« Data drives all we do », le slogan de Cambridge Analytica se vérifie en permanence: les données influencent et structurent nos choix, en tant que consommateurs, citoyens, politiques, entrepreneurs…
Ces données sont une manne d’informations décisionnelles. À petite échelle, c’est relativement simple. Mais les experts de la data ont besoin d’outils performants pour traiter et trier l’ensemble des informations à une échelle macro (comme au niveau de la population française). Le spectral clustering est justement l’un de ces outils.
Alors, qu’est-ce que concrètement le spectral clustering et quelle est son utilité? Quels sont les avantages et les limites de ce modèle ?
Qu’est-ce que le spectral clustering ?
Définition
Le spectral clustering est l’un des composants du machine learning et de l’intelligence artificielle.
Il s’agit d’un algorithme de partitionnement des données reposant sur la théorie spectrale des graphes et l’algèbre linéaire.
L’idée est de segmenter un graphe en plusieurs petits groupes ayant des valeurs similaires ou proches.
La différence entre clustering et classification
La classification implique de regrouper les données en fonction d’une classe ou d’un groupe défini à l’avance.
À l’inverse, avec le clustering, l’algorithme ne connaît pas les classes avant de faire le regroupement. On parle alors de technique d’apprentissage non supervisé.
Les différents types de partitionnement de données
Il existe plusieurs types de partitionnement des données qui diffèrent au niveau de leur fonctionnement et de leur objectif. À ce titre, il convient de distinguer le spectral clustering :
- Le K-means : il s’agit d’établir une moyenne de référence parmi un jeu de données. L’idée est alors de définir un profil type qui pourra toucher le plus grand nombre. À l’inverse, le partitionnement de données spectral a pour objectif de créer différents groupes ayant un maximum de points communs.
- Le DBSCAN : cet algorithme se base sur la distance et la densité des clusters pour effectuer des sous-groupes. De son côté, le spectral clustering se base sur la similarité des données.
À quoi sert le spectral clustering ?
Qui utilise le spectral clustering ?
Le spectral clustering est particulièrement utilisé par les professionnels du marketing pour comprendre le comportement des utilisateurs ou de la cible.
Mais attention, cet algorithme exige des compétences spécifiques. À ce titre, ce sont les data analysts, data scientists et autres experts en analyse de données qui ont vocation à l’utiliser.
Dans quels domaines est utilisé le spectral clustering ?
Le partitionnement spectral permettant de traiter des données à grande échelle, cette méthode est souvent utilisée à des fins marketing. Les entreprises utilisent alors cet algorithme pour segmenter leurs cibles en fonction de leurs attentes, leurs besoins, leur profil, leur niveau de maturité, etc.
En outre, le spectral clustering peut aussi être utilisé en politique, en particulier en période d’élection. En séparant la masse d’électeurs en petits groupes, les candidats peuvent communiquer avec chacun d’entre eux de manière plus personnalisée.
Comment fonctionne l’algorithme spectral clustering ?
L’algorithme du clustering spectral se réalise en plusieurs étapes :
- La construction d’un graphe à travers la matrice par affinité (ou matrice par similarité, matrice adjacente) ;
- La segmentation des points de données dans des espaces dimensionnels plus petits ;
- L’utilisation des valeurs propres et vecteurs propres pour définir les sous-graphes.
Pour mieux comprendre son fonctionnement, nous vous expliquons les trois notions essentielles du spectral clustering.
Les graphiques

Les graphes sont un ensemble de nœuds reliés par un ensemble d’arêtes. Ces nœuds et ces arêtes peuvent être liés entre eux ou non.
Mais dans tous les cas, les graphes permettent de représenter de nombreux types de données.
Pour le spectral clustering, il faut partir d’un graphe ; soit de voisinage, soit des plus proches voisins (KNN), soit totalement connecté.
Ensuite, celui-ci est traduit sous forme de matrice. Plus précisément, la matrice adjacente.
Les matrices
La matrice adjacente (A) synthétise les relations entre tous les points de données du graphe.
Par exemple :
- Les données qui interagissent = 1
- Les données qui n’interagissent pas = 0
La matrice peut alors ressembler au tableau ci-dessous :
| 1 | 0 | 0 | 1 |
| 0 | 1 | 1 | 1 |
| 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 |
Ensuite, c’est la matrice de degré (D) qui intervient. En se fondant sur la matrice A, elle calcule la somme des liens (horizontaux et verticaux). Sur la base de l’exemple précédent, voici le résultat :
| 0 | 0 | 0 | 2 |
| 0 | 3 | 0 | 0 |
| 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 |
Enfin, la matrice Laplacienne (L) correspond à la matrice de degré moins la matrice adjacente, soit L=D-A.
| -1 | 0 | 0 | -1 |
| 0 | 2 | -1 | -1 |
| 0 | -1 | 1 | 0 |
| 1 | -1 | 0 | 0 |
Cette matrice est ensuite représentée visuellement sous la forme d’un graphe, que l’on appelle : graphe Laplacian.
Les vecteurs
La représentation visuelle du graphe Laplacian (A) implique de connaître les valeurs propres (eigenvalues= λ) et les vecteurs propres (eigenvectors=x).
Soit Ax = λx
Il est possible de trouver les eigenvalues et les eigenvectors d’une matrice en utilisant numpy sur Python.
