
Pandas est l’une des librairies incontournables de Python, qui est un langage de programmation orienté objet de haut niveau très populaire chez les Data Scientists. Les structures les plus utilisées de ce module sont les Series et les DataFrames. Contrairement aux Series, qui sont des objets correspondants à des tableaux à une seule dimension, les Dataframes sont des tableaux à deux dimensions composés de lignes et de colonnes, ce qui permet de mettre en avant les relations entre les différentes variables du jeu de données.
Un DataFrame est un ensemble de Series Pandas indexées par une valeur. Dans cet article, nous allons présenter la structure des DataFrames puis, se pencher sur ses différents attributs et méthodes de base en expliquant leur utilité et leur fonctionnement.
1) Comment se présente-t-il ?
Le format de ces structures peut être comparé aux dictionnaires Python. En effet, les clés sont les noms des colonnes et les valeurs sont les Series. Sa structure peut être considérée comme similaire à une feuille de calcul Excel.
Chaque ligne contient des données spécifiques à diverses colonnes, qui sont des variables. Le nom des lignes d’un DataFrame est appelé “index” qui, par défaut, commence toujours par 0.
Cependant, il est possible d’indexer les lignes d’un DataFrame par n’importe quelle valeur possible : identifiant client ou encore unité de temps. Pour ce qui est du nom des colonnes, elles sont labellisées sous le nom d’une variable spécifique auquel on lui accorde des valeurs différentes. Les valeurs de ces variables peuvent prendre de nombreux formats de données. Chaque colonne est associée à un type de données, par exemple une chaîne de caractère (object) qui sera relative aux données qualitatives, ou bien une colonne ayant un type intéger, qui correspondra aux nombres entiers. Il est possible de changer le type des variables en fonction des besoins en utilisant la méthode astype().
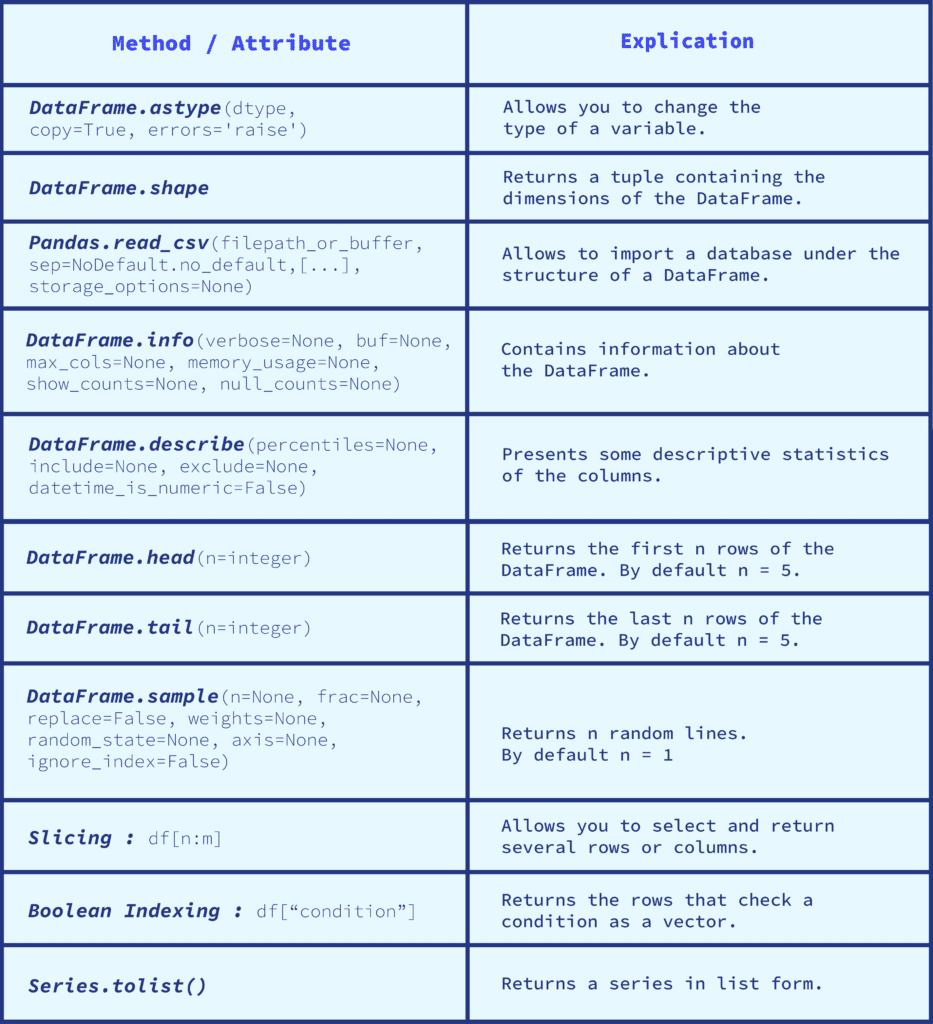
2) Les attributs et méthodes à ne pas manquer
Il existe de nombreuses manières de manipuler les DataFrames. Les attributs et les méthodes de cette structure Pandas sont très nombreux. Cet article se penchera essentiellement sur les méthodes de bases pour apprendre à manier les DataFrames.
