Para un tratamiento eficaz de datos secuenciales en Deep Learning y Machine Learning, es esencial entender las Gated Recurrent Units (GRUs), estas redes neuronales son capaces de recordar información clave a lo largo del tiempo.
Los datos que tienen una noción temporal son omnipresentes: texto, música, valores bursátiles, datos de sensores… El sentido de cada dato está determinado por los elementos que lo preceden: una palabra adquiere su significado completo en función de las palabras que la han precedido en una frase; la predicción de la temperatura de mañana se basa en las temperaturas observadas hoy y en días anteriores; o la identificación de un patrón en una señal de audio requiere analizar la secuencia sonora durante un cierto tiempo…
Las redes de neuronas clásicas no son adecuadas para este tipo de secuencias, ya que carecen de “memoria”.
La primera aproximación para manejar correctamente este tipo de datos fue el Recurrent Neural Networks (RNNs). Sin embargo, estos tienen dificultades para retener información lejana debido al vanishing gradient (los gradientes se encogen en cada capa del RNN, volviéndose cada vez más pequeños, tan pequeños que ya no permiten actualizar efectivamente los pesos de capas demasiado alejadas entre sí, perdiendo así información sobre el inicio de una secuencia al llegar al final de la misma).
Para superar esta limitación crucial y permitir que las redes de Deep Learning procesen eficientemente secuencias largas, se han desarrollado arquitecturas más sofisticadas de RNNs.
Entre las más efectivas y populares se encuentran las Gated Recurrent Units (GRUs).
Las GRUs son una mejora de los RNNs simples, diseñadas para manejar mejor la memoria, y por lo tanto la transmisión de información, durante largos períodos.
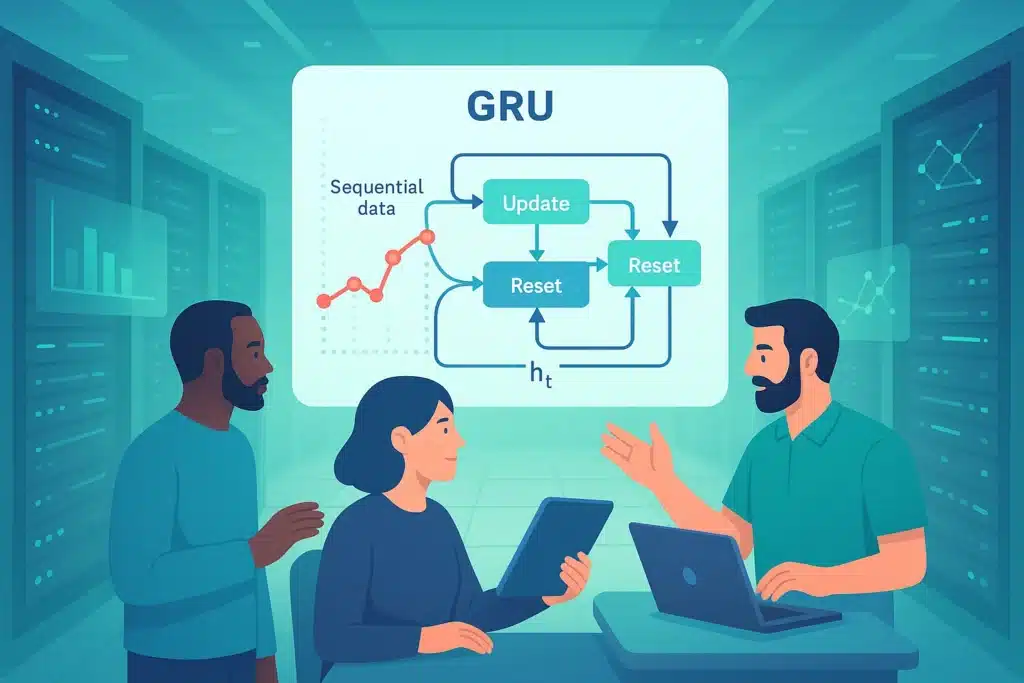
El mecanismo clave: Las Puertas (Gating Mechanism)
La innovación principal de las GRUs, y de los RNNs de su familia (como los LSTMs), reside en el uso de «puertas» (gating mechanism). En lugar de simplemente mezclar la entrada actual y el estado oculto anterior (previous hidden state h t-1) de manera bruta, como lo hace un RNN simple, las GRUs utilizan estas puertas para controlar selectiva y dinámicamente el flujo de información a través de la unidad recurrente.
