
Comme leur nom l’indique, les algorithmes d’optimisation ont pour but de trouver une bonne solution (idéalement la meilleure) à un problème, en fonction de certains critères ou d’objectifs spécifiques.
Parmi les nombreux algorithmes d’optimisation disponibles, une partie d’entre eux s’inspirent de ce qui existe déjà dans la nature : il s’agit des algorithmes biomimétiques. Ils peuvent s’inspirer de l’intelligence collective des insectes (optimisation par essaim) ou encore des mécanismes de la sélection naturelle comme pour les algorithmes d’optimisation génétiques (également appelés évolutionnistes).
Les mécanismes de la sélection naturelle (issus notamment de la théorie de Darwin) ont pour but de sélectionner les individus les mieux adaptés afin de permettre à l’espèce de s’améliorer au fil des générations.
Dans le cas des algorithmes génétiques, les données de notre problème sont stockées sous la forme d’un vecteur qui représente le génome des différents individus. Il s’agit de constituer une population initiale d’individus puis d’en sélectionner les meilleurs, génération après génération. Cette sélection s’effectue selon des critères de notation, les individus les mieux notés sont alors sélectionnés pour la prochaine génération.
Pour illustrer cet article, je vais prendre l’exemple d’un vacancier qui souhaite passer 10 jours dans le parc naturel régional du Morvan en Bourgogne. Il veut visiter les villes offrant le plus de points d’intérêt historiques en parcourant le moins de kilomètres. Les troisièmes et huitièmes jours, il souhaite passer la nuit dans un hôtel 3 étoiles minimum.
Il existe bien entendu des librairies clé en main plus sophistiquées pour utiliser ces algorithmes, mais l’exemple de code développé ici permettra d’en comprendre les mécanismes de base.
Les données
Pour alimenter mes données, j’ai récupéré sur OpenStreetMap les points d’intérêts (POI) historiques de chaque commune du parc. Les données gouvernementales françaises m’ont permis de connaître l’implantation des hôtels 3 étoiles ou plus ainsi que les coordonnées géographiques du centre ville en vue des calculs de distance.
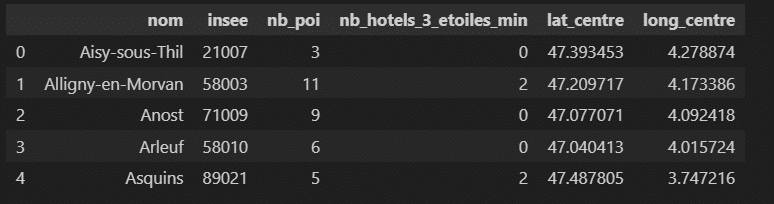
Constitution de la population initiale
Si l’on voulait trouver directement la solution optimale au problème, on devrait envisager toutes les combinaisons possibles et évaluer comment elles répondent au problème. Malheureusement, les capacités de calcul actuelles ne le permettent pas pour les problèmes un tant soit peu complexes. C’est pourquoi il faut constituer une population dont le volume est suffisamment important pour constituer un échantillon représentatif, mais pas trop non plus pour ne pas alourdir excessivement les temps de calcul. Un arbitrage possible peut être de compenser une population plus faible par l’augmentation du nombre d’itérations (soit de générations). Cette étape comporte une certaine dose d’empirisme et on pourra tenter plusieurs essais pour arriver à un bon compromis. J’ai retenu une population initiale de 1500 individus.
Concernant les caractéristiques génétiques de chaque individu, la solution est extrêmement simple : le génome est constitué de façon aléatoire à partir des différentes valeurs.
Dans notre cas, on utilise une fonction de génération de listes aléatoires à partir des codes INSEE des différentes communes du parc du Morvan.
Évaluation des individus
Une fois la première génération de la population constituée, chaque individu doit être évalué afin que les meilleurs puissent être sélectionnés.
Ici, il n’y a aucune solution générale, chaque problématique nécessite sa propre méthode d’évaluation pour la sélection des meilleurs individus. Une fois l’évaluation effectuée, le processus de sélection et de constitution des nouvelles génération va pouvoir se faire.
Dans mon cas, les deux critères de notation sont la distance totale parcourue et le nombre total de points d’intérêts du parcours. Pour éviter d’avoir des parcours avec peu de kilomètres, mais sans beaucoup de points d’intérêt (ou l’inverse), j’ai choisi de regrouper par décile les parcours à la fois les plus performants en terme de kilométrage et de points d’intérêt. Ainsi, les parcours notés 2 appartiennent à la fois aux deuxièmes déciles de ces deux catégories. Les parcours notés 10 regroupent, en plus de leurs déciles, tous les parcours ne répondant pas à cette obligation de double appartenance aux déciles précédents.
Comme le critère lié aux hébergements dans les hôtels allait forcément changer en fonction des itérations, j’ai décidé de ne pas le retenir comme critère pur de notation mais je l’utilise en tant que filtre dans mes dataframes.
