
Pandas est une bibliothèque du langage de programmation Python, entièrement dédiée à la Data Science. Découvrez à quoi sert cet outil, et pourquoi il est incontournable pour les Data Scientists.
Créé en 1991, Python est le langage de programmation le plus populaire pour l’analyse de données et le Machine Learning. Plusieurs avantages expliquent ce succès auprès des Data Scientists.
Il s’agit tout d’abord d’un langage très simple d’utilisation. Même un débutant peut rapidement produire des programmes grâce à une syntaxe simple et intuitive.
Ce langage fédère une vaste communauté, ayant créé de nombreux outils pour la Data Science. Il existe par exemple des outils pour la Data Visualisation tels que Seaborn et Matplotlib, et des bibliothèques logicielles comme Numpy. L’une de ces bibliothèques est Pandas, conçue pour la manipulation et l’analyse de données.
Qu'est-ce que Pandas ?
La bibliothèque logicielle open-source Pandas est spécifiquement conçue pour la manipulation et l’analyse de données en langage Python. Elle est à la fois performante, flexible et simple d’utilisation.
Grâce à Pandas, le langage Python permet enfin de charger, d’aligner, de manipuler ou encore de fusionner des données. Les performances sont particulièrement impressionnantes quand le code source back-end est écrit en C ou en Python.
Le nom « Pandas » est en fait la contraction du terme « Panel Data » désignant les ensembles de données incluant des observations sur de multiples périodes temporelles. Cette bibliothèque a été créée comme un outil de haut niveau pour l’analyse en Python.
Les créateurs de Pandas comptent faire évoluer cette bibliothèque pour qu’elle devienne l’outil d’analyse et de manipulation de données open-source le plus puissant et flexible dans n’importe quel langage de programmation.
Outre l’analyse de données, Pandas est très utilisé pour le « Data Wrangling ». Ce terme englobe les méthodes permettant de transformer les données non structurées afin de les rendre exploitables.
De manière générale, Pandas excelle aussi pour traiter les données structurées sous forme de tableaux, de matrices ou de séries temporelles. Il est également compatible avec d’autres bibliothèques Python.
Comment fonctionne Pandas ?
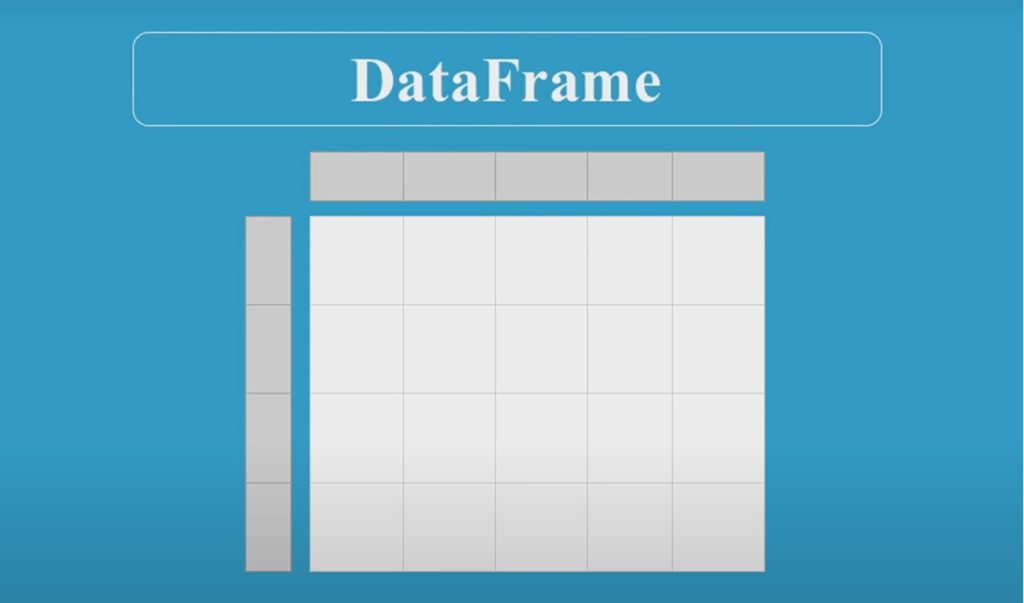
Le fonctionnement de Pandas repose sur les « DataFrames » : des tableaux de données en deux dimensions, dont chaque colonne contient les valeurs d’une variable et chaque ligne contient un ensemble de valeurs de chaque colonne. Les données stockées dans un DataFrame peuvent être des nombres ou des caractères.
