MapReduce est le modèle de programmation du framework Hadoop. Il permet d'analyser les immenses volumes de données Big Data grâce au traitement parallèle. Découvrez tout ce que vous devez savoir : présentation, fonctionnement, alternatives, avantages, formations...
Les volumes massifs du Big Data offrent de nombreuses opportunités pour les entreprises. Toutefois, il peut être difficile de traiter ces données de manière rapide et efficace sur des systèmes traditionnels. Il est nécessaire de se tourner vers de nouvelles solutions spécialement conçues à cet effet.
Le modèle de programmation MapReduce fait partie de ces solutions. Il fut initialement créé par Google pour analyser les résultats de son moteur de recherche. Avec le temps, cet outil est devenu extrêmement populaire pour sa capacité à décomposer des terabytes de données pour les traiter en parallèle. Cette approche permet d’obtenir des résultats plus rapidement.
Qu'est-ce que MapReduce ?
Le modèle de programmation MapReduce est l’un des principaux composants du framework Hadoop. Il est utilisé pour accéder aux données Big Data stockées au sein du Hadoop File System (HDFS).
L’intérêt de MapReduce est de faciliter le traitement concurrent des données. Pour parvenir à cette prouesse, les volumes massifs de données, de l’ordre de plusieurs petabytes, sont décomposés en plusieurs parties de moindres envergures.
Ces morceaux de données sont traités en parallèle, sur les serveurs Hadoop. Après le traitement, les données en provenance des multiples serveurs sont agrégées pour renvoyer un résultat consolidé à l’application.
Hadoop est capable d’exécuter des programmes MapReduce écrits dans divers langages : Java, Ruby, Python, C++…
L’accès et le stockage des données sont basés sur disque. Les » input » (entrées) sont stockées sous forme de fichiers contenant des données structurées, semi-structurées ou non structurées. Le » output » (sortie) est aussi stockée sous forme de fichiers.
Prenons pour exemple un ensemble de données de 5 terabytes. Si l’on répartit le traitement sur un cluster Hadoop de 10 000 serveurs, chacun doit traiter environ 500 megabytes de données. Le dataset complet peut donc être traité beaucoup plus rapidement qu’avec un traitement séquentiel traditionnel.
Fondamentalement, MapReduce permet d’exécuter la logique directement sur le serveur où résident les données. Cette approche s’oppose à celle d’envoyer les données à l’emplacement où réside la logique ou l’application. C’est ce qui permet d’accélérer le traitement.
Les alternatives à MapReduce : Hive, Pig...
Jadis, MapReduce était la seule méthode permettant de récupérer les données stockées dans HDFS. Ce n’est plus le cas aujourd’hui. Il existe d’autres systèmes basés sur les requêtes, comme Hive et Pig.
Ces derniers permettent de récupérer les données depuis HDFS grâce à des requêtes SQL. La plupart du temps, toutefois, elles sont exécutées aux côtés de jobs écrits avec le modèle MapReduce pour tirer profit de ses multiples avantages.
Comment fonctionne MapReduce ?
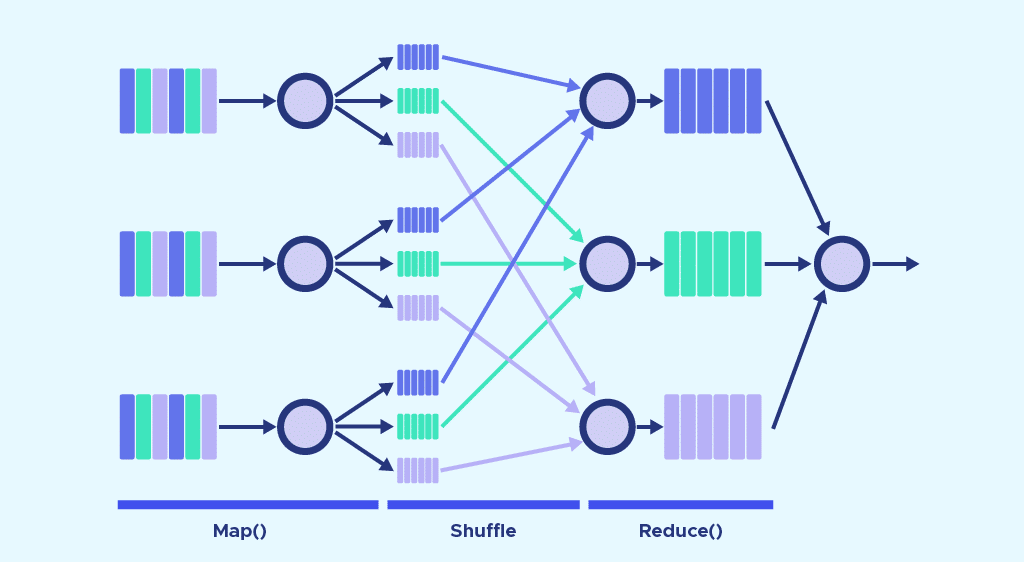
Le fonctionnement de MapReduce s’articule principalement autour de deux fonctions : Map, et Reduce. Pour faire simple, Map sert à décomposer et à cartographier les données. Reduce mélange et réduit les données.
Ces fonctions sont séquencées l’une après l’autre. Pour désigner les serveurs exécutant les fonctions Map et Reduce, on utilise les termes de Mappers et Reducers. Il peut toutefois s’agir des mêmes serveurs.
La fonction Map
Les données d’input sont décomposées en blocs de moindre envergure. Chacun de ces blocs est assigné à un » mapper » pour le traitement.
Prenons l’exemple d’un fichier contenant 100 enregistrements à traiter. Il est possible d’utiliser 100 mappers simultanément pour traiter chaque enregistrement séparément. Toutefois, on peut aussi confier plusieurs enregistrements à chaque mapper.
