
Si vous étudiez des données et que vous souhaitez en tirer de l’information, vous devrez souvent traiter les données, les modifier et surtout construire des modèles capables d’apprendre des schémas dans vos données pour une problématique choisie. Beaucoup de librairies open source permettent aujourd’hui de le faire, mais la plus connue d’entre elles est sûrement Scikit-Learn.
Qu’est ce que Sckikit-Learn ?
C’est une librairie Python qui donne accès à des versions efficaces d’un grand nombre d’algorithmes courants. Elle offre également une API propre et uniformisée. Par conséquent, un des gros avantages de Scikit-Learn est qu’une fois que vous avez compris l’utilisation et la syntaxe de base de Scikit-Learn pour un type de modèle, le passage à un nouveau modèle ou algorithme est très simple. La librairie ne permet pas seulement de faire de la modélisation, elle peut assurer également des étapes de preprocessing ce que nous verrons dans la suite de l’article.
Histoire et objectif
Le projet a été initialement lancé en 2007 par David Cournapeau puis très vite de nombreux membres de la communauté scientifique Python se sont mobilisés autour. Le projet a très vite progressé dans le cadre de travaux sur l’imagerie fonctionnelle du cerveau menés par l’Inria. Ainsi en 2009 une première version Scikit-Learn est sortie. Depuis, pas moins d’une quarantaine de versions sont sorties pour arriver à la version actuelle 0.24.1. Ce chiffre en dit beaucoup de l’implication, du travail réalisé sur le projet par des développeurs à travers le monde, chaque version améliorant ou ajoutant de nouvelles méthodes statistiques innovantes.
Dès le départ l’objectif était ambitieux : faire en sorte que la librairie s’utilise facilement sur plusieurs plateformes et la nourrir d’une documentation exhaustive avec des exemples concrets sur chaque outil développé. Aujourd’hui Scikit-Learn fait partie des librairies les plus populaires sur Github. De par les objectifs fixés au début du projet, l’une des forces de Scikit-Learn est sa flexibilité et la facilité avec laquelle vous pouvez l’utiliser sur un grand nombre de problématiques comme par exemple de la segmentation client, de la recommandation de produits, de la détection de fraude…
Enfin, il est important de noter que Scikit-Learn est un projet open source disponible pour tous sous licence BSD. Sur le site de la librairie vous trouverez une documentation très précise des méthodes statistiques disponibles avec des exemples pour comprendre, mais aussi des cas pratiques pour comparer les méthodes entre elles et mieux les appréhender.
Nos cheat sheets




L’API de Scikit-Learn
Elle a été construite selon certains principes de sorte à la rendre très facilement applicable à un grand nombre de domaines :
● Cohérence : Tous les objets partagent une interface commune tirée d’un ensemble limité de méthodes, avec une documentation cohérente.
● Inspection : Toutes les valeurs des paramètres spécifiés sont exposées en tant qu’attributs publics.
● Hiérarchie d’objets limitée : Seuls les algorithmes sont représentés par des classes Python ; les ensembles de données sont représentés dans des formats standard
(tableaux NumPy, DataFrames Pandas, matrices éparses SciPy) et les noms de paramètres utilisent des chaînes Python standard.
● Composition : De nombreuses tâches d’apprentissage automatique peuvent être exprimées comme des séquences d’algorithmes plus fondamentaux, et Scikit-Learn en fait usage chaque fois que cela est possible.
● Valeurs par défaut raisonnables : Lorsque les modèles nécessitent des paramètres spécifiés par l’utilisateur, la bibliothèque définit une valeur par défaut appropriée. Ces principes sont directement décrits dans ce papier présentant les principes de l’API de Scikit-Learn.
Ces 5 principes permettent dans la pratique une utilisation simple et fluide de la librairie même pour des profils ne disposant pas d’un bagage mathématique solide.