A- Importation et Observation du jeu de données
Importation et informations des variables
Pour importer un dataset, la librairie Pandas propose une méthode très pratique qui est pd.read_csv(). Si le fichier contenant le jeu de données est dans un autre format que Comma Separated Value, il suffit de changer la terminaison de la méthode par le bon type de fichier. Par exemple, un fichier Excel sera importé de la manière suivante : pd.read_excel(). Cette méthode importe le jeu de données en structure DataFrame.
Ensuite, la méthode info() doit être utilisée pour avoir les informations relatives au DataFrame. Cette méthode renvoie le type des variables, le nombre des colonnes, le nombre de lignes non nulles, le type de l’index, la taille en mémoire du jeu de données, etc. Il est aussi recommandé d’utiliser la méthode describe(), qui permet de savoir quelques statistiques descriptives sur le DataFrame. Elle permet par exemple de connaître la valeur minimale et maximale de chaque variable, les quartiles ou encore l’écart-type des colonnes. Cette méthode est pratique pour avoir une idée de la distribution des variables.
Premier aperçu du DataFrame
Lorsque le jeu de données est importé, il faut avoir une vue d’ensemble du DataFrame. La première étape est d’utiliser l’attribut shape, qui permet de connaître la dimension du DataFrame en renvoyant un tuple (nombre_de_lignes, nombre_de_colonnes). Pour ce qui est d’appréhender le jeu de données, trois méthodes sont très utiles pour visualiser les lignes du DataFrame :
- La méthode head() renvoie les cinq premières lignes du DataFrame, si aucun nombre n’est spécifié entre parenthèses.
- À contrario, la méthode tail() permet de visualiser les cinq dernières lignes du DataFrame.
Ces deux méthodes permettent d’avoir une visualisation du début et de la fin du jeu de données. Ce qui comporte un réel avantage pour les données de type Times Series, pour avoir une vision simple de l’évolution des données dans le temps, mais permet aussi, dans un cas plus général, de voir si les données gardent un certain sens : si le début du DataFrame diffère considérablement de la fin de ce dernier, il faut en comprendre la cause et chercher à résoudre ce problème avant toute manipulation des données.
- Si une visualisation plus aléatoire des lignes est voulue, la méthode sample() doit être privilégiée. Elle renvoie les lignes de manière aléatoire. Par défaut, le résultat ne retourne qu’une ligne du DataFrame. Il est donc préférable d’écrire un entier dans les parenthèses pour visualiser un plus grand nombre de lignes et, par conséquent, se faire une meilleure idée du contenu du DataFrame.
Le Slicing
Nous pouvons filtrer nos données en utilisant le slice. Par exemple, df[:2] renvoie les deux premières lignes de notre DataFrame. Attention, il ne faut pas oublier que le dernier nombre est exogène au résultat, ce qui signifie que dans l’exemple, le slicing renverra les lignes à l’index 0 et 1.
B- Manipulation des données
Ajouter et changer des données
Comme expliqué dans l’introduction, les DataFrames sont des tableaux à deux dimensions, qui correspondent aux axes des lignes (axis = 0) et des colonnes (axis = 1). Il est possible de rajouter autant de lignes ou de colonnes nécessaires en spécifiant l’axe dans lequel nous voulons rajouter ces nouvelles valeurs.
