

Quel est le point commun entre ces trois personnes ? Aucune n’existe dans la vie réelle et chacune de ces photos a été générée par ce site. Mais comment ce site peut réussir à générer des personnes aussi photoréalistes et diverses ?
Grâce à l’algorithme StyleGAN2 développé par une équipe de chercheurs de NVIDIA ! Cet algorithme encore très récent (Février 2019) se base sur une première version publiée par l’équipe en 2018 et se base elle-même sur l’architecture GAN.
Qu’est ce qu’un GAN ?
Un GAN (Generative Adversarial Network) ou réseau adverse génératif est un algorithme d’apprentissage non supervisé très efficace et répandu dans certains problèmes de computer vision.
C’est en particulier ce type d’algorithme de machine learning qui est utilisé pour réaliser les deepfakes que nous avons abordé dans l’un de nos articles précédents.
Concrètement un GAN ce sont deux réseaux de neurones qui s’entraînent en simultané l’un contre l’autre pour créer des fausses images.
Le premier est le générateur (G), il génère des fausses images de visage à partir d’un vecteur de bruit aléatoire (z). Cela permet à l’algorithme de générer à chaque nouvelle itération un visage différent.
Le discriminateur (D) quant à lui apprend à distinguer les images fausses créées par le générateur d’images de la vie réelle. En pratique c’est donc un classificateur.
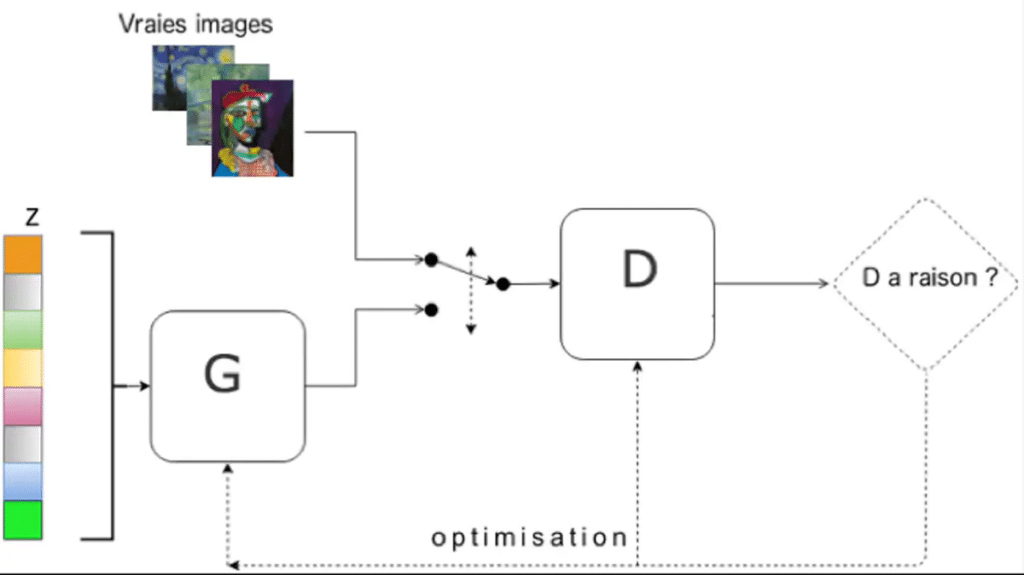
Au début, aucun des deux réseaux n’est entraîné. Lors de l’apprentissage, le discriminateur est confronté à la fois à des images réelles et des images provenant du générateur. Son objectif est alors de distinguer la provenance de chacune des images. En parallèle, le générateur apprend à créer une image qui peut tromper le discriminateur. Au fur et à mesure, le générateur devient de plus en plus efficace pour générer des images réalistes tandis que le discriminateur réussit à trouver des erreurs dans les fausses images de plus en plus légères.
C’est par ce processus d’apprentissage adverse que le réseau de neurones peut apprendre à créer avec autant de réalisme des photographies de personnes.
D’où vient le GAN ?
L’intelligence artificielle a fait des pas de géant lorsqu’il s’agit d’identifier des objets dans une image. L’IA est aussi capable, par exemple, de démêler les règles d’un jeu à force de jouer contre elle-même des milliers de fois. Mais le problème se pose lorsque l’on demande à une IA de créer quelque chose de nouveau, quelque chose qui n’existait pas auparavant. Parce que l’IA peut simuler notre intelligence, mais pas notre imagination.
En 2014, lors d’un débat dans un bar avec d’autres doctorants, un étudiant de l’Université de Montréal dénommé Ian Goodfellow a eu une idée sur la façon de surmonter cet obstacle.
