
La reconnaissance optique de caractères (ROC ou Optical Character Recognition en anglais), appelée également océrisation, regroupe l’ensemble des méthodes qui permettent de générer des fichiers textes à partir d’images contenant du texte manuscrit. Avec l’avènement du numérique et de l’automatisation, l’océrisation est devenue un outil incontournable car les images comportant du texte ne sont pas exploitables par un ordinateur.
1. Un peu d’histoire
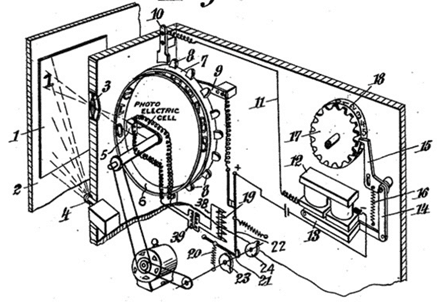
La première version d’une machine capable de reconnaître des caractères dans un document manuscrit fut mise au point par Gustav Tauschek en 1929, un ingénieur allemand. Le principe était le suivant. Un document contenant un texte manuscrit était positionné devant la fenêtre de la machine. Ensuite, pour détecter le bon caractère, une roue comportant des trous de la forme des lettres tournaient jusqu’à ce que l’image du caractère et le trou coïncident parfaitement grâce à un photodétecteur. Une fois le caractère détecté, il était écrit une feuille de papier.
2. Utilisation du Deep Learning pour l’océrisation
On peut facilement constater que faire de l’océrisation à l’aide de machines mécaniques, aussi performantes qu’elles soient, peut s’avérer très coûteux et assez long. Les entreprises qui souhaitent automatiser leur pipeline de digitalisation ont besoin d’un outil rapide et efficace de reconnaissance d’écriture manuscrite. Grâce au développement du Deep Learning notamment dans la domaine du traitement de l’image, il existe aujourd’hui des algorithmes capables de résoudre des problèmes d’océrisation. Le modèle OCR se décompose en 2 étapes : la détection et la reconnaissance du texte.
- La première est le processus qui permet de détecter les zones de textes dans un document et peut s’avérer être une tâche vraiment compliquée car les documents peuvent avoir une structure très différente. Les zones de textes ne seront pas au même endroit entre un roman et un journal par exemple.
- La deuxième permet de reconnaître le texte pour une zone du document en contenant.
3. Détection de texte à l’aide du Deep Learning
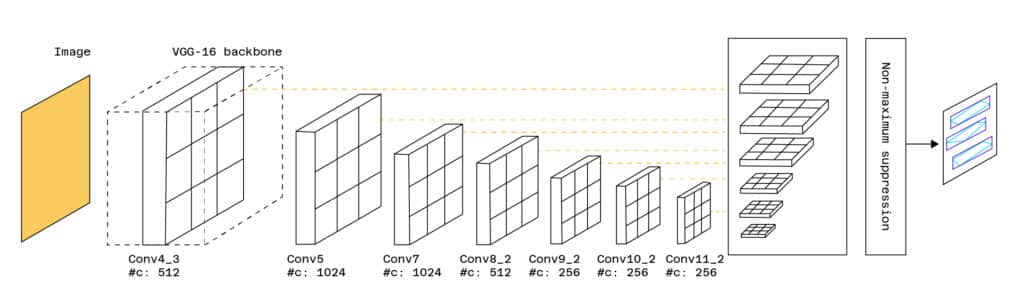
Il existe plusieurs méthodes pour détecter du texte au sein d’un document. Certaines d’entre elles s’inspirent de modèles de détection d’objets (Single Shot Box Detection, Faster-RCNN) qui sont utilisés pour détecter des visages, des voitures, etc. dans une image. Ce type de modèle renvoie une Bounding Box qui n’est autre qu’un cadre qui entoure l’objet à détecter. Pour détecter du texte, ces modèles sont modifiés et adaptés. On pourra citer le modèle TextBoxes qui s’appuie sur le modèle SSD (Single Short Detector) tout en ajoutant des Bounding Boxes plus spécifiques à la détection de texte. Le modèle renvoie les zones de l’image contenant du texte.