Sélection et constitution de la prochaine génération
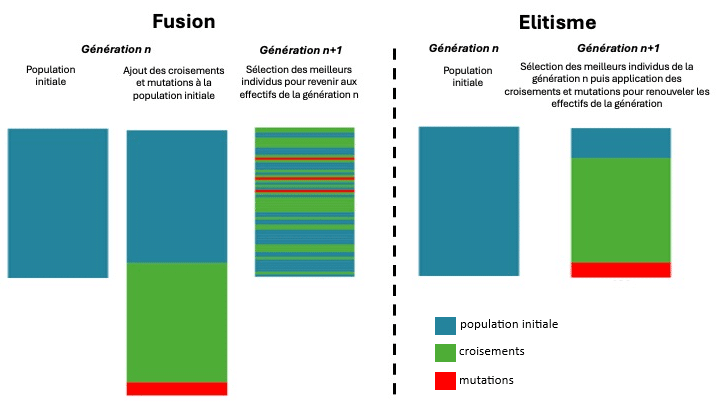
À ce stade, deux stratégies sont possible. L’élitisme ou la fusion. Dans les deux cas, le but est d’obtenir une nouvelle génération dont le nombre d’individus est égal à la génération précédente.
Dans le cas de l’élitisme, l’évaluation s’opère d’abord, puis les génomes des individus les mieux notés sont directement repris pour la prochaine génération. Le reste de la population sera garnie par des individus issus de croisements (comme cela se passe avec la reproduction sexuée) ou de mutations.
Dans le cas de la fusion, la nouvelle génération (comportant le même nombre d’individus que la précédente) est d’abord créée par croisements et mutations. La sélection s’opère par la suite et seuls les individus les mieux évalués sont retenus à hauteur des effectifs de la génération précédente.
Dans le cadre de mon projet, j’ai choisi le système élitaire suivant le vieil adage selon lequel on ne change pas une équipe qui gagne. Plus sérieusement, chaque système présente ses propres avantages et inconvénients. Si la fusion permet d’augmenter la variété génétique des individus, l’élitisme permet de préserver les individus les mieux adaptés. C’est cette qualité qui m’a décidé à retenir l’élitisme. Pour la cohorte, j’ai sélectionné 20% des meilleurs individus de la population en tant qu’élite pour la sélection de la génération suivante. Il est globalement admis que la part des élites peut être comprise entre 5% et 20%, j’ai choisi la fourchette haute.
Croisement et mutation
Ces deux processus naturels permettent la création de nouveaux individus dont les caractéristiques propres de leur génome leur permettront potentiellement d’être mieux adaptés à leur environnement. Étant mieux adaptés, ces individus auront plus de chance de survire, et donc de se reproduire et transmettre leurs gênes.
Dans le cas des algorithmes génétiques, la logique est similaire. Les individus les mieux évalués sont sélectionnés pour la génération suivante et seront par la suite mieux susceptibles de transmettre leurs caractéristiques.
Le croisement consiste à reprendre les mécanismes de la reproduction sexuée. Les gênes des deux ascendants sont brassés pour constituer un nouveau génome unique.
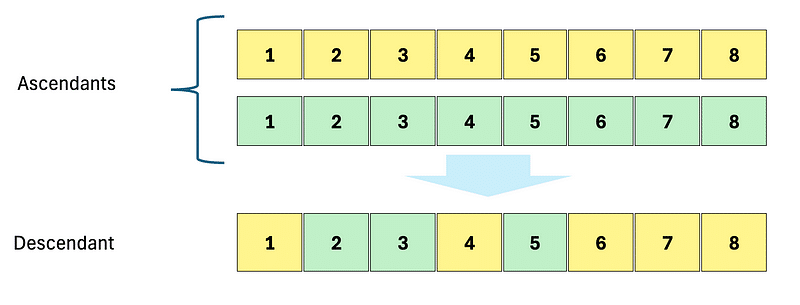
Dans certains modèles, il est proposé de mélanger les génomes partie par partie (par moitié ou par paire de gène). En ce me concerne j’ai privilégié une approche similaire à celle existant dans la nature, gène par gène.
Dans mon cas, la fonction de croisement des individus s’accompagne d’une petite dose de mutations. En théorie, sur un emplacement donné, la sélection s’opère uniquement entre le gène de chaque parent. Avec ce système, une même ville pourrait apparaître deux fois dans le même parcours, ce qui n’est pas souhaitable. J’ai donc implanté une contrainte évitant ce phénomène.
Dans la nature, il existe également des processus de mutation. Le génome d’un individu va se modifier indépendamment de tout processus de reproduction. Ce mécanisme permet d’augmenter la variabilité génétique en provoquant des solutions génétiques inédites.
3 possibilités de mutations peuvent se produire.