Estas puertas actúan como filtros, basadas en funciones de activación (como la sigmoide por ejemplo), para decidir qué información de la antigua memoria y de la nueva entrada es más importante.
Un GRU utiliza dos puertas esenciales:
- La Puerta de Reinicio (Reset Gate): Esta puerta decide qué parte del estado oculto anterior es ignorad/a o «olvidada» al calcular un estado candidato potencial para el nuevo estado oculto.
- La Puerta de Actualización (Update Gate): Decide cuánto del estado oculto anterior debe ser conservado y cuánto del nuevo estado candidato (que representa la nueva información potencial a integrar) debe ser añadido para formar el nuevo estado oculto.
Estos mecanismos permiten al GRU retener o olvidar información durante períodos prolongados.
GRU vs LSTM
Los Long Short Term Memory (LSTMs) son muy similares a las GRUs, también utilizan “puertas” para manejar su memoria a largo plazo y atenuar el vanishing gradient.
La diferencia con las GRUs es que utilizan tres puertas, en lugar de solo dos para las GRUs, lo que los hace más complejos y más largos de entrenar.

Las ventajas de las GRUs
La principal ventaja de las GRUs frente a los RNNs clásicos, reside en su capacidad para capturar de manera efectiva las dependencias entre los datos de una misma serie, incluso si están más alejados. De hecho, gracias a las puertas, el GRU puede seleccionar de manera selectiva retener información relevante sobre secuencias muy largas e ignorar la que no lo es.
Por ejemplo, en una frase muy larga, un GRU puede aprender a mantener en la memoria el sujeto principal y el verbo, incluso si están separados por muchas palabras, para asegurar la coherencia gramatical y semántica al final de la frase. Esta capacidad los hace particularmente efectivos para comprender el contexto en largas series de datos.
Estas puertas permiten que los gradientes circulen más directamente a través del tiempo, evitando que se vuelvan demasiado pequeños (vanishing) cuando retroceden hacia las primeras capas de la red. Esto estabiliza el entrenamiento y permite que la red aprenda eficazmente los pesos que capturan las dependencias a largo plazo.
Los LSTMs también siguen estos principios. Sin embargo, las GRUs tienen una arquitectura más simple, con menos parámetros (menos puertas) que los LSTMs. Esto se traduce en una eficiencia computacional aumentada: generalmente son más rápidos de entrenar y de ejecutar, todo mientras alcanzan un rendimiento de punta en una amplia variedad de tareas secuenciales, a veces incluso superando a los LSTMs.
Lo cual es una ventaja significativa para las aplicaciones en tiempo real o cuando los recursos de cálculo son limitados.

¿Qué aplicaciones?
Las ventajas de las GRUs abren la puerta a numerosas aplicaciones concretas en diversos campos:
- Natural Language Processing (NLP) : Las GRUs son ampliamente utilizadas para tareas como la traducción automática, la generación de texto, el análisis de sentimientos, el reconocimiento de voz (speech recognition) y otras tareas donde la comprensión del contexto secuencial es crucial.
- Series Temporales (Time Series): También son eficaces para la predicción de valores futuros basados en un historial (previsiones financieras, meteorológicas, consumo de energía…).
- Modelado de Secuencias Diversas: Finalmente, se utilizan regularmente para generar Música, genomas y cualquier otro dato que se presente en forma de secuencia ordenada.
Conclusión
En resumen, las Gated Recurrent Units (GRUs) representan un avance significativo en comparación con los Recurrent Neural Networks (RNNs) simples.
Gracias a sus mecanismos de puertas inteligentes, manejan eficazmente la memoria a largo plazo y superan los problemas de entrenamiento de los RNNs simples, como el vanishing gradient.
Su eficiencia, su robustez y su buen rendimiento las convierten en una opción popular en Deep Learning y Machine Learning para una amplia variedad de aplicaciones.

