
Le Kernel est une méthode de classification de Machine Learning. Découvrez tout ce que vous devez savoir à ce sujet, et comment suivre une formation pour devenir Data Scientist ou Data Analyst.
Le Kernel qu'est-ce que c'est ?
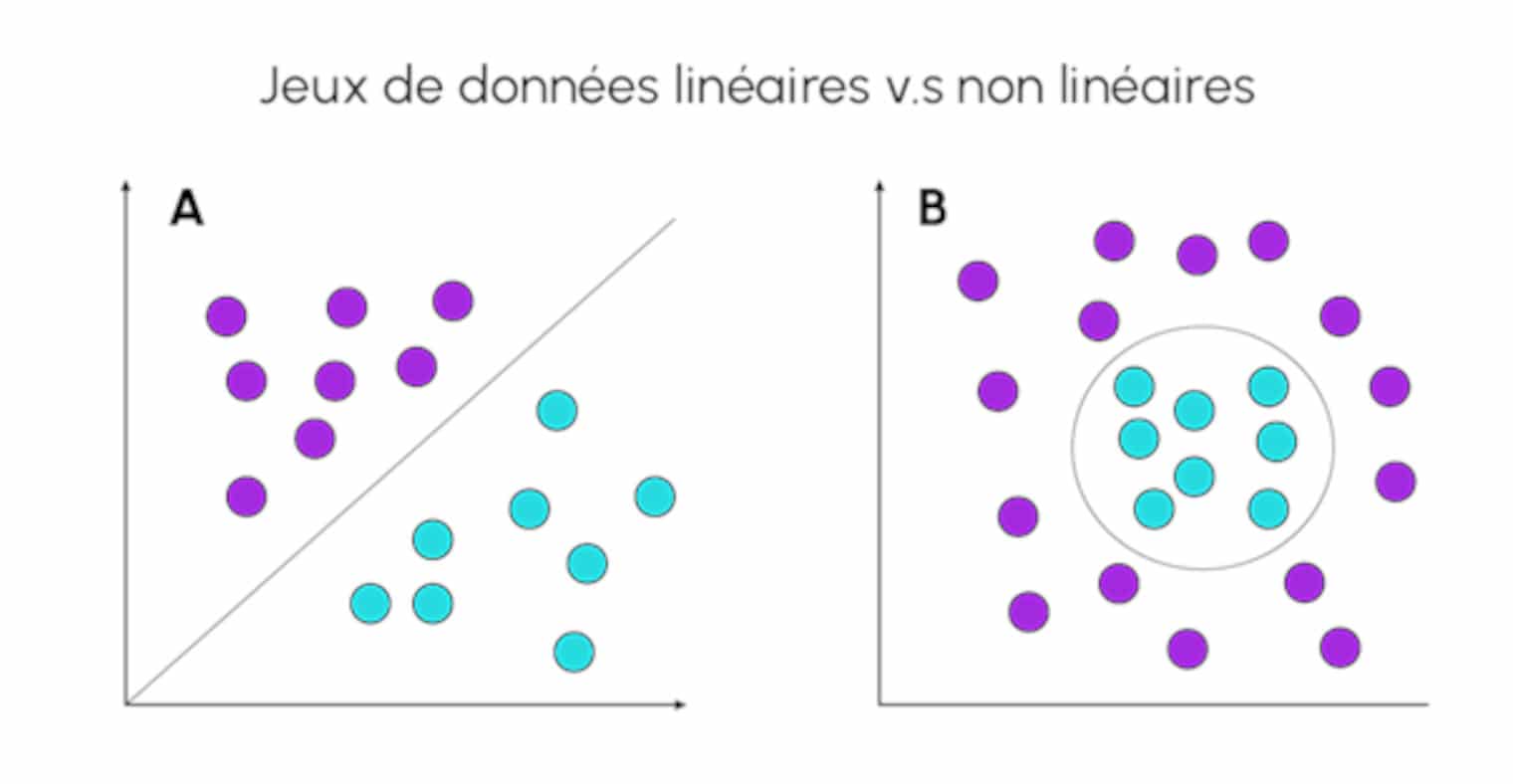
Dans le domaine du Machine Learning, la méthode Kernel consiste à utiliser un classificateur linéaire pour résoudre un problème non-linéaire. Pour y parvenir, on transforme un set de données linéairement inséparable en un ensemble linéairement séparable comme dans l’exemple ci-dessous en la passant dans un espace à dimension supérieure.
