La performance d’un algorithme de Machine Learning est directement liée à sa capacité à prédire un résultat. Lorsque l’on cherche à comparer les résultats d’un algorithme à la réalité, on utilise une matrice de confusion. Dans cet article, vous verrez comment lire cette matrice pour interpréter les résultats d’un algorithme de classification.
Qu’est ce qu’une matrice de confusion ?
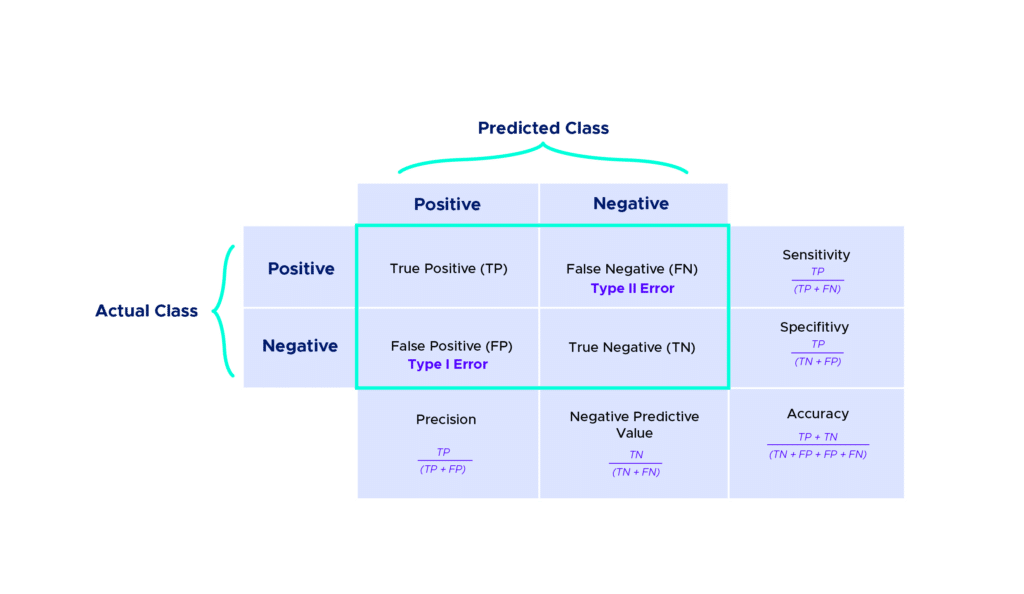
Le Machine Learning consiste à nourrir un algorithme à l’aide de données afin qu’il apprenne par lui-même à effectuer une certaine tâche. Dans les problèmes de classification, il prédit des résultats que l’on doit comparer à la réalité pour mesurer son degré de performance. On utilise généralement la matrice de confusion, appelée aussi tableau de contingence. Elle mettra non seulement en valeur les prédictions correctes et incorrectes mais nous donnera surtout un indice sur le type d’erreurs commises. Pour calculer une matrice de confusion, on a besoin d’un ensemble de données de test et un autre de validation qui contient les valeurs des résultats obtenus.
Chaque colonne du tableau contient une classe prédite par l’algorithme et les lignes des classes réelles.
On classe les résultats en 4 catégories :
True Positive (TP) : la prédiction et la valeur réelle sont positives.
Exemple : Une personne malade et prévu malade.
True Negative (TN) : la prédiction et la valeur réelle sont négatives.
Exemple : Une personne saine et prévu saine.
False Positive (FP) : la prédiction est positive alors que la valeur réelle est négative.
Exemple : Une personne saine et prévu malade.
False Negative (FN) : la prédiction est négative alors que la valeur réelle est négative.
Exemple : Une personne malade et prévu saine.
Bien évidemment, on peut ajouter des lignes et des colonnes à cette matrice dans des cas plus complexes.
