×3) en las capas de convolución de lo que se había hecho anteriormente. El modelo se entrenó durante semanas utilizando tarjetas gráficas de última generación.
ImageNet
ImageNet es una enorme base de datos con más de 14 millones de imágenes etiquetadas en más de 1000 clases, a partir de 2014. En 2007, una investigadora llamada Fei-Fei Li empezó a trabajar en la idea de crear un conjunto de datos de este tipo. Aunque la modelización es un aspecto muy importante para un buen rendimiento, disponer de datos de alta calidad es igualmente importante para un buen aprendizaje. Los datos fueron recogidos y etiquetados desde la web por humanos. Por lo tanto, es de código abierto y no pertenece a ninguna empresa en particular.
La arquitectura
En realidad hay dos algoritmos disponibles : VGG16 y VGG19. En este artículo nos centraremos en la arquitectura del primero. Aunque ambas arquitecturas son muy similares y siguen la misma lógica, la VGG19 tiene un mayor número de capas de convolución.
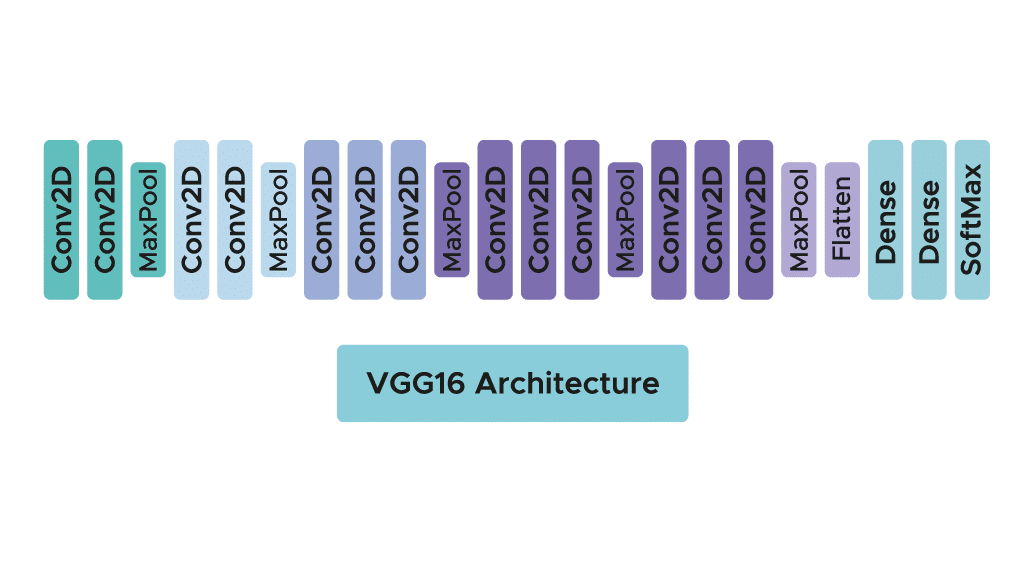
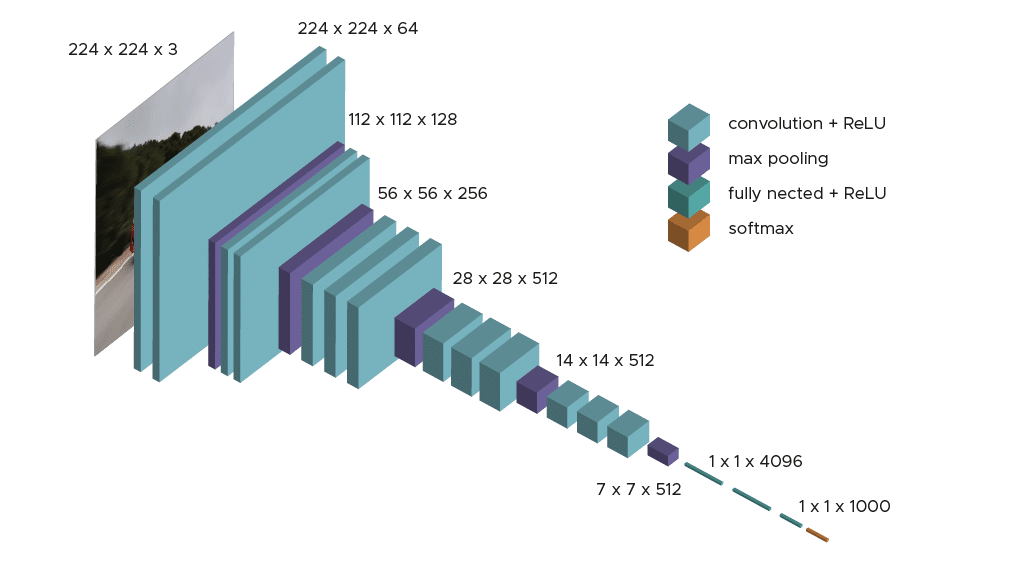
El modelo sólo requiere un pre-procesamiento específico que consiste en restar a cada píxel el valor RGB medio, calculado en el conjunto de entrenamiento.