A quoi sert le Kernel ?
Le kernel se révèle par exemple très utile pour séparer deux classes au sein d’un ensemble de données à deux dimensions, où les données ne sont pas séparables linéairement.
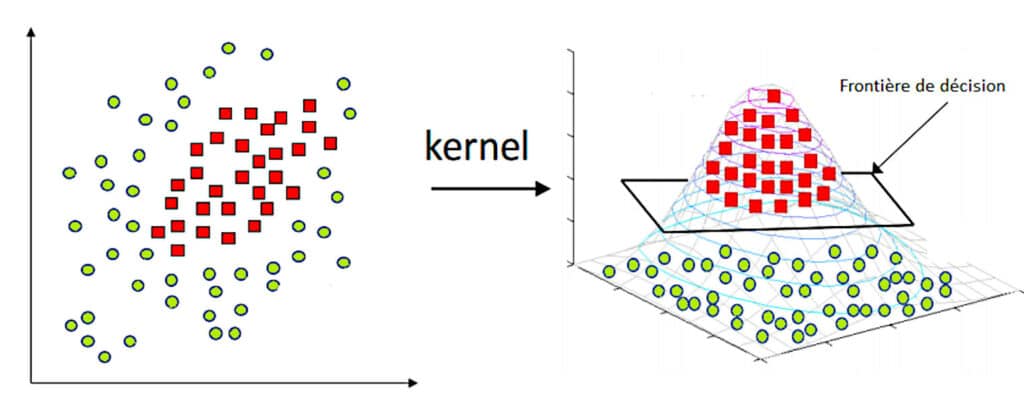
L’utilisation d’une fonction polynomiale compliquerait le problème de classification. Il est donc préférable de transformer les données dans un espace 3D où les données deviennent séparables par un classificateur linéaire.
Il devient alors possible de transformer les données de la 2D vers la 3D, de trouver une frontière de décision linéaire en adaptant le classificateur linéaire dans l’espace 3D, et de cartographier la frontière de décision linéaire à nouveau dans l’espace 2D pour créer une frontière de décision non-linéaire en 2D.
Où utilise-t-on le Kernel ?
Il existe différents algorithmes basés sur le kernel en Machine Learning, comme la Fonction de Base Radiale Régularisée (Rdg RBFNN), la Machine à Vecteurs de Support (SVM), l’analyse de discriminant Kernel-Fisher (KFD), ou encore l’Adaboost régularisé (Reg AB). Parmi ces modèles, l’approche la plus utilisée est la Machine à Vecteurs de Support (SVM).
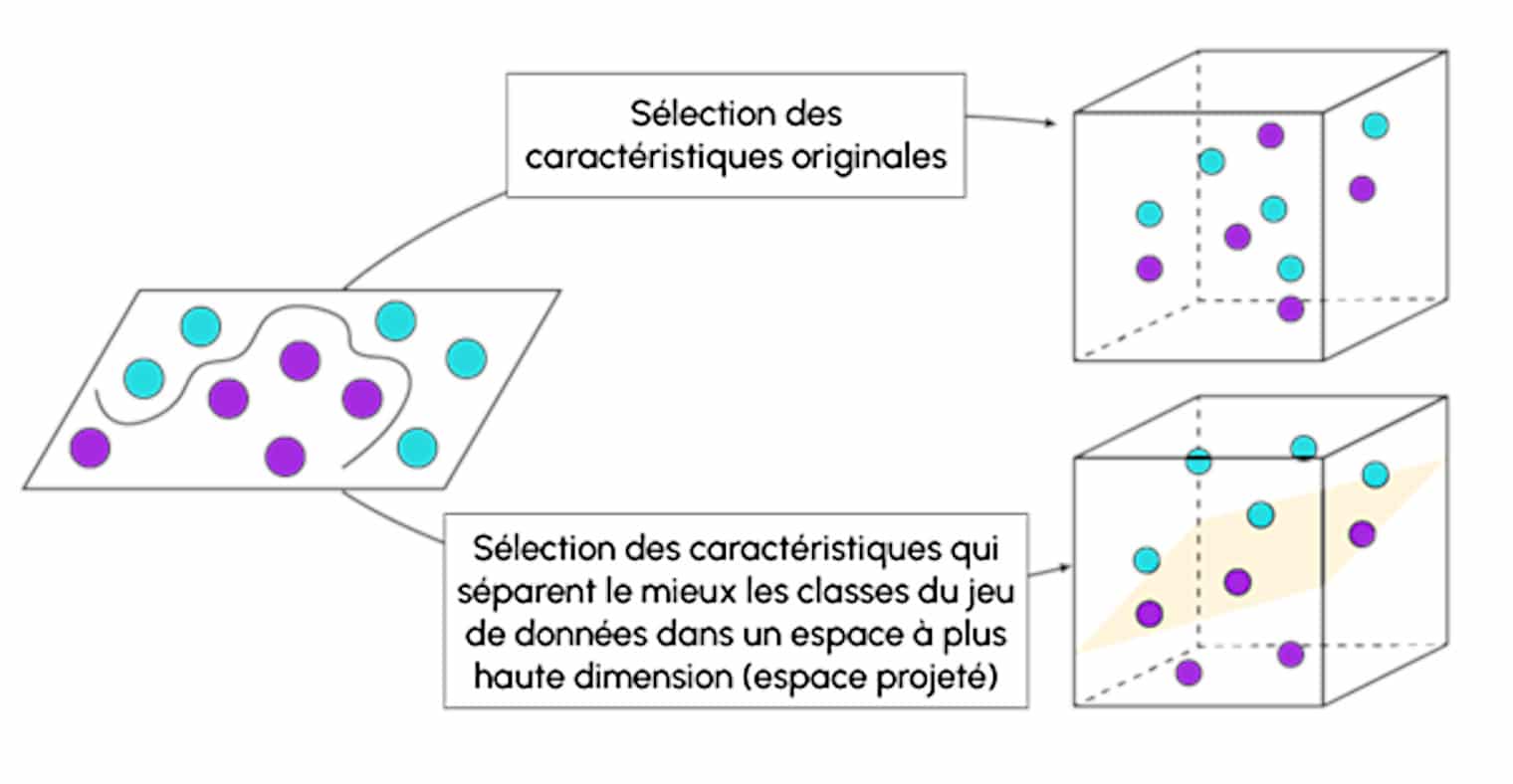
On distingue le SVM linéaire classique pour la classification linéaire, du SVM non-linéaire pour lequel on utilise le Kernel afin de cartographier les patterns des dimensions des plus basses aux plus hautes.
Cette méthode permet de traiter les données linéairement inséparables et de créer des combinaisons non linéaires des caractéristiques originales vers un espace à plus haute dimension via une fonction de mapping où la séparation linéaire devient possible. Le kernel le plus utilisé pour SVM est le kernel RBF ou le kernel Gaussien.
Peut-on se former au Kernel ?
Pour apprendre les méthodes de Machine Learning, vous pouvez choisir un des programmes proposé par DataScientest. Plusieurs de nos formations comportent un module entièrement dédié à l’apprentissage automatique.
