Il est fort probable que vous utilisiez des applications qui font appel à des modèles de Deep Learning dans votre quotidien. En effet, traduction, ocr, reconnaissance faciale… Diverses de vos applications intègrent l’apprentissage profond.
Cette application du Deep Learning à été rendue possible grâce à la disponibilité des quantités importantes de données dont ont besoin les algorithmes pour être efficace ainsi que l’avancement de la puissance de calcul des machines qui permet l’entraînement de ces algorithmes.
Il est possible de construire des modèles de Deep Learning et de les entraîner sous plusieurs langages, mais dans cet article, nous utiliserons Python et ses librairies conçues spécialement pour le Deep Learning : Tensorflow et Keras.
Keras est une librairie open source conçue pour fournir tous les outils essentiels à l’expérimentation des réseaux de neurones. Il est nécessaire d’avoir la librairie installée sur votre environnement de travail. L’environnement Google Colab fournit l’essentiel des prérequis du Deep Learning et de la Data Science.
Entraînez votre premier réseau de neurones
Maintenant que vous avez pris connaissance des outils à utiliser pour faire du Deep Learning, il est temps de mettre les mains à la pâte et de construire, entraîner et évaluer votre premier modèle de Deep Learning.
Mais pour cela vous ne serez pas seuls, nous avons conçu pour vous un tutoriel qui traite les étapes principales que suit un Data Scientist pour entraîner un réseau de neurones. Nous expliquerons ces étapes afin que vous puissiez effectuer le processus pour vos futures modélisations.
Ouvrez d’abord votre Notebook Jupyter ou Colab pour attaquer la première étape. Vous pourrez simplement copier les cellules sur votre Notebook mais nous vous conseillons vivement de coder vous-même afin de mieux assimiler la syntaxe. Rappelez-vous que c’est en pratiquant que l’on apprend.
Chargement des données :
Il est bien connu que pour réaliser un projet de Deep Learning (ou pour faire de la Data Science en générale), il est nécessaire d’avoir une quantité importante de données. Donc la première étape et naturellement la sélection et l’import de nos données.
L’ensemble de données que nous allons utiliser est très connu par les data scientists, il s’agit du Dataset MNIST, ce dernier rassemble près de 60000 images de 28×28 pixels de nombres écrits à la main avec les nombres en numérique comme variable cible. L’objectif de notre modèle sera de reconnaître le nombre écrit sur l’image.
Vous trouverez sur le scripte l’import des librairies nécessaires à notre modélisation. Vous remarquerez aussi que le dataset est inclus dans le module Keras et qu’on a deux différents ensembles de données, la partie entrainement (train) et la partie teste (test)
Vous aurez comme résultat d’exécution de cette première cellule la taille de la dataset ainsi que les dimensions des images.
Ici nous allons jeter un coup d’œil sur un échantillons aléatoire d’images avec leurs labels correspondant.
Voici un exemple d’exécution de la cellule ci-dessus.
Prétraitement des données
Après le chargement de vos données, vous devez vous assurer qu’elles soient prêtes pour la phase d’entraînement. Pour cela vous appliquerez quelques transformations à ces dernières. Notamment redimensionner, normaliser et encoder les données.
Mais pas de panique, encore une fois nous vous accompagnerons dans le processus et chaque prétraitement sera expliqué.
- Redimensionnement : Une particularité des algorithmes de machine learning et deep learning est qu’ils ne prennent pas de matrices en entrée. Ce qui vous amène à transformer vos matrices de 28×28 en vecteurs de taille 784.
- Normalisation : Cette étape n’est pas obligatoire pour l’entraînement de votre modèle mais peut booster sa performance, la normalisation est appliquée en divisant chaque pixel par 255. Consultez cet article pour en apprendre plus sur la normalisation.
- Encodage : La transformation des labels en vecteurs catégoriels permet d’améliorer la précision de prédiction.
Définition du modèle :
Maintenant que vos données sont (vraiment) prêtes, vous pouvez passer à la modélisation de votre réseau de neurones. C’est là que vous allez construire votre modèle couche par couche.
Encore une fois, vous n’êtes pas seuls pour la réalisation. Nous allons vous accompagner dans la modélisation du réseau ci-dessous.