Durante el entrenamiento del modelo, el input a la primera capa de convolución es una imagen RGB de tamaño 224 x 224. Para todas las capas de convolución, el núcleo de convolución es de tamaño 3×3: la dimensión más pequeña para capturar las nociones de arriba, abajo, izquierda/derecha y centro. Esta era una especificidad del modelo en el momento de su publicación. Hasta el VGG16, muchos modelos estaban orientados a núcleos de convolución de mayor dimensión (tamaño 11 o tamaño 5, por ejemplo). Recordemos que el objetivo de estas capas es filtrar la imagen manteniendo sólo la información discriminante, como las formas geométricas atípicas.
Estas capas de convolución van acompañadas de capas Max-Pooling, cada una de ellas de tamaño 2×2, para reducir el tamaño de los filtros durante el entrenamiento.
A la salida de las capas de convolución y agrupación, tenemos 3 capas de neuronas totalmente conectadas. Las dos primeras están compuestas por 4096 neuronas y la última por 1000 neuronas con una función de activación softmax para determinar la clase de imagen.
Como puede ver, la arquitectura es clara y sencilla de entender, lo que también es un punto fuerte de este modelo.
Resultados de ImageNet
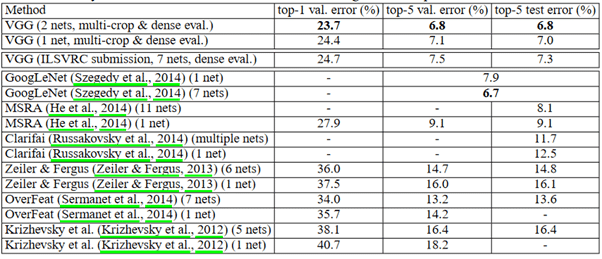
La figura anterior compara los resultados de diferentes modelos de 2014 o de años anteriores. Podemos ver que VGG da los mejores resultados tanto en el conjunto de validación como en el conjunto de prueba. También observamos que el modelo funciona mucho mejor que en las sesiones de 2012 y 2013.
¿Y el Transfer Learning?
Como ya hemos mencionado, el tiempo de entrenamiento de un modelo como el VGG puede ser muy largo, sobre todo si no se dispone de muchos recursos. Además, dado que se ha entrenado en ImageNet, puede ser interesante recuperar los pesos del modelo entrenado y, en particular, los filtros de las capas de convolución a partir del entrenamiento en ImageNet. Esto es lo que se hace en la práctica : recuperamos los pesos de las capas de convolución y simplemente entrenamos las 3 capas que añadimos
El principio sigue siendo el mismo : utilizar los conocimientos adquiridos en ImageNet para resolver un problema similar.
En particular, es posible recuperar directamente el modelo preentrenado de forma muy sencilla y aplicar el preprocesamiento específico solicitado por el modelo.
Un poco de práctica
En realidad, hay dos algoritmos disponibles : VGG16 y VGG19.
Gracias a la biblioteca keras de Tensorflow, es sencillo recuperar el modelo ya entrenado, por defecto, en ImageNet.
En primer lugar, tenemos que aplicar el mismo tratamiento específico que se aplicó cuando se entrenó el modelo. Además, añadimos un aumento de datos a los datos de entrenamiento para evitar el riesgo de sobreaprendizaje. También es importante comprobar que las imágenes de entrada son imágenes RGB de tamaño 224×224.
Entonces podemos recuperar los pesos optimizados de las capas de convolución y entrenar las 3 capas densas que añadimos y compilamos :
Tras el entrenamiento, si los resultados no son lo suficientemente buenos, es posible dejar de congelar las últimas capas de convolución y volver a entrenarlas para intentar obtener un mejor rendimiento. Una vez más, esto depende de los recursos disponibles, ya que este paso adicional puede llevar mucho tiempo.
Conclusión
El VGG es un conocido algoritmo de visión por ordenador que suele utilizarse mediante el aprendizaje por transferencia para evitar tener que volver a entrenarlo y resolver problemas similares en los que el VGG ya ha sido entrenado. Hay muchos otros algoritmos del mismo tipo que VGG como ResNet o Xception disponibles en la biblioteca Keras. Si quieres formarte en problemas de Deep Learning /Computer Vision, únete a nosotros en el Bootcamp o en la formación continua.