Ce qui est intéressant avec les DataFrames, c’est qu’il est très facile de récupérer, changer, charger ou chercher des données dans cette structure. Imaginons un DataFrame indexé par le temps, et que nous voulons récupérer toutes les données du 18 décembre 2020. Avec la fonction iloc, il est possible de récupérer toutes les données des variables à cette date. De plus, il est possible de remplacer une valeur d’une des colonnes avec cette fonction en spécifiant l’index et le nom de la colonne. Par exemple, si au 18 décembre 2020 la valeur est manquante, mais nous savons que la valeur réelle est de 25, il suffit de faire df.iloc[index_de_la_ligne, “columns”] = 25.
Le Boolean Indexing
Il est possible de filtrer les données en fonction d’une ou plusieurs conditions, ce qui permet de récupérer des données spécifiques et/ou particulières à un besoin précis, et d’en révéler toutes les informations utiles et nécessaires. C’est ce que l’on appelle le boolean indexing. Cette technique permet de savoir si la valeur d’un test est True ou False et renvoie le résultat sous la forme d’un vecteur. Par exemple, nous sommes en présence d’un jeu de données où chaque colonne est un mois de l’année, que le DataFrame est de type DateTimeIndex, et que nous voulons récupérer les lignes où le mois de janvier est strictement supérieur à 25, alors la manière d’écrire le code est la suivante : df[df[“janvier”] > 25]. Cette méthode de boolean indexing permet de filtrer les données pour ne renvoyer que les lignes qui vérifient la condition “les valeurs supérieures à 25 pour le mois de janvier”. De manière générale, le boolean indexing s’écrit sous le format suivant : df[“condition”].
Les colonnes
Les DataFrames permettent de manipuler et stocker un grand nombre de données. Cependant, dans un cadre professionnel, il arrive régulièrement de traîter des données massives, avec des variables très nombreuses. L’augmentation du nombre de variables a un impact particulier sur l’organisation des DataFrames. En effet, plus le nombre de colonnes est élevé, moins il est aisé de visualiser le nom des variables. Pour résoudre ce problème, il existe plusieurs manipulations possibles.
Si le DataFrame présente dix variables différentes, il est possible de connaître leur nom en utilisant l’attribut df.columns. Mais, lorsque le jeu de données présente huit-cents colonnes, l’affichage du nom des variables ne sera pas complet. Pour résoudre ce problème, il est possible d’utiliser la méthode df.columns.toList(), qui permet de stocker le nom des colonnes dans une liste Python. De plus, pour savoir s’il existe des lignes qui ne sont pas uniques, qui peuvent être en double, la méthode df[“columns”].value_counts() est une manière simple de le vérifier. Par simplicité de lecture, si nous sommes habitués à travailler avec des tableaux, il est possible d’ajouter to_frame() à la fin du code pour visualiser les résultats sous le format d’un DataFrame. Cette méthode de value_counts() permet de connaître l’occurrence des modalités d’une variable.
Les valeurs manquantes
Il est très commun de gérer les valeurs manquantes et/ou aberrantes lorsque l’on travaille sur un projet de Data Science. Les DataFrames permettent de régler ce problème avec une facilité déconcertante. Par exemple, pour les données qualitatives, une des méthodes de remplacement des valeurs manquantes est de traiter par le mode des modalités. Il suffit d’utiliser le code suivant pour arriver à faire cette manipulation : df[column].fillna(df[columns].mode()[0]). Ou par exemple, remplacer des valeurs quantitatives par la moyenne.
Ainsi, les DataFrames permettent de valoriser des corrélations et les relations entre les données grâce aux différentes manipulations possibles, de définir des filtres sur les données présentées aux équipes, de stocker et manipuler des données massives. Pour conclure, les DataFrames permettent aux professionnels de la data de faire parler leurs données, en décidant des conditions et des manipulations à faire.
Si vous souhaitez apprendre à faire parler les données, nos cursus de formation en Data Science sont faits pour vous !