input et output : même couleur
couches milieu : même couleur
exemple :
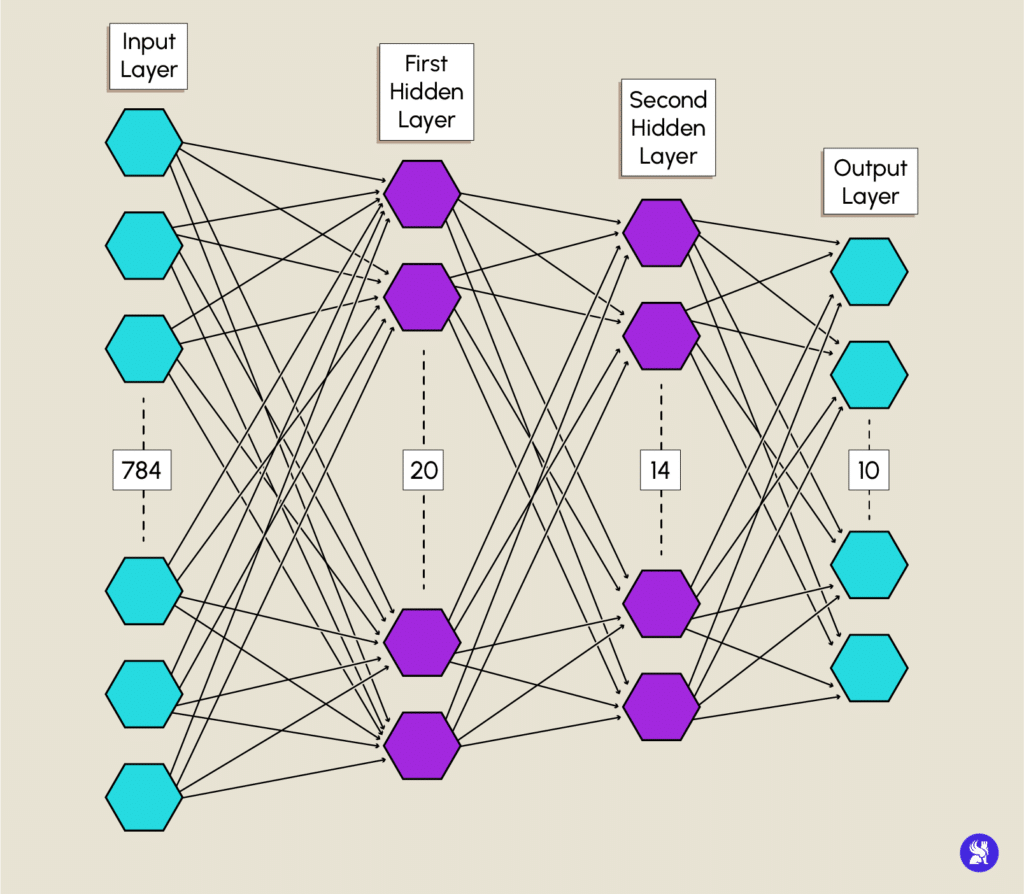
Le modèle est constitué d’une couche d’entrée (Input layer) avec un nombre de neurones équivalent au nombre de caractéristiques qu’une donnée peut avoir, dans notre cas c’est le nombre de pixels d’une image. Vous définissez votre couche d’entrée en utilisant le constructeur Input de keras.layers en spécifiant la dimension de nos données.
Les couches cachées (Hidden Layers) sont définies avec le constructeur Dense, l’argument units sert à spécifier le nombre de neurones d’une couche. Pour votre modèle, vous initialiserez la première avec 20 neurones et 14 pour la deuxième. Les deux couches cachées utiliseront la fonction d’activation relu.
La couche de sortie (Output Layer) quant à elle aura un nombre de neurones égale au nombre de classes distinctes, ici le nombre de chiffres, donc 10. Vous utiliserez aussi le constructeur Dense avec la fonction softmax qui nous donne une distribution entre 0 et 1 qui sont les probabilités d’appartenance de notre donnée aux classes respectives.
Voilà votre modèle défini après l’exécution du code ci-dessus.
Compilation du modèle :
Nous savons que vous mourrez d’envie de passer à l’entraînement du modèle, mais une dernière petite étape s’impose, c’est la compilation de notre modèle.
La méthode compile configure le processus d’entraînement du modèle en spécifiant 3 paramètres importants.
- loss : paramètre qui indique au modèle sur quelle fonction de perte se baser pour calculer l’erreur et l’optimiser. Ici nous utiliserons la « categorical_crossentropy »
- optimizer : ce paramètre définit l’algorithme d’optimisation que nous allons utiliser pour faire la descente de gradient de la fonction perte. On choisit l’optimiseur « adam » qui donne en générale de bons résultats sur un grand ensemble de problème
- metrics : paramètre servant à choisir les métriques d’évaluation du modèle pendant le processus d’entraînement. La métrique spécifiée pour ce modèle est l’accuracy (précisions), la plus utilisée pour les problèmes de classification.
L’exécution de la cellule suivante compilera votre modèle et le rendra enfin prêt pour être entraîné.
Entrainement du modèle :
Nous voilà enfin arrivé à la phase d’entraînement où toute la magie du Deep Learning opère. Mais avant ça, quelques notions nécessaires doivent être expliquées.
Les algorithmes de deep learning sont connus pour être assez gourmands en données où la taille des jeux de données utilisés pour entraîner un réseau de neurones atteignent des centaines, voire des milliers de GO, donc pour permettre aux machines dotées d’une mémoire vive assez limitée d’entraîner des modèles, on divise notre dataset en parties de tailles considérablement inférieures appelées batchs afin de pouvoir les charger plus facilement sur la RAM de la machine.