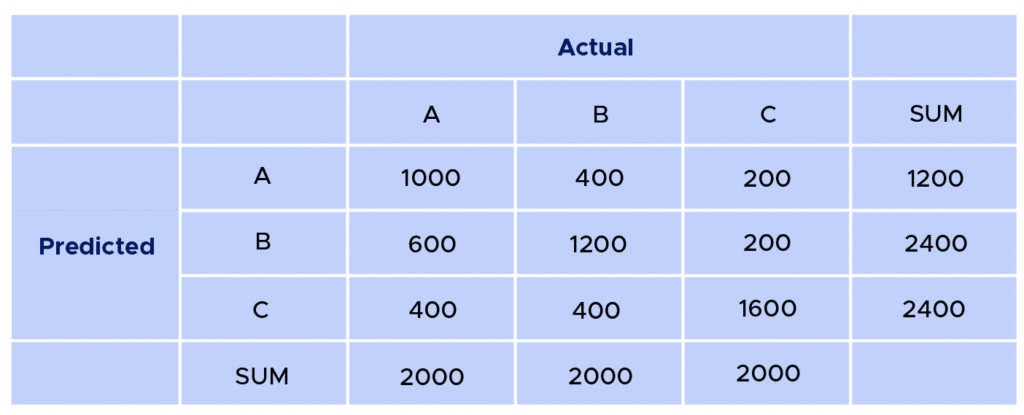
Exemple : Suite à l’application d’un modèle prédictif, nous obtenons les résultats suivants
D’une manière générale, on retrouve toujours les bonnes prédictions sur la diagonale. On a donc ici :
600 individus ayant été classés comme appartenant à la classe A sur un total de 2000 individus, ce qui est assez faible.
Pour les individus de la classe B, 1200 sur 2000 ont bien été identifiés comme appartenant à cette classe.
Pour les individus de la classe C, 1600 sur 2000 ont bien été identifiés.
Le nombre de True Positive (TP) est donc de 3400.
Pour avoir le nombre False Positive (FP),True Negative (TN),False Negative (FN). Il n’est pas possible sur ce tableau de les calculer directement, il faudrait alors le séparer en trois cas :
A et ( B et C)
B et (A et C)
C et (A et b)
On peut ainsi calculer toutes les métriques nécessaires à l’analyse de ce tableau.
On retrouve ici les manières les plus communes de tirer des informations intéressantes de ce genre de tableau, on appelle ces indicateurs des métriques :
Accuracy
Precision
Negative Predictive Value
Specificity
Sensitivity
Dans la pratique, il existe sur python un moyen très simple d’accéder à l’ensemble de ces métriques grâce à la fonction classification_report de la bibliothèque sklearn.
Exemple:
Ce qui nous donne le résultat suivant :
Quelles métriques utiliser pour évaluer nos prédictions ?
On a ici fait le choix de nommer les différentes classes en fonction des valeurs de y_true. On observe alors différentes métriques qui vont nous permettre de juger de la qualité de nos prédictions qui sont principalement :
Precision
Recall
F1-score
Dont les formules sont respectivement :
Dans notre cas, on peut observer une Precision de 0 pour la classe 1. Cela est tout simplement dû au fait qu’aucun individu de classe réel 1 n’est prédit comme appartenant à cette classe. A l’inverse des individus de la classe 2 où 2 ont correctement été attribués sur 3 qui ont été attribués à la classe 2 nous donne une Precision de 0,67.
Les différences entre Micro-average et macro-average
Le calcul et l’interprétation de ces moyennes sont légèrement différents.
Quelque soit la métrique utilisée, une macro-moyenne effectue une moyenne suite au calcul de la métrique indifféremment des classes. Au contraire, une micro-moyenne prendra en compte les contributions de chaque classe pour calculer la métrique moyenne.
Dans une classification à plusieurs classes, on privilégiera souvent cette approche lorsque l’on suspecte un déséquilibre entre les classes ( effectif, importance …).
Exemple:
Ce qui nous donne le résultat suivant :
Vous savez à présent comment lire et interpréter les résultats d’un algorithme de classification. Si vous voulez en savoir plus à ce sujet, vous pouvez consulter nos formations Data Analyst, Data Scientist et Data Manager qui reprennent ces notions sur des cas plus concrets.