La gestion des Big Data est devenue un enjeu décisif pour les entreprises qui nécessitent d’avoir une forte visibilité sur le flux de données produites et de pouvoir répondre à des besoins spécifiques liés aux différents métiers. Ainsi dans les contextes professionnels les plus variés, l’accès à des données spécialisées et ordonnées selon des critères définis par les usagers et les spécialistes métiers devient essentiel et peut fournir des avantages compétitifs décisifs.
Le Datamart est l’outil qui permet de répondre à ce besoin : c’est pour cette raison que les entreprises multiplient leurs Datamart stratégiques.
Qu’est-ce qu’un Datamart ?
Le Datamart, ou magasin de données, est devenu un outil essentiel au sein d’un nombre grandissant d’entreprises pour garantir le traitement rapide de données de la part de leurs experts métier.
La force du Datamart consiste dans le fait qu’il regroupe des données spécialisées et destinées à des activités professionnelles spécifiques. Les professionnels peuvent donc y accéder et trouver rapidement dans une forme ordonnée les informations dont ils ont besoin afin de prendre des décisions, élaborer des stratégies commerciales, etc. Le datamart peut donc être considéré comme un sous-ensemble d’un Data Warehouse (ou entrepôt de données) destiné à des catégories spécifiques d’utilisateurs.
En effet, si le Data Warehouse rassemble toutes les données brutes produites par une entreprise afin de les trier et les organiser, le Datamart contient des données triées, agrégées, organisées selon des usages métiers ou des domaines spécifiques et est consulté par des professionnels ayant des besoin bien définis et connus au préalable.
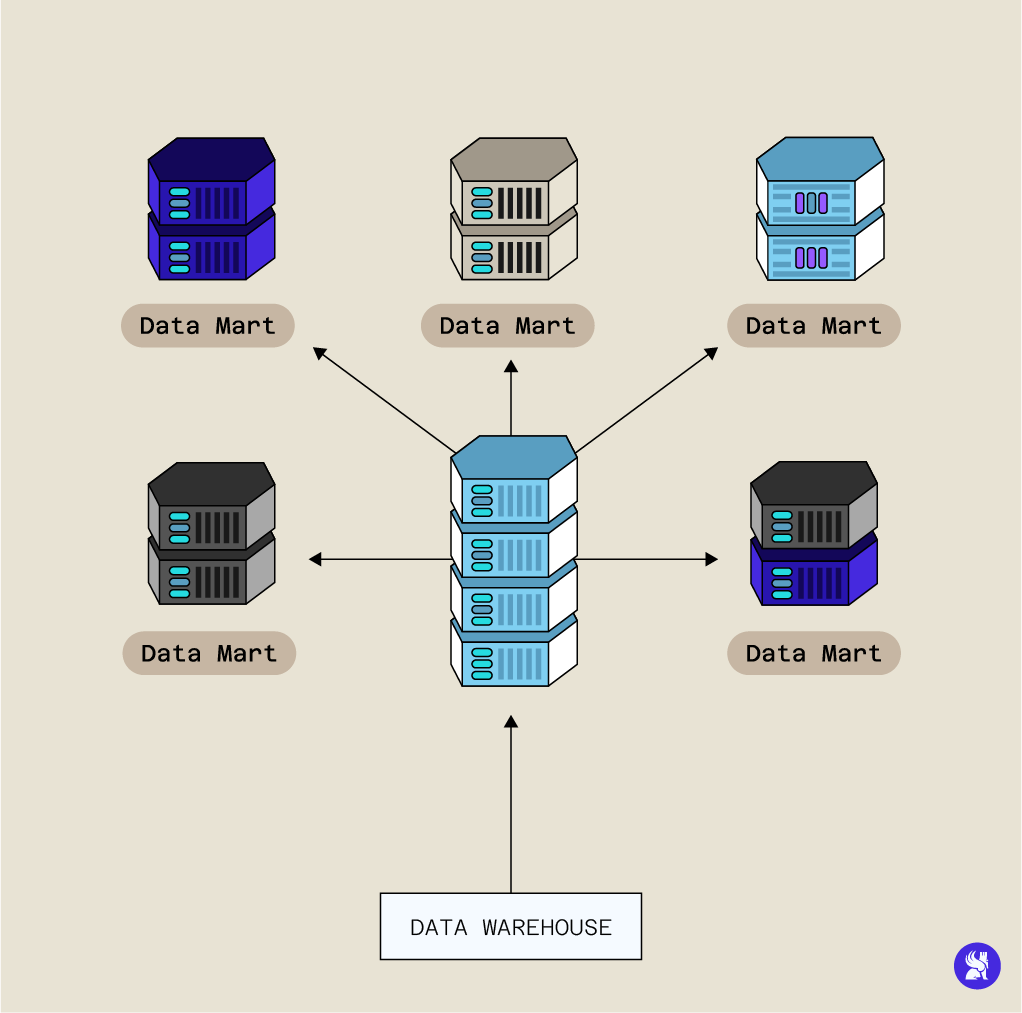
Quels sont les différents types de Datamart ?