Les Data Scientists et programmeurs initiés au langage de programmation R pour le calcul statistique utilisent les DataFrames pour stocker les données sous forme de grilles très simples à passer en revue. C’est la raison pour laquelle Panda est très utilisé pour le Machine Learning.
Cet outil permet d’importer et d’exporter les données dans différents formats comme CSV ou JSON. Par ailleurs, Pandas offre aussi des fonctionnalités de Data Cleaning.
Cette bibliothèque est très utile pour travailler avec des données statistiques, des données tabulaires comme des tableaux SQL ou Excel, avec des données de séries temporelles, et avec des données de matrices arbitraires avec étiquettes de lignes et de colonnes.
Quels sont les avantages de Pandas ?
Pour les Data Scientists et les développeurs, Pandas apporte plusieurs avantages. Cette bibliothèque permet de facilement compenser les données manquantes.
Il s’agit d’un outil flexible, car les colonnes peuvent être facilement insérées ou supprimées au sein des DataFrames. L’alignement des données avec les étiquettes peut être automatisé.
Autre atout : un puissant outil de regroupement des données permettant d’effectuer des opérations de type « split-apply-combine » sur les ensembles de données, pour les agréger ou les transformer.
Il est très facile de convertir des données indexées différemment dans d’autres structures Python et Numpy sous forme d’objets DataFrame. De même, les données peuvent être indexées ou trier grâce à un système intelligent basé sur les étiquettes.
Les ensembles de données peuvent être fusionnés intuitivement, restructurés de manière flexible. Des outils I/O simplifient le chargement de données en provenance de fichiers CSV, Excel, de bases de données, ou le chargement de données au format HDF5.
Les fonctionnalités dédiées aux séries temporelles complètent le tableau, avec notamment la génération de rang de date, la conversion de fréquence, ou le déplacement de fenêtres statistiques.
Ces nombreux points forts font de Pandas une bibliothèque incontournable pour la Data Science en langage Python. Il s’agit d’un outil très utile pour les Data Scientists.
Comment les Data Scientists utilisent-ils Pandas ?
Certains langages de programmation sont traditionnellement utilisés dans les environnements scientifiques ou par les équipes de recherche et développement en entreprise. Toutefois, ces langages posent souvent des problèmes aux Data Scientists.
Or, Python permet de surmonter la plupart de ces limites. Il s’agit d’un langage idéal pour les différentes étapes de la science des données : le nettoyage, la transformation, l’analyse, la modélisation, la visualisation et le reporting.
Son interface est agréable, la documentation est complète, l’utilisation est relativement intuitive. La popularité de Pandas est aussi liée à son ancienneté. Il s’agit de la première bibliothèque de ce type à avoir vu le jour, ou du moins l’une des premières.
De plus, c’est un outil open-source et de nombreuses personnes ont contribué au projet. C’est que qui lui a permis d’atteindre un tel succès.
Pandas, NumPy et scikit-learn : 3 bibliothèques Python pour la Data Science
Outre Pandas, il existe d’autres bibliothèques logicielles Python dédiées à la Data Science. NumPy est une bibliothèque mathématique permettant d’implémenter de façon très efficace de l’algèbre linéaire et des calculs standards.
Précisons que Pandas est basé sur NumPy. De nombreuses structures de données et fonctionnalités de Pandas proviennent de NumPy. Ces deux bibliothèques sont étroitement liées entre elles, et souvent utilisées conjointement.
De son côté, Scikit-learn est la référence pour la plupart des applications de Machine Learning en Python. Pour créer un modèle prédictif, on utilise généralement Pandas et NumPy pour charger, analyser et formater les données à utiliser. Ces données sont ensuite utilisées pour nourrir le modèle à partir de scikit-learn. Ce modèle est ensuite utilisé pour établir des prédictions. Ainsi, Pandas, Numpy et Scikit-learn sont trois outils couramment utilisés en Data Science.
