Depuis les années 2010, grâce aux progrès du Machine Learning et notamment du Deep Learning avec les réseaux neuronaux profonds, les erreurs sont devenues de plus en plus rares. Aujourd’hui elles sont même très exceptionnelles. Cependant, ces modèles continuent parfois de se tromper, sans que les chercheurs réussissent à développer des systèmes de défense efficaces.
Les Adversarial Examples ou exemples contradictoires font partie de ces inputs que le modèle va mal classifier. Face à cela, une technique de défense, nommée Adversarial Training ou entraînement contradictoire, a été développée. Mais comment fonctionne cette technique de défense ? Est-elle vraiment efficace ?
Qu’est-ce qu’un Adversarial Example ?
Le Adversarial Training est une technique qui a été développée pour protéger les modèles de Machine Learning face aux Adversarial Examples. Rappelons brièvement en quoi consistent les Adversarial Examples. Ce sont des inputs très légèrement et judicieusement perturbés (comme une image, un texte, un son), d’une manière imperceptible pour l’humain, mais qui vont mal être classifiés par un modèle de machine learning.
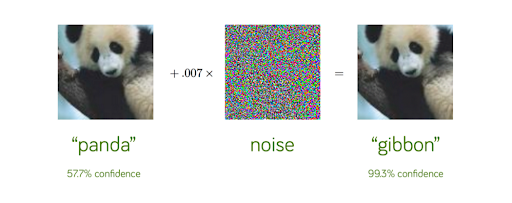
Ce qui est stupéfiant avec ces attaques, c’est l’assurance qu’a le modèle dans sa fausse prédiction. L’exemple ci-dessus le montre bien : alors que le modèle admet un taux de confiance de seulement 57,7% pour la prédiction qui est juste, il va admettre un taux de confiance très élevé de 99,3% pour la prédiction fausse. Si vous voulez en savoir plus sur ces attaques étonnantes allez voir l’article dédié : https://datascientest.com/adversarial-attack-quest-ce-que-cest-et-comment-proteger-lia-contre-cette-menace
Ces attaques sont très problématiques. Par exemple, un article publié dans Science en 2019 par des chercheurs de Harvard et du MIT montre comment les systèmes d’IA médicaux pourraient être vulnérables aux attaques adverses. C’est pourquoi il est nécessaire de se défendre. C’est là qu’intervient le Adversarial Training. Il s’agit, avec la « Defensive Distillation », de la principale technique pour se protéger de ces attaques.
Comment fonctionne l'Adversarial Training ?
Comment cette technique fonctionne-t-elle ? Il s’agit en fait de réentraîner le modèle de Machine Learning avec de nombreux Adversarial Examples. En effet, dans la phase d’entraînement d’un modèle prédictif, si l’input est mal classifié par le modèle de Machine Learning, l’algorithme apprend de ses erreurs et réajuste ses paramètres dans le but de ne plus les commettre.
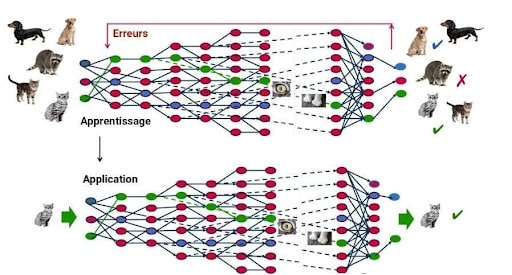
Ainsi, après avoir entraîné une première fois le modèle, les concepteurs du modèle vont générer de nombreux Adversarial Examples. Ils vont confronter leur propre modèle à ces exemples contradictoires pour qu’il ne commette plus ces erreurs.
Si cette méthode va défendre les modèles de Machine Learning contre certains Adversarial Examples, permet-elle de généraliser la robustesse du modèle à tous les Adversarial Examples ? La réponse est non. Cette approche est globalement insuffisante pour arrêter toutes les attaques, car l’éventail des attaques possibles est trop large et ne peut être généré à l’avance. Ainsi, il s’agit souvent d’une course entre les hackers génèrant de nouveaux adversarial examples, et les concepteurs s’en protègeant le plus vite possible.
De manière plus générale, il est très difficile de protéger les modèles contre les adversarial examples, parce qu’il est quasiment impossible de construire un modèle théorique de l’élaboration des ces exemples. Il s’agirait de résoudre des problèmes d’optimisation particulièrement complexes, et nous ne disposons pas des outils théoriques nécessaires.
Toutes les stratégies testées jusqu’à présent échouent parce qu’elles ne sont pas adaptatives : elles peuvent bloquer un type d’attaque, mais laissent une autre vulnérabilité ouverte à un attaquant qui connaît la défense utilisée. La conception d’une défense capable de protéger contre un hacker puissant et adaptatif est un domaine de recherche important.
Pour conclure, l’Adversarial Training échoue globalement à protéger les modèles de Machine Learning contre les Adversarial Attacks. S’il fallait retenir une raison, c’est parce que cette technique propose une défense contre une série d’attaques particulières, sans parvenir à dégager une méthode généralisée.
Vous voulez en savoir plus sur les défis de l’intelligence artificielle ? Envie de maîtriser les techniques de Deep Learning évoquées dans cet article ? Renseignez-vous sur notre formation de Machine Learning Engineer.