Le fonctionnement du datamart a été théorisé selon deux écoles différentes par deux chercheurs en sciences informatiques : Bill Inmon et Ralph Kimball. La différence entre les deux écoles est le positionnement du Datamart au sein des bases de données des entreprises.
D’après Bill Inmon le datamart correspond à un flux de données qui vient du Data Warehouse est qui est trié selon des exigences spécifiques : le Datamart contient donc des données spécialisées destinées à être mobilisées par des experts métier.
Pour Bill Inmon le Datamart occupe une position périphérique au Data Warehouse. En revanche selon l’approche proposée par Ralph Kimball le datamart se trouve au cœur même du Data Warehouse : autrement dit selon cette dernière approche, le Data Warehouse serait elle-même composée de plusieurs datamart regroupant des données spécialisées agrégées.
Les deux approches convergent dans une vision du datamart comme un sous-ensemble spécialisé et ordonnée d’un Data Warehouse.
Les datamarts peuvent être classés en trois groupes en fonction de leur relation avec le Data Warehouse. Nous retrouvons des datamarts dépendants, indépendants et hybrides.
- Le Datamart dépendant est strictement connecté, il a été créé à partir du Data Warehouse dont il représente un sous ensemble.
- Le Datamart indépendant n’a pas été créé à partir du Data Warehouse et sa source peut être différente.
- Enfin le Datamart hybride permet d’intégrer des sources venant à la fois du Datamart principal et d’autres systèmes opérationnels.
Structure et avantages du Datamart
Les Datamart peuvent être structurés selon différents schémas. Les schéma les plus populaires sont le schéma en étoile et le schéma en flocon de neige. Le schéma en étoile présente l’avantage d’avoir besoin de moins de jointure lors de l’écriture des requêtes car il n’existe aucune dépendance entre les dimensions. D’autre part, la structure en flocon de neige demande moins d’espace de stockage, mais comporte une architecture plus complexe.
Les datamarts présentent des avantages importants qui ont favorisés leur popularité. Premièrement, ils permettent de travailler sur des portions plus petites et plus cohérentes de données. Cela facilite et rend plus rapide le travail de recherche et d’analyse.
En outre en organisant les données dans plusieurs blocs spécialisés et en les isolant de leurs sources on peut éviter la congestion du Data Warehouse: en effet avec un tel dispositif différents professionnels au sein d’une même entreprise peuvent chercher les informations dont ils ont besoin dans le Datamart dédié à leur corps de métier au lieu d’aller chercher dans le Data Warehouse.
En plus, grâce à une telle organisation, les utilisateurs peuvent avoir un accès rapide à des données de nature diverse en sachant dans quel Datamart elles sont classées. Grâce à son organisation et à ses dimensions réduites, la gestion et l’entretien d’un Datamart est beaucoup plus rapide et simplifiée que la gestion d’un Data Warehouse.
Un autre avantage du Datamart est lié à sa facilité d’usage : en effet les utilisateurs finaux peuvent avoir un accès facile aux informations sans nécessairement avoir une connaissance de l’ensemble des données du Data Warehouse et sans avoir à compiler de requêtes complexes.