Comme presque tout dans la science, le jeune homme a s’est inspiré de recherches antérieures telles que les travaux publiés par Jürgen Schmidhuber dans les années 1990 sur la « Predictability Minimization » (réduction de la prédictibilité) et l’« Artificial Curiosity » (curiosité artificielle) ainsi que le concept d’« Apprentissage de Turing ».
A quoi sert le GAN ?
L’une des dernières et des plus surprenantes applications de cette technologie qui permet de « mettre un visage sur un autre » est le générateur de faux visages humains comme le DCGAN développé par Nvidia. Ce dernier permet désormais de générer des visages hyperréalistes (ou presque) ne correspondant à aucune personne réelle.
Sur la base de cette technologie, plusieurs générateurs web ont été aussi développés. Ils ne se limitent pas aux visages, mais utilisent des personnages de mangas ou des chats.
Mais, l’utilité d’un GAN ne se limite pas seulement aux images. Il peut également être utilisé dans les vidéos comme le cas des très controversés Deepfakes.
Cependant, Goodfellow est convaincu que sa création peut offrir bien plus à l’humanité. Le GAN a le potentiel de générer des objets que nous pouvons utiliser dans le monde réel. Dans un avenir pas trop lointain, le GAN pourra être utilisé dans différentes disciplines telles que la conception de médicaments, de puces plus rapides, de bâtiments résistants aux séismes, de véhicules plus efficaces ou de bâtiments peu coûteux. Il faut prendre en compte le fait que cette technologie n’est qu’à ses balbutiements.
Les améliorations du StyleGAN
Cependant, l’architecture du GAN présente encore quelques limitations :
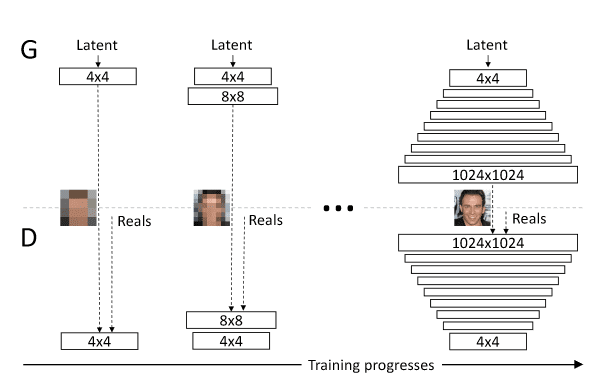
- Il est difficile de générer des images de haute résolution pour le GAN. En effet, le nombre de paramètres à apprendre dès le début est particulièrement élevé.
- Les images générées manquaient de diversité. Les GANs sont assez sensibles à ce qu’on appelle le ‘mode collapse’. C’est-à-dire que le générateur génère toujours les mêmes images qui arrivent à tromper le discriminateur.
- Enfin, on ne peut pas contrôler les caractéristiques de sortie des images générées.
Le progressive growing ou croissance progressive permet de résoudre les limitations de résolution. Concrètement, l’adaptative growing consiste à entraîner le modèle sur des images de résolution croissante. Au fur et à mesure de l’apprentissage, on ajoute des couches au générateur et discriminateur pour travailler sur des images de meilleures résolutions tout en tirant parti de l’apprentissage déjà effectué.
De plus, le progressive growing améliore aussi la stabilité de l’algorithme et la diversité des images créées.
Pour contrôler les caractéristiques des images générées, on cherche à décorréler (disentangle) le vecteur de bruit (z) avec les caractéristiques désirées.
Imaginons que l’on cherche à générer une personne avec des lunettes : modifier seulement une valeur du vecteur bruit risque de provoquer beaucoup de changements différents. En effet, une valeur de bruit n’est pas directement corrélée à une seule caractéristique de l’image. On cherche donc à désenchevêtrer les dimensions du vecteur de bruit avec les features de l’image.
Le disentanglement est permis en particulier en créant un vecteur de bruit intermédiaire dans un sous-espace où les dimensions sont décorrélées.
Enfin, le StyleGan utilise d’autres améliorations plus complexes telles que l ‘Adaptative Instance Normalization et le style mixing
Conclusion
En corrigeant certains défauts du GAN classique, le StyleGAN puis son successeur, le StyleGAN2 ont défini un état de l’art pour la génération d’images réalistes via machine learning. Cependant, il reste certains points à améliorer comme la gestion des arrières-plans. Vous pouvez vous entraîner à repérer les images en jouant le discriminateur sur ce site.
Si vous voulez en apprendre plus sur la computer vision et l’intelligence artificielle appliquée aux images : découvrez l’une de nos formations.