L’insertion : un gène se déplace pour s’insérer après un autre
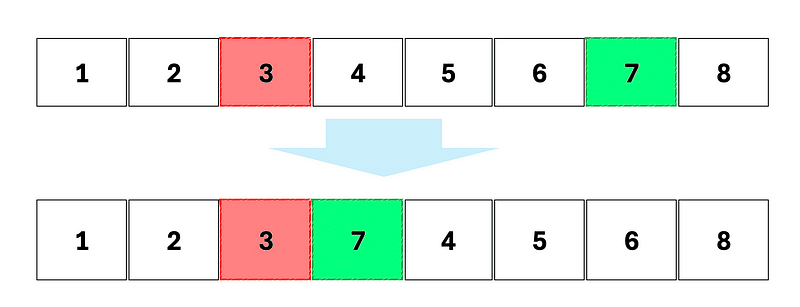
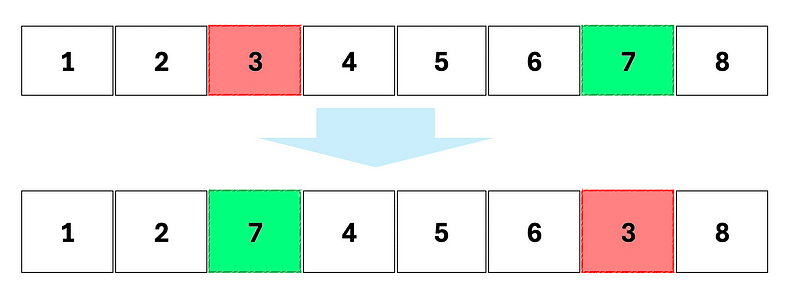
La permutation (ou swap) : deux gènes permutent leur emplacement
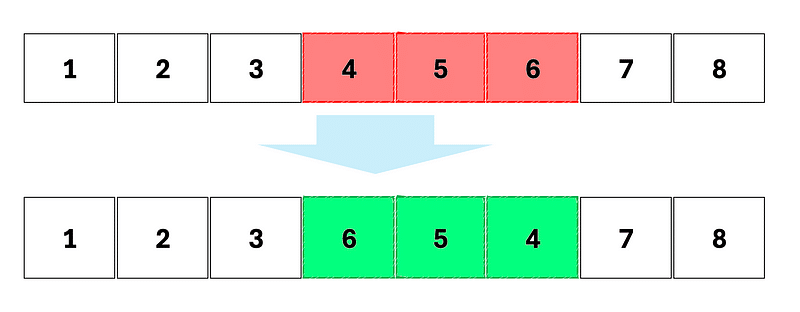
L’inversion de séquence : l’ordre d’une partie du génome est inversé
La part des mutations représente habituellement 5% des nouveaux individus mais j’ai pu observer des taux de mutations allant jusqu’à 10%. Étant donné que le système élitaire à tendance à réduire la variabilité des génomes, j’ai retenu cette valeur de 10% en compensation.
Itération du processus et solution
En itérant le processus de sélection et de constitution des nouvelles générations, on va progressivement obtenir des individus dont les caractéristiques permettent de mieux en mieux à répondre au problème donné.
La question qui se pose maintenant est de savoir quand arrêter le processus. Cela dépend de nos contraintes.
Si on a un temps limité, on peut stopper les itérations passé un certain temps d’exécution. On peut aussi tenter d’atteindre un seuil correspondant à un critère (un nombre de kilomètres idéal pour notre trajet par exemple, ou que chaque ville visité ait un nombre minimum de points d’intérêts. En mode expérimental on peut lancer des itérations à plusieurs reprises et analyser le moment où les itérations n’apportent plus vraiment d’amélioration significative. On fixe alors un nombre limite d’itérations.
Dans le cadre de cet exercice, afin de ne pas avoir de temps de calcul excessivement long, je me suis contenté de 200 itérations.
En conclusion
Comme dans beaucoup de domaines, la nature cette fois encore est une belle source d’inspiration. Cet exemple simple permet de comprendre comment on peut optimiser des problèmes complexes en s’inspirant de solutions naturelles retenues depuis des centaines de millions d’années.
En définitive, après 200 itérations, j’ai obtenu le trajet suivant :
Glux-en-Glenne, Roussillon-en-Morvan, Alligny-en-Morvan, Anost, Quarré-les-Tombes, Saint-Léger-Vauban, Avallon, Vézelay, Bazoches, Pierre-Perthuis… pour un total de 154km et un total de 115 points d’intérêt sur le parcours.
En augmentant le nombre d’itérations j’aurais encore pu améliorer la solution, mais le but de ce script est plus d’être explicatif que performant. Je n’ai pas voulu trop allonger les temps de calcul pour l’exécution.
Pour information, l’utilisation de dataframes Pandas n’est pas optimale en terme de performance mais là encore, le but principal de ce script est d’être explicatif.
Vous pouvez retrouver mon code complet sur mon repo git.