L’utilisation de ces matrices et vecteurs permet ensuite de regrouper plusieurs sous-graphes en fonction de leurs similarités. L’une des méthodes les plus courantes pour le Spectral Clustering sera alors d’appliquer un algorithme plus classique de Clustering tel que la méthode des Kmeans sur les vecteurs propres de cette matrice. Cette méthode peut être directement implémentée à l’aide du module Spectral Clustering de la bibliothèque Sklearn. Quant aux valeurs propres, elles permettront de déterminer le nombre de clusters optimaux pour le partitionnement de vos données.
Bon à savoir : le nombre de sous-graphes (clusters) dépend de l’objectif et du degré de ciblage désiré. D’un point de vue macro, il est préférable d’avoir un nombre de clusters restreint pour une meilleure vision d’ensemble. Mais d’un point de vue micro, il est tout aussi intéressant d’aller dans le détail avec un maximum de sous-groupes.
Pourquoi utiliser le partitionnement spectral ?
L’utilisation du partitionnement spectral est absolument indispensable pour comprendre sa cible et s’adresser à elle de manière personnalisée.
Prenons l’exemple de personnes abonnées à une marque de vêtements (c’est la base de notre matrice adjacente). Ce n’est pas parce qu’elles présentent toutes une même affinité, qu’elles ont toutes le même profil.
Parmi les abonnés, on peut retrouver :
- Des clients fidèles ;
- Des prospects qui hésitent ;
- Des stylistes qui recherchent des sources d’inspiration ;
- Des professionnels du marketing qui effectuent une veille ;
- Etc.
Le spectral clustering permet alors de segmenter les données en petits sous-groupes de plus petites dimensions.
Pour les entreprises, connaître chaque sous-groupe permet d’adapter sa communication et son offre. Il s’agit de s’adresser aux bonnes personnes, au bon moment et de la bonne manière, afin de multiplier ses chances de convertir.
Et comme vu précédemment, les politiciens peuvent aussi utiliser cet algorithme pour convaincre leurs électeurs.
Quels sont les avantages et inconvénients du spectral clustering ?
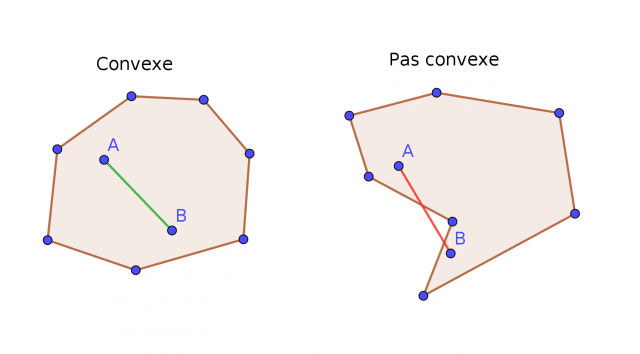
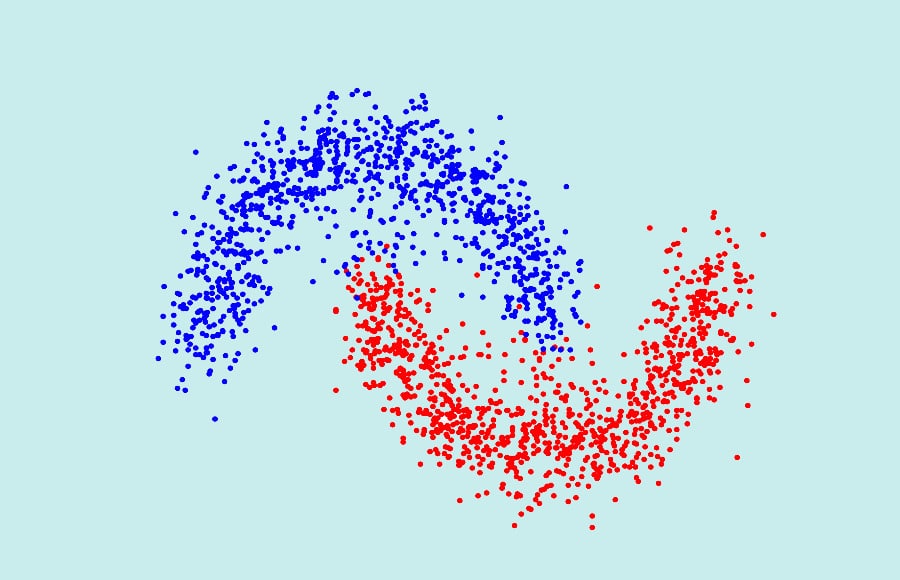
L’avantage incontestable du spectral clustering est sa capacité à classer un ensemble de données non convexes entre elles.
Cependant, il s’agit d’une notion complexe qui nécessite de bien comprendre son fonctionnement, mais aussi, et surtout, de maîtriser l’algèbre linéaire et la théorie spectrale des graphes.
Cela dit, l’outil numpy sur Python permet de faire les calculs afin de simplifier le travail des analystes.
Comment se former au spectral clustering ?
Le spectral clustering étant particulièrement complexe, il est primordial de bien se former pour comprendre son fonctionnement.
À ce titre, une formation d’excellence en data science vous permettra de maîtriser les outils nécessaires à la mise en place de cet algorithme.
Vous pourrez ensuite utiliser ces compétences dans les entreprises ou dans les institutions publiques pour les aider à améliorer leur communication, leurs offres et leurs performances.