Il existe aussi d’autres méthodes de détection basées sur la segmentation. La segmentation est un procédé qui permet de décomposer une image en plusieurs zones appelées classes qui comportent des éléments similaires. En voici un exemple :

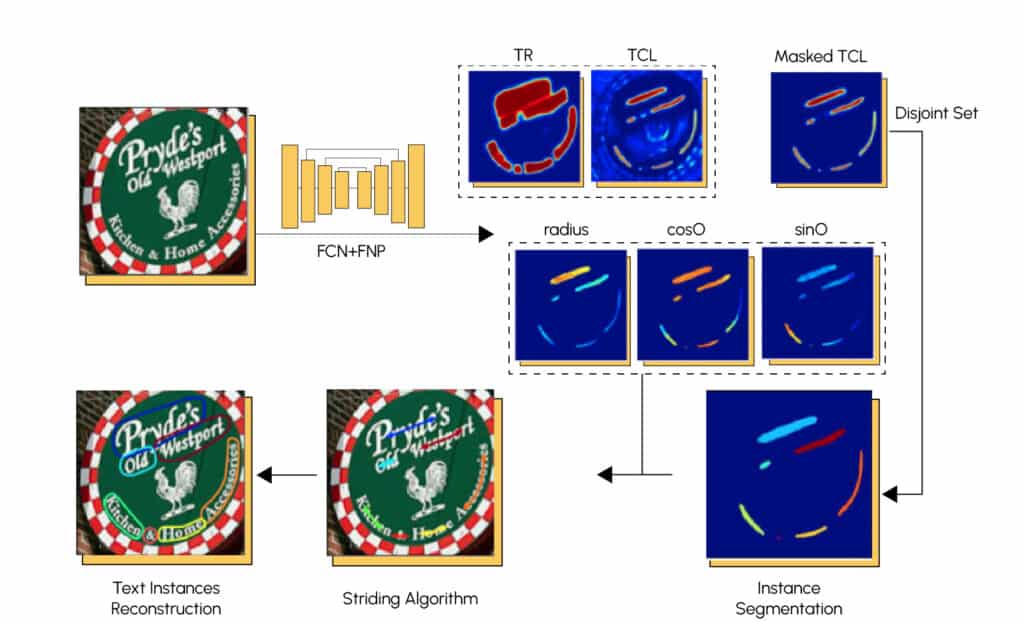
Pour la segmentation de texte, on utilise souvent des réseaux de neurones convolutifs (FCN) ainsi que des réseaux de neurones pyramidaux (FPN). Voici l’architecture d’un modèle très performant appelé TextSnake.
4. Reconnaissance de texte à l’aide du Deep Learning
Nous venons de voir la première étape d’un modèle d’océrisation qui est la détection des zones du document comportant du texte. Une fois cette étape réalisée, il faut reconnaître les caractères qui composent ces zones pour en déduire des mots et ainsi traduire le document manuscrit en un format texte exploitable. Les modèles de Machine Learning les plus utilisés pour résoudre les problèmes de reconnaissance texte sont les réseaux de neurones récurrents. Leurs avantages sont que les couches cachées qui les composent partagent une bande mémoire en commun ce qui a pour conséquence d’influencer la prédiction en fonction des précédentes prédictions. Si vous voulez en savoir plus sur leur fonctionnement, un article complet sur les réseaux de neurones récurrents est disponible sur notre blog. Les couches les plus utilisées pour les modèles de réseaux de neurones récurrents sont les LSTMs et les GRUs. Nous ajoutons à ces couches récurrentes des couches convolutionnelles. La convolution permet d’extraire des caractéristiques pertinentes et locales des images comportant du texte et les couches récurrentes permettent d’attribuer des labels correspondant aux caractères présents sur l’image. Pour chaque caractéristique créée par la convolution va être associée un vecteur probabilité d’appartenance à chaque label.
On peut résumer la reconnaissance de texte grâce au schéma suivant :

Il ne faut pas oublier qu’il doit y avoir une partie détection de texte en amont pour que la partie reconnaissance fonctionne correctement.
Sur cet exemple, on voit que l’image donnée en entrée représente le texte “a b”. La partie
convolution va décomposer l’image en feature map, aussi appelée carte des caractéristiques. On voit qu’ici l’image a été découpée en 5 séquences. Les couches récurrentes vont ensuite associer une probabilité de classe à chaque séquence. Il y a autant de classes que de caractères possibles (lettres de l’alphabet, caractères spéciaux, …). Pour chaque séquence, on choisit la classe qui maximise la probabilité, on obtient une suite de caractères et on peut ensuite en déduire notre texte final.
Cependant, ce modèle ne permet pas de vérifier que le mot ou la phrase retournée en sortie soit sans faute d’orthographe car on prédit caractère par caractère sans se soucier de cela. Il existe d’autres modèles qui mettent en place un système de correction orthographique. Cette approche s’appelle un modèle de langage, et peut améliorer la précision de notre modèle.
5. Conclusion
Nous venons de voir un modèle de Deep Learning permettant de résoudre le problème de l’océrisation. Le Deep Learning a vraiment révolutionné ce domaine car il offre des prédictions très précises contrairement aux modèles qui avaient été mis au point auparavant. On peut remarquer que le modèle utilise des techniques normalement utilisées dans d’autres domaines comme la détection d’objets dans une image ou encore le Natural Language Processing et que ces techniques fonctionnent très bien pour l’océrisation.
Si vous avez aimé cet article et que vous voulez découvrir d’autres méthodes de Deep Learning, je vous invite à rejoindre notre cursus expert en Deep Learning.







