De nos jours, nous remarquons une recrudescence d’intérêt et de progrès dans les nouvelles technologies liées à l’intelligence artificielle et notamment à l’utilisation des réseaux de neurones. Nous pouvons remarquer la puissance de ceux-ci dans la classification d’images et dans la classification d’objets. À première vue, nous pouvons penser que ces réseaux de neurones sont très puissants et infaillibles. Cet article vise à comprendre les enjeux et impacts que peuvent induire les adversarial examples.
Cependant, avec les développements rapides des techniques d’intelligence artificielle (IA) et de deep learning (DL), il est essentiel d’assurer la sécurité et la robustesse des algorithmes déployés. Il serait légitime de s’interroger et de s’intéresser quant aux éventuelles limites et à la performance liées à leurs utilisations.
Qu’est ce qu’un “adversarial example” ?
Un “adversarial example” ou exemple contradictoire est un exemple d’objet capable de tromper et déjouer un algorithme d’un réseau de neurones en lui faisant croire qu’il doit être classifié en tant que tel objet alors que ce n’est pas le cas.
Un “avdersarial example” est un ensemble de données correctement initialisées auxquelles on aurait ajouté une perturbation imperceptible par le réseau de neurones afin d’entraîner une mauvaise classification.
Quels sont les risques ?
Lorsque vous demandez à un humain de décrire comment il détecte un panda dans une image, il peut rechercher des caractéristiques physiques telles que des oreilles rondes, des tâches noires autour des yeux, le museau, la peau poilue. Il peut également fournir d’autres informations, comme le type d’habitat dans lequel il s’attend à voir le panda et le type de poses qu’il adopte.
Pour un réseau neuronal artificiel, tant que l’application des valeurs des pixels à l’équation donne la bonne réponse, il est convaincu que ce qu’il voit est bien un panda. En d’autres termes, en modifiant les valeurs des pixels de l’image de la bonne manière, vous pouvez tromper l’IA en lui faisant croire qu’elle ne voit pas un panda.
Dans le cas de l’adversarial example que nous allons voir dans la suite de l’article, les chercheurs en IA ont ajouté une couche de bruit à l’image. Ce bruit est à peine perceptible par l’œil humain. Mais lorsque les nouveaux numéros de pixels passent par le réseau neuronal, ils produisent le résultat d’un gibbon alors qu’il s’agit d’un panda.
Les exemples contradictoires rendent les modèles d’apprentissage automatique vulnérables aux attaques, comme dans les scénarios suivants :
- Une voiture autonome percute une autre voiture parce qu’elle ignore un panneau stop.
- Quelqu’un avait placé une image sur le panneau, qui ressemble à un panneau de stop pour les humains, mais qui a été conçue pour ressembler à un panneau d’interdiction de stationnement pour le logiciel de reconnaissance des panneaux de la voiture.
- Un détecteur de spam ne parvient pas à classer un courriel comme spam. Le courrier indésirable a été conçu pour ressembler à un courriel normal, mais avec l’intention de tromper le destinataire.
- Un scanner alimenté par l’apprentissage automatique scanne les valises à la recherche d’armes à l’aéroport. Un couteau a été mis au point pour éviter la détection en faisant croire au système qu’il s’agit d’un parapluie.
- Une IA automatisée qui ne détecte pas de maladie (une radiologie par exemple) alors que celle-ci correspond en réalité à une maladie grave.
Prenons maintenant quelques exemples concrets qui ont pu tromper des réseaux de neurones.
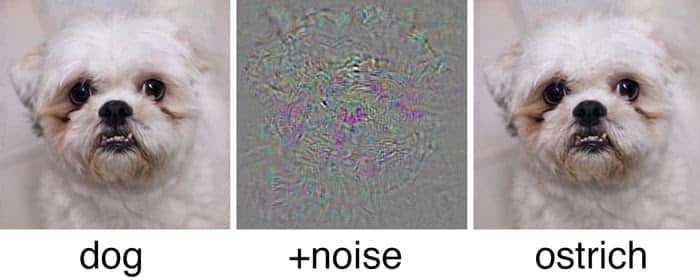
Dans l’exemple ci-dessous, nous voyons qu’avec une légère perturbation invisible à l’œil nu, il a été possible de tromper le réseaux de neurones et qui a classifié une photo de chien en autruche.