En réalité, le framework Hadoop se charge de décider automatiquement combien de mappers utiliser. Ce choix dépend de la taille des données à traiter et des blocs de mémoire disponibles sur chaque serveur.
La fonction Map reçoit l’input à partir du disque sous forme de paires » clé/valeur « . Ces paires sont traitées, et un autre ensemble de clé/valeur intermédiaire est produit.
La fonction Reduce
Après que tous les mappers aient terminé leurs tâches de traitement, le framework mélange et organise les résultats. Il les transmet ensuite aux » reducers « . Précisons qu’un reducer ne peut démarrer si un mapper est encore actif.
La fonction Reduce reçoit aussi les inputs sous forme de paires clé/valeur. Toutes les valeurs produites par map ayant la même clé sont assignées à un reducer unique. Celui-ci se charge d’agréger les valeurs pour cette clé. Reduce produit ensuite un ouput final, toujours sous forme de paie clé/valeur.
Toutefois, le type de clés et de valeurs varie selon les cas d’usage. Tous les inputs et outputs sont stockés dans le HDFS. Précisons que la fonction map est impérative pour filtrer et trier les données initiales. En revanche, la fonction reduce est optionnelle.
Combine et Partition
Il existe deux étapes intermédiaires entre Map et Reduce. Ces deux étapes sont appelées Combine et Partition.
Le processus Combine est optionnel. Un » combiner » est un » reducer » exécuté individuellement sur chaque serveur » mapper « . Il permet de réduire davantage les données sur chaque mapper, dans une forme simplifiée. Ceci permet de simplifier le shuffling et l’organisation, puisque le volume de données à organiser est réduit.
L’étape de Partition permet quant à elle de traduire les paires » clé valeur « produites par les mappers en un autre ensemble de paires clé valeur avant de les transmettre au reducer. Ce processus décide comment les données doivent être présentées au reducer et les assignent à un reducer spécifique.
Le partionneur par défaut détermine la valeur » hash « pour la clé produite par le mapper, et lui assigne une partition en fonction de cette valeur. Le nombre de partitions est égal au nombre de reducers. Dès que le partitionnement est complet, les données en provenance de chaque partition sont envoyées à un reducer spécifique.
Exemples de cas d'usage
Le paradigme de programmation MapReduce est idéal pour n’importe quel problème complexe pouvant être résolu grâce à la parallélisation. Il s’agit donc d’une approche adéquate pour le Big Data.
Les entreprises peuvent s’en servir pour déterminer le prix optimal de leurs produits ou pour connaître l’efficacité d’une campagne publicitaire. Elles peuvent analyser les clics, les ventes en ligne ou les tendances Twitter pour décider quel produit lancer afin de répondre à la demande des consommateurs.
Alors que ces calculs étaient jadis très compliqués, MapReduce les rend aujourd’hui simples et accessibles. Il est possible d’effectuer ces fonctions sur un réseau de serveurs peu coûteux, et le traitement du Big Data s’en trouve aussi largement moins cher.
Quels sont les avantages de MapReduce ?
L’utilisation de MapReduce présente de nombreux avantages. Tout d’abord, ce modèle de programmation rend Hadoop hautement extensible en permettant le stockage de larges ensembles de données sous une forme distribuée entre de multiples serveurs.
C’est ce qui rend possible le traitement parallèle. Les tâches Map et Reduce sont séparées, et l’exécution parallèle réduit le run time dans son ensemble.
Il s’agit aussi d’une solution économique pour le stockage et le traitement des données. Le rapport performances / prix est inégalable.
Avec MapReduce, Hadoop est aussi extrêmement flexible. Il est possible de stocker et de traiter des données en provenance de différentes sources, et même des données non structurées.
La vitesse est aussi l’un des principaux points forts. Le système de fichiers distribué permet de stocker les données sur le disque local d’un cluster et les programmes MapReduce sur les mêmes serveurs. Les données peuvent donc être traitées plus rapidement, puisqu’il n’est pas nécessaire d’y accéder à partir d’autres serveurs.
Comment apprendre à utiliser MapReduce ?
Dans tous les secteurs, les entreprises collectent de plus en plus de données. Elles ont donc besoin de traiter ces données pour en tirer profit, et MapReduce fait partie des principales solutions.
Par conséquent, apprendre à maîtriser Hadoop et MapReduce offre de nombreuses opportunités professionnelles. Il s’agit d’une compétence très recherchée.
Pour acquérir la maîtrise de cet outil, vous pouvez vous tourner vers DataScientest. Le framework Hadoop et ses différents modules sont au coeur de notre formation Data Engineer, au sein du module » Big Data Volume « .
Vous apprendrez notamment à utiliser Hadoop, Hive, Pig, Hbase et Spark et découvrirez tout l’aspect théorique des architectures Big Data. Les autres modules de ce cursus abordent la programmation en Python, les bases de données, le Big Data Vitesse et enfin l’automatisation et le déploiement.
À l’issue de ce parcours, vous aurez toutes les compétences requises pour commencer à travailler directement comme Data Engineer. Ce métier est en plein essor, et vous garantit de trouver un emploi avec un salaire élevé dans le domaine de votre choix.
Comme toutes nos formations, le parcours Data Engineer adopte une approche Blended Learning alliant apprentissage en présentiel et à distance. Il peut être effectué en Formation Continue on en mode BootCamp intensif.
Après avoir complété ce programme, les apprenants reçoivent un diplôme certifié par l’Université de la Sorbonne. Parmi les alumnis, 93% ont trouvé un travail immédiatement. Ne perdez plus un instant et découvrez la formation Data Engineer.
Vous savez tout sur MapReduce. Découvrez notre dossier complet sur Hadoop, et notre introduction au langage de programmation Python.