Enfin, le fait que les données soient agrégées et organisées selon des critères définis au préalable, permet de réaliser des analyses rapides des principales tendances et donc de pouvoir adopter rapidement des stratégies opérationnelles.
Comment construire un Datamart ?
Souvent un Data Scientist peut travailler à partir d’un datamart constitué au préalable. D’autres fois il peut être appelé à en créer un afin de favoriser le traitement de données et la prise de décision au sein de son entreprise.
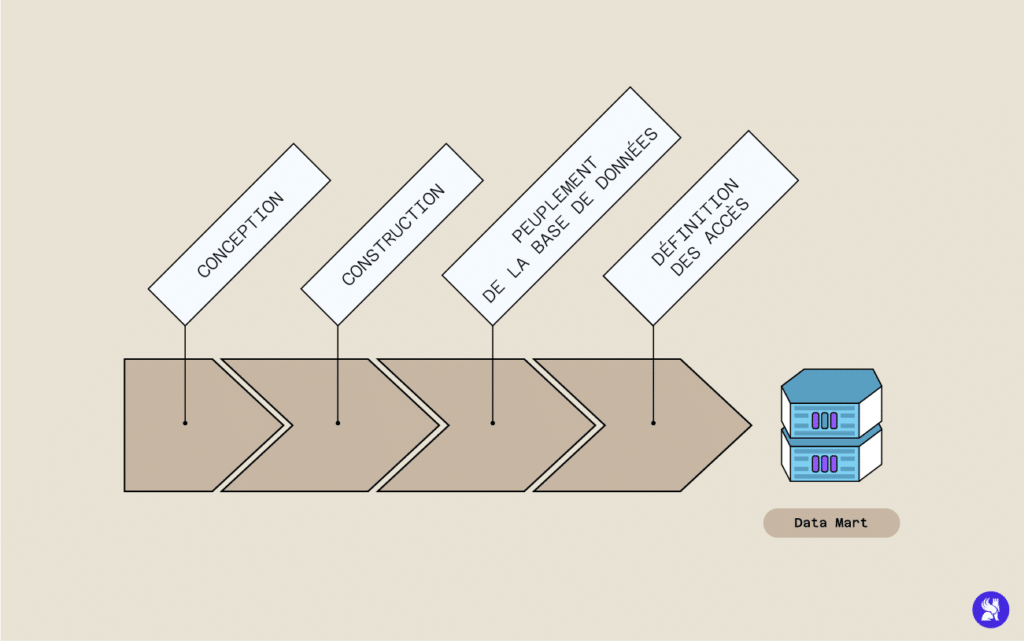
Être capable de mobiliser les compétences nécessaires pour créer un Datamart est donc un atout important pour un Data Scientist confirmé ou pour un débutant. Afin de créer un Datamart, le Data Scientist peut procéder par étapes.
- Premièrement, il doit concevoir un Datamart robuste, accessible et fonctionnel. Pour ce faire, il doit recenser à la fois les données produites par l’entreprise, leurs différentes sources et les principaux besoins des différents métiers. Il définit alors les sous-ensemble dans lesquels regrouper les données, à savoir leur schéma de base. Il organise par la suite la disposition logique des schémas et leur structure physique.
- Après le travail de conception, le Data Scientist commence à construire la base de données et sa structure logique. C’est au cours de cette étape qu’il va créer les tables, les index et les contrôles d’accès.
- La troisième étape consiste à remplir le datamart en y transférant les données à partir des différentes sources : le Data Scientist doit faire attention à nettoyer et organiser les données avant de les intégrer dans le datamart.
- La quatrième étape consiste à créer la structure permettant un accès simple et fonctionnel aux données de la part des experts métiers. Éventuellement le Data Scientist peut configurer une API ou des interfaces facilitant l’usage et l’accès aux données.
- Enfin le Data Scientist doit s’occuper de la gestion du Datamart en contrôlant les accès, en ajoutant des nouvelles données pertinentes et en gérant les pannes.
En vous formant au métier de Data Scientist vous apprendrez à mobiliser toutes ces compétences pour favoriser la gestion des données de votre entreprise.