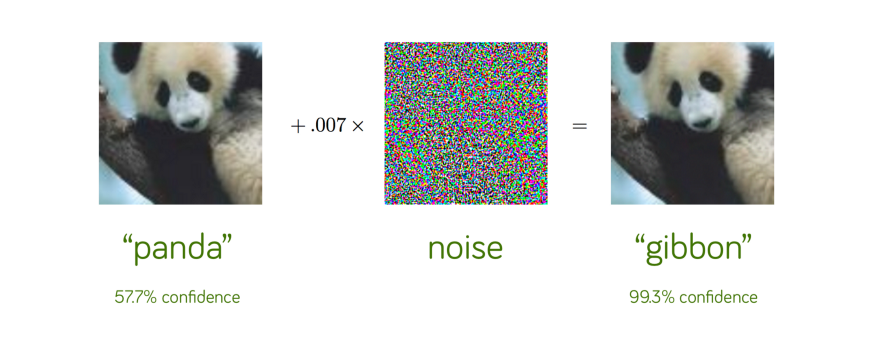
Prenons un autre exemple de classification d’images sur les pandas qu’un réseau de neurones reconnaît correctement comme un panda avec un taux de confiance de 57,7 %.
Si on ajoute un peu de perturbation soigneusement construite, le même réseau de neurones classe maintenant l’image comme étant un gibbon avec une confiance de 99,3 % !
Il s’agit clairement d’une illusion d’optique, mais seulement pour le réseau de neurones. Nous pouvons clairement affirmer que ces deux images correspondent bien à des pandas. En fait, nous ne pouvons même pas percevoir qu’un peu de perturbation a été ajoutée à l’image originale de gauche pour construire l’adversarial example à droite !
Dans l’exemple suivant, on peut voir l’impact que cela peut avoir dans la vie quotidienne sur des voitures autonomes qui détectent mal un panneau de signalisation.

Dans le cas ci-dessus, la perturbation perceptible par l’œil humain n’a pas été détectée par le réseau de neurones. Le panneau stop de droite ci-dessus a été classifié comme étant une limitation de vitesse à 45 km/h. Nous pouvons donc encore voir les enjeux et les limites que peuvent avoir les réseaux de neurones dans la classification d’images
Comment sont créés les “adversarial examples” ?
Tout d’abord, il est nécessaire de distinguer les attaques ciblées et non ciblées.
Une attaque non ciblée est tout simplement une attaque qui a pour but d’induire une mauvaise classification peu importe le résultat de cette classification. Ce qui importe est seulement la mauvaise classification de l’objet par le réseau de neurones.
Une attaque ciblée est, au contraire, une attaque qui a pour but d’induire une mauvaise classification dans une catégorie précise.
Par exemple, une attaque non ciblée sur une image d’un chien serait d’avoir une classification autre que celle d’un chien par notre réseau de neurones. Par contre, une attaque ciblée sur une image de chien serait d’induire notre réseau de neurones à classifier le chien en autruche par exemple mais pas en chat.
Il existe plusieurs méthodes pour construire les adversarial examples. Parmi celles-ci, il y a celles utilisées par les cyberattaques notamment le data poisoning (ou empoisonnement de données), les GANs (réseaux antagonistes génératifs) ou encore la manipulation des robots.
Comment se protéger des adversarial examples ?
Il existe plusieurs moyens de se défendre comme par exemple en utilisant l’adversarial training (ou entraînement contradictoire).
C’est la façon la plus simple et la plus naturelle de se défendre.
Cette défense consiste à se faire passer pour un attaquant en générant un certain nombre d’adversarial examples contre notre réseau de neurones puis à entraîner notre réseau de neurones sur ces données générées.
Cette méthode aide à généraliser notre modèle mais n’est pas encore en mesure d’obtenir un niveau de robustesse conséquent. En effet, les attaquants pourraient toujours trouver une perturbation plus petite pour tromper le réseau de neurones. Cela se résumerait donc à une partie de jeu où les attaquants et les défenseurs essaient de se surpasser les uns les autres.
Il existe également un autre type de défense nommée la distillation défensive. Cette défense consiste à créer un second modèle dont la surface sera lissée dans les directions que l’attaque souhaitera attaquer (c’est-à-dire que ce modèle agira comme un filtre supplémentaire pour détecter des anomalies), ce qui rendra difficile pour l’attaquant de détecter les modifications d’entrées adverses qui conduiraient à une mauvaise classification. Le second modèle serait une sorte de barrage aux attaques et capable de détecter des modifications liées à des attaques adverses.
Cependant, c’est un domaine de recherche encore récent. Nous n’avons pas complètement réussi à aboutir à une solution fiable et optimale. De nouvelles attaques sont souvent créées pour contourner les nouvelles défenses, ce qui explique ce travail de recherche continu.
Conclusion
Les adversarial examples montrent que de nombreux algorithmes modernes d’apprentissage automatique peuvent être brisés de manière surprenante. Ces échecs de l’apprentissage automatique montrent que même des algorithmes simples peuvent se comporter très différemment de ce que leurs concepteurs ont prévu. Les Data Scientist sont donc encouragés à s’impliquer et à concevoir des méthodes pour prévenir les exemples contradictoires, afin de combler le fossé entre les intentions des concepteurs et le comportement des algorithmes.
Envie de maîtriser les techniques de Deep Learning évoquées dans cet article ? Renseignez-vous sur notre formation de Data Scientist.