Le module Machine Learning du cursus Data Analyst aborde les méthodes de clustering et de régression avec Scikit-learn. Les autres modules de cette formation couvrent les sujets de programmation, la DataViz, les bases de données et la Business Intelligence. À la fin du parcours, vous aurez toutes les compétences requises pour exercer le rôle de Data Analyst.
Notre formation Data Scientist comporte quant à elle deux modules dédiés au Machine Learning. Le premier aborde le Machine Learning supervisé avec les méthodes de régression et la classification simple et avancée. Tandis que le deuxième se concentre sur l’apprentissage non-supervisé (ou unsupervised learning) contenant les méthodes de clustering et de réduction de dimension. Les sujets de Statsmodel, Text Mining et NetworkX sont également à l’étude dans ce cursus. Les autres modules du programme sont dédiés à la programmation, la DataViz, le Deep Learning et l’IA. Ce cursus permet d’acquérir toutes les compétences nécessaire au poste de Data Scientist.
Pour aller plus loin, nous proposons aussi un cursus expert de Machine Learning Engineer. Cette formation continue de 7 mois ou en temps partiels de 16 mois vient compléter la formation Data Scientist. Elle permet d’apprendre à mettre en production les modèles de Machine Learning grâce aux techniques d’ingénierie, ce qui représente une compétence très convoitée en entreprise.
Toutes nos formations s’effectuent en ligne, et se composent de 85% d’apprentissage en asynchrone sur notre plateforme coachée et de 15% de cours à distance (synchrones).
Hormis les cursus expert, nos programmes peuvent être complétés en Formation Continue ou en Bootcamp intensif.
Concernant le financement, tous nos cursus sont éligibles au Compte Personnel de Formation. N’attendez plus et découvrez les formations DataScientest !









