Ces derniers temps, le web est inondé de photos et de vidéos associées au mot DeepFake, mais de quoi s’agit-il réellement ?
Le DeepFake, autrement appelé « hypertrucage », vient de la concaténation de « Deep Learning » et surprise… « Fake« . Il consiste à synthétiser des images ou des vidéos à partir d’autres images et vidéos totalement différentes afin de recréer une toute nouvelle scène, sans pour autant que la supercherie soit révélée.
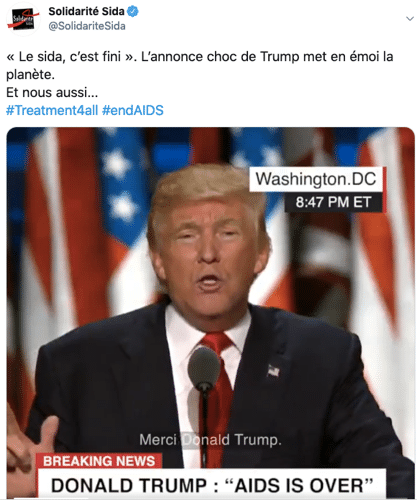
On comprend donc rapidement que cet outil peut s’avérer dangereux, notamment dans cette ère des réseaux sociaux, où la désinformation massive est monnaie courante. On pense notamment à la campagne contre le Sida réalisée il y a quelques mois par Solidarité Sida, qui impliquait une vidéo DeepFake du président américain Donald Trump qui « annonce » la fin du SIDA.
Comment ça marche ?
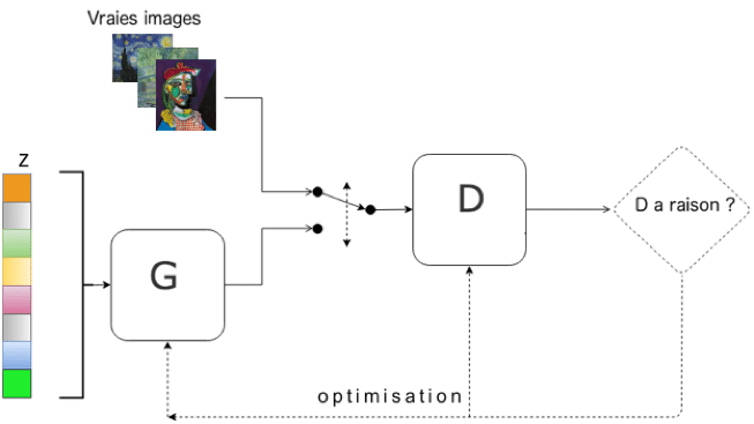
Les algorithmes de DeepFake se basent sur des réseaux adverses antagonistes (ou generative adverse networks / GANs).
Dans les grandes lignes, il s’agit d’un modèle dont l’apprentissage est en deux temps : un premier réseau de neurones va générer un objet (une image, une vidéo, un son…) et un second réseau se chargera de déterminer si cet objet est généré par le premier ou non, le tout, avec une base de données d’images similaires à celles souhaitées comme ‘combustible’ pour l’algorithme.
Un GAN est donc composé de deux réseaux de neurones : un générateur (G sur le schéma) et un discriminateur (D sur le schéma), dont les interactions antagonistes participent à un entrainement mutuel. Pour plus de précisions sur le fonctionnement global des réseaux de neurones, n’hésitez pas à consulter nos articles sur le Deeplearning et le Style Transfer
En voie de démocratisation / Comment le faire ?
Depuis quelques mois, plus besoin d’avoir fait un master en DataScience à Stanford pour être capable de produire ses propres DeepFake plus ou moins détectables à l’œil nu .
On peut mentionner l’application chinoise Zao qui permet d’incruster un visage dans une séquence vidéo.
L’application est amusante mais implique de renoncer aux droits sur les photos prises…
Mais également le plus populaire sur les réseaux : le First-Order-Motion-Model, package développé par Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci et Nicu Sebe, permettant de créer par DeepFake des photos et des vidéos d’un réalisme troublant avec peu d’effort, puisqu’un environnement collaboratif a été mis à disposition par les créateurs sur Google Collab, permettant de lancer le programme sans aucun prérequis technique !
Cet article vous a plu ? Envie d’aller plus loin en Deep Learning ? Découvrez notre dossier dédié ou démarrer rapidement une formation en Data Science avec DataScientest !