Les bases de Scikit-Learn
Comme l’API est uniformisée, Quel que soit le modèle que vous envisagez d’utiliser, les étapes de modélisation sont souvent les mêmes :
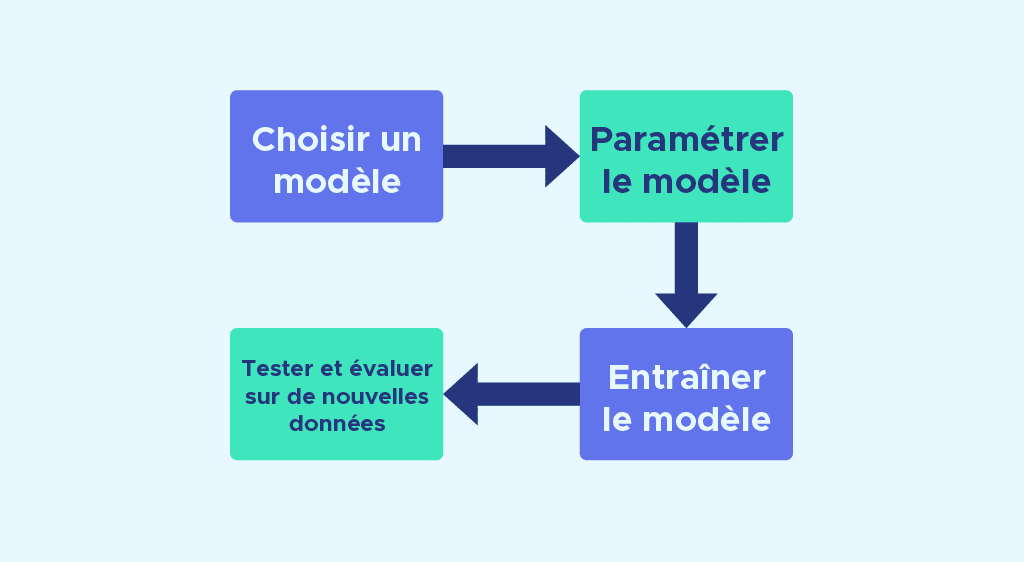
- Choisir un modèle en important la classe appropriée de Scikit-Learn.
- Paramétrer le modèle. Si vous êtes déjà sûrs des paramètres que vous voulez utiliser vous pouvez les renseigner à la main sinon la librairie offre aussi des techniques comme GridSeachCV pour trouver les paramètres optimaux.
- Entraîner le modèle sur le jeu d’apprentissage à l’aide de la méthode fit.
- Tester le modèle sur de nouvelles données :
- Dans le cadre d’apprentissage supervisé, nous utilisons la méthode predict sur les données test.
- Dans le cadre d’apprentissage non supervisé, nous utilisons les méthodes transform ou predict.
Ces 4 étapes sont en général communes à l’utilisation d’un grand nombre de modèles disponibles dans la librairie ce qui permet, une fois que vous avez compris la logique de construction d’un modèle, de pouvoir très facilement utiliser d’autres modèles.
Scikit-Learn : des possibilités nombreuses
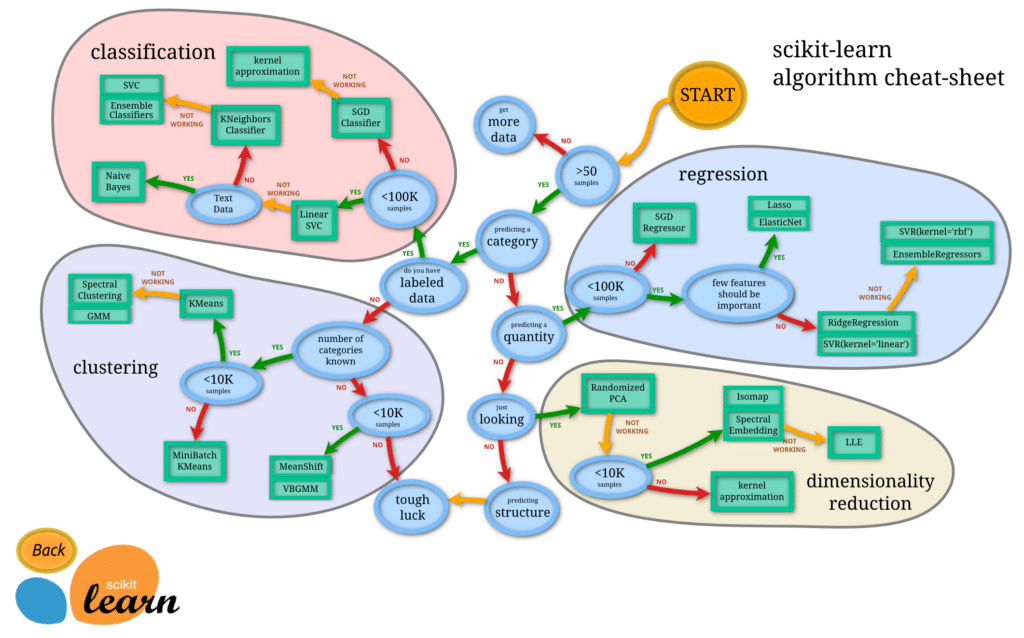
Dans un précédent article nous vous avions parlé des 5 étapes cruciales d’un projet data :
- Saisir les tenants et aboutissants
- Récupérer et explorer les données
- Préparer vos bases de travail
- Sélectionner et entraîner un modèle
- Évaluer vos résultats
Dans les 3 dernières étapes Scikit-Learn est une librairie largement utilisée qui vous fournit tous les outils nécessaires :
- Pour préparer vos données la librairie vous offre un arsenal de méthodes que ce soit pour :
- Séparer vos données en jeu de test et d’apprentissage à l’aide de fonction train_test_split.