Les alternatives à Pandas
Il n’existe pas de véritable alternative à Pandas en langage Python. En revanche, les utilisateurs du langage R peuvent se tourner vers la bibliothèque « Dplyr ».
Le concept est similaire à Pandas. Cette bibliothèque est dédiée à la manipulation de données et permet de simplifier et d’accélérer certaines fonctionnalités.
Quelles entreprises utilisent Pandas ?
N’importe quelle entreprise utilisant Python pour l’analyse de données a besoin de Pandas et de sa polyvalence. Toutes les entreprises manipulant des données tabulaires trouveront cet outil d’un précieux secours.
En revanche, Pandas n’est pas forcément adéquat pour travailler avec des formats de données incompatibles comme des images, des fichiers audio ou certaines données textuelles. La structure de ces types de données n’est pas adaptée pour un usage avec Pandas. Il est donc important de tenir compte du type de données à traiter avant de choisir un outil.
Cette bibliothèque est très utilisée parmi les entreprises traitant des données relationnelles sur leurs clients et des données sur les transactions, pour analyser les tendances et modéliser les comportements.
De même, de nombreuses entreprises de l’immobilier s’en servent pour analyser de larges quantités de prix et de caractéristiques afin de déterminer les tendances et créer des modèles prédictifs.
Comment apprendre à utiliser Pandas ?
Après avoir appris les bases de Python, il est très facile d’apprendre à utiliser Pandas. La maîtrise de ces deux outils permet de travailler avec n’importe quel type de données.
La bibliothèque Pandas est la solution la plus simple pour formater un ensemble de données, et l’analyser pour en extraire des informations précieuses. Pour un Data Scientist, il s’agit tout simplement d’un incontournable.
Apprendre à utiliser Pandas permet d’ouvrir de nombreuses portes, car cette compétence est recherchée par les employeurs. Les entreprises de tous secteurs utilisent de plus en plus la Data Science, et ont donc besoin de s’entourer d’experts sachant manier les outils adéquats.
Il est très facile de maîtriser les opérations les plus basiques avec Pandas. Toutefois, savoir utiliser les fonctionnalités plus avancées peut s’avérer complexe et demander davantage de temps. C’est le cas des calculs agrégés, des fusions de DataFrames ou encore du traitement de séries temporelles.
Pour apprendre à utiliser Pandas, vous pouvez commencer par consulter la documentation officielle. C’est une bonne façon de découvrir les bases et de comprendre le fonctionnement.
Il existe aussi des dépôts de code contenant des défis en ligne pour Pandas. Ces « repos » peuvent vous permettre de tester vos compétences au fil du temps et de votre progression.
Les sites web comme Kaggle permettent de découvrir des ensembles de données, et de visualiser comment d’autres ont utilisé Pandas pour les analyser. Ceci permet de mieux comprendre comment cette bibliothèque est exploitée pour travailler avec des données en conditions réelles.
Lancer votre propre projet avec Pandas est une excellente manière de progresser. Il vous suffit de trouver un ensemble de données, et d’essayer de l’analyser avec Pandas. En choisissant des données qui vous intéressent, ce travail vous semblera plus concret et vous apprendrez plus vite. Corrigez peu à peu vos erreurs, afin d’en tirer des leçons et de vous améliorer.
Pour apprendre à utiliser Pandas et toutes ses subtilités, vous pouvez choisir les formations DataScientest. Cette bibliothèque Python est au programme de nos formations Data Scientist, Data Analyst et Data Management.
Nos différents parcours permettent d’acquérir toutes les compétences requises pour travailler dans le domaine de la Data Science. À l’issue du cursus, vous serez prêt à travailler et recevrez un diplôme certifié par l’université Dauphine-PSL.
Toutes nos formations peuvent être effectuées en BootCamp ou en Formation Continue. Les cours s’effectuent en ligne, à votre rythme sur une plateforme Cloud coachée par des professionnels. Découvrez les formations DataScientest, et devenez expert de Pandas !
Vous savez tout sur Pandas. Découvrez notre dossier sur Python et notre introduction à NumPy.