Aussi, lorsque tous les batchs ont été parcourus, on dit qu’une epoch a été complétée. L’apprentissage d’un réseau de neurones nécessite plusieurs epochs
Vous verrez que cette partie n’est pas si compliquée, en effet il suffit d’une seule ligne de code pour lancer l’entraînement. Cependant, on vous a promis de vous expliquer chaque détail du code, donc ici vous exécuterez la méthode fit sur votre modèle avec votre ensemble de données d’entraînement (train dataset) comme arguments ainsi que des paramètres supplémentaires :
- batch_size : le nombre d’échantillons de données que contiendra un batch
- epoch : le nombre d’epochs nécessaire à l’entraînement du modèle
- validation_split : le pourcentage des données qui serviront pour l’évaluation de notre modèle pendant son entraînement.
Le temps d’entraînement d’un modèle peut varier selon de multiples critères : La taille du jeu de données, la complexité de l’architecture du modèle, le nombre d’epochs ainsi que la puissance de calcul.
Evaluation du modèle :
Félicitations ! Vous venez d’entraîner votre premier modèle de Deep Learning. Maintenant vous devez vous assurer de la performance de celui-ci en mesurant son accuracy (précision).
Comme mentionné plus haut, l’accuracy est une métrique d’évaluation de classificateurs tel que c’est le ratio des points correctement classifié sur le nombre total des données.
Exécuter ce code vous affichera la précision d’entraînement et de validation en fonction des epochs. Un exemple de résultats obtenus suivra juste après
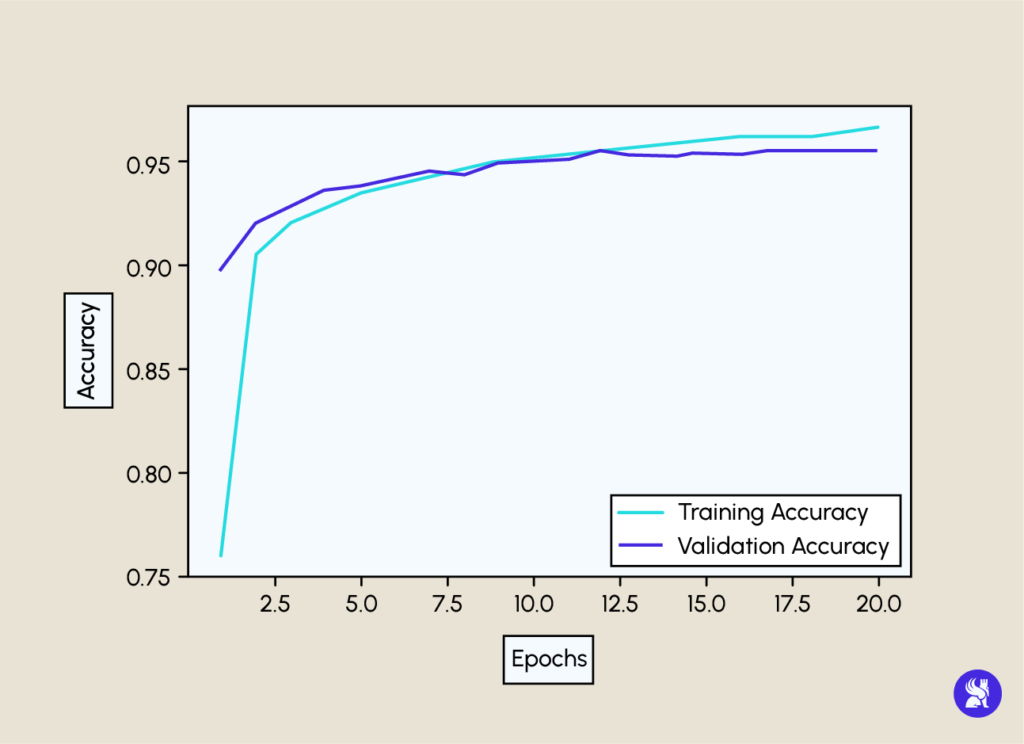
La training accuracy est obtenue en faisant les tests avec les données d’apprentissage, c.-à-d. des données que le modèle a déjà vu avant. Alors que la validation accuracy est obtenue avec de nouvelles données, ce qui explique cette différence au niveau du graphe.
Ici on a une validation accuracy de 95%, ce qui est très satisfaisant comme résultat
NB : Vous n’aurez pas forcément les mêmes résultats que ceux affichés car ils dépendent de l’initialisation des poids du modèle qui est aléatoire, mais la différence ne sera pas flagrante.
Devenez Pro du Deep Learning !
Maintenant que vous savez construire, entraîner et tester votre propre réseau de neurones, vous pourrez vous plonger dans le monde du Deep Learning et tenter plein de nouvelles choses. Pour ce modèle, vous pouvez essayer de modifier l’architecture, les fonctions d’activation ou les paramètres d’entraînement. Pour cela, vous pouvez jeter un coup d’œil sur la documentation de Keras.
Lancez vous sur de nouveaux projets qui traitent des données de sources nouvelles et différentes. Ne vous limitez pas qu’à un seul type de données, attaquez les données structurées et le NLP par exemple.
N’hésitez pas aussi à rester à jour sur notre blog qui regorge de connaissances sur le Deep Learning, comme cet article qui approfondira vos connaissances théoriques sur le sujet.
Et si vous souhaitez monter en compétence en Deep Learning, découvrez les parcours experts pensés par DataScientest.