- Encoder les variables qualitatives avec des méthodes comme OneHotEncoder.
- Normaliser les données avant de les modéliser avec des méthodes comme StandardScaler par exemple.
- Traiter les valeurs manquantes avec des méthodes simples d’imputation comme SimpleImputer ou bien plus avancées comme IterativeImputer.
- Faire de la sélection de variables avec par exemple SelectKBest.
- Réduire la dimension du jeu de données à l’aide de méthodes comme l’ACP ou TSNE.
Toutes ces méthodes vous permettent de préparer les données efficacement, étape cruciale d’un projet et Scikit-Learn vous offre tous les outils nécessaires pour la réussir. Nous avons cité en exemple une petite partie des méthodes disponibles, vous en trouverez bien d’autres sur le site.
Apprentissage supervisé et non supervisé sur Scikit-Learn
- Pour sélectionner et entraîner un modèle, Scikit-Learn couvre deux grands types d’apprentissage :
- L’apprentissage supervisé : de nombreux modèles comme la régression logistique, la régression linéaire, les régressions linéaires pénalisées comme Ridge, Lasso ou elastic net, les arbres de décisions, les méthodes d’ensemble comme les forêts aléatoires ou bien encore les méthodes de boosting sont disponibles et facilement utilisables pour traiter aussi bien des problématiques de classification et de régression.
- L’apprentissage non supervisé : Là encore l’algorithme des k-moyennes, la classification ascendante hiérarchique, DBSCAN, les mélanges gaussiens sont autant de modèles disponibles et facilement utilisables.
Pour la plupart de ces modèles, surtout en apprentissage supervisé, nous ne connaissons pas à l’avance les meilleurs paramètres à utiliser pour obtenir la meilleure performance possible. Ainsi Scikit-Learn offre des outils comme GridSearchCV ou RandomizedSearchCV qui permettent par validation croisée de déterminer les meilleurs paramètres de notre modèle. Ces deux fonctions sont très largement utilisées par la communauté au moment de modéliser les données.
La grande variété de modèles proposés dans une seule librairie fait de Scikit-Learn un incontournable de l’étape de modélisation des données dans un projet data.
Pour évaluer vos résultats, Scikit-Learn se révèle encore redoutable. Ce ne sont pas moins de 40 métriques disponibles et prêtes à l’emploi pour évaluer les résultats de vos modèles. Certaines comme la RMSE, MAE, MSE, r2_score permettent d’évaluer et de comparer les résultats de modèles de régression. D’autres comme confusion_matrix, accuracy_score, classification_report permettent d’évaluer et de comparer les résultats de modèles de classification. Enfin il en existe aussi comme la silhouette_score pour évaluer la performance d’algorithmes de partitionnement comme la classification ascendante hiérarchique.
Il est important d’ajouter aussi que Scikit-Learn grâce à une méthode nommée pipeline permet d’instancier les 3 dernières étapes d’un projet en très peu de lignes de code. Bien sûr, cet outil s’utilise après avoir testé différents modèles et déterminer le meilleur pour notre problème.
Un peu de pratique
Regardons un exemple concret pour comprendre la capacité de Scikit-Learn à nous offrir des outils statistiques pour mener à bien un projet data avec un minimum de lignes de code.
Dans cet exemple, nous allons utiliser le jeu de données boston house-prices mis à disposition par la librairie et nous allons travailler dessus. Ce dernier ne contient pas de valeurs manquantes et notre objectif sera de tester 3 modèles différents, de trouver pour chacun les paramètres optimaux puis de comparer les scores obtenus pour déterminer le meilleur.
Gist code exemple :
Le code peut se découper en 4 étapes :
- Import et scaling des données à l’aide de la classe StandardScaler.
- Sélection de variables en utilisant la classe SelectKBest.
- Entraînement de 3 modèles différents et recherche des meilleurs paramètres à l’aide de la classe GridSearchCV.
- Comparaison et choix du modèle optimal.
Une dernière étape consiste à instancier toutes ses étapes en une seule ligne de code avec le meilleur modèle en utilisant la classe pipeline et prédire et évaluer sur le jeu de test.
La librairie Scikit-Learn aujourd’hui fournit un très grand nombre d’algorithmes avec des champs d’application dans de nombreux secteurs comme l’industrie, l’assurance, la compréhension des données clients… Chez Datascientest nous vous apprendrons à utiliser, comprendre, interpréter et évaluer un grand nombre d’algorithmes de la librairie sur des problématiques concrètes. N’hésitez pas à découvrir nos formations.








