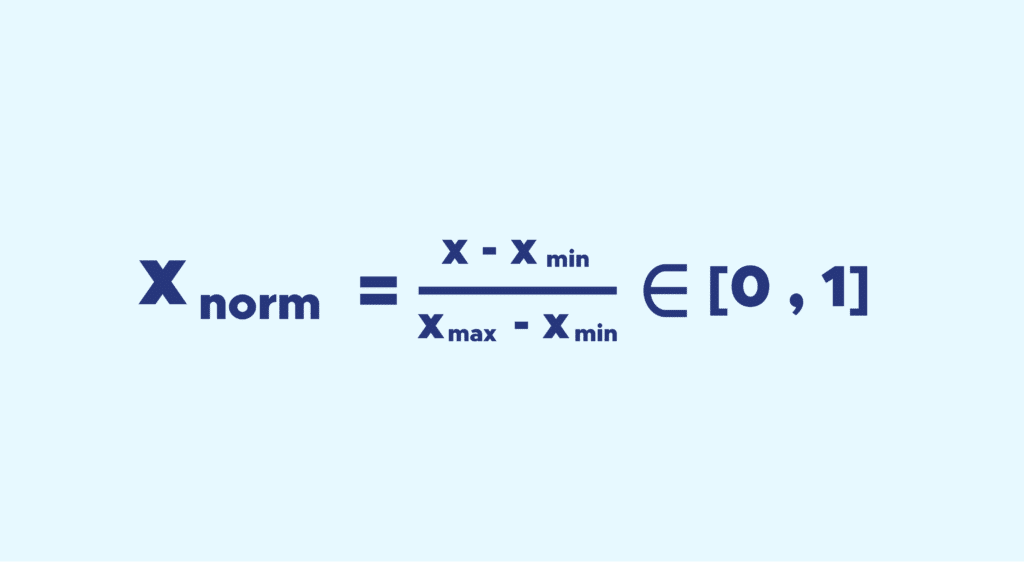
Daniel, c’est le support technique des formations DataScientest. C’est l’expert calé sur tous les sujets data science et qui accompagne les apprenants tout au long de leurs formations. Aujourd’hui, on a réussi à capter quelques minutes de son temps précieux pour qu’il puisse répondre à nos questions autour de la normalisation des données.

Moi - Hello Daniel je sais qu’on a souvent dû te poser la question mais je vois en permanence parler de la normalisation des données, est-ce que tu peux m’aider à comprendre le concept en quelques mots ?
Daniel – Alors en effet, la normalisation, comme on l’entend dans le domaine, est un concept central en prétraitement des données lorsque l’on est amené à travailler sur un projet de Machine Learning.
Deux principaux procédés sont en réalité sous-entendus lorsqu’on parle de normalisation : la normalisation et la normalisation standard, ou plus communément connu sous le nom de standardisation. Dans l’ensemble, ces deux procédés ont la même vocation : redimensionner les variables numériques pour qu’elles soient comparables sur une échelle commune.
Et mathématiquement, ça donne quoi ?
Considérons une variable numérique à n observations pouvant s’écrire :
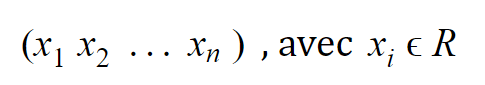
Comme nous avons un nombre fini de valeurs réelles, nous pouvons extraire plusieurs informations statistiques dont : le min, le max, la moyenne et l’écart type.
Le procédé de normalisation n’a besoin que du min et du max.
L’idée est la suivante, on ramène toutes les valeurs de la variable entre 0 et 1, tout en conservant les distances entre les valeurs.
Pour ce faire rien de plus simple, la formule est la suivante :
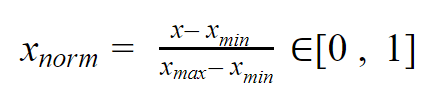
Pour ce qui est de la standardisation, la transformation est plus subtile que simplement ramener l’ensemble des valeurs entre 0 et 1, elle a pour but de ramener la moyenne μ à 0 et l’écart-type σ à 1.
Encore une fois, le procédé n’est pas sorcier si on a à disposition la moyenne μ et l’écart-type σ d’une variable X = x1 x2 xn donnée, alors la variable standardisée s’écrira :

C’est super tout ça, mais dans la data, à quoi ça sert ?
Dans la data, on est très souvent amenés à travailler avec des données numériques, et ces données sont rarement comparables dans leur état brut.
Travailler avec des données d’échelles variables peut constituer un problème dans l’analyse en ce sens qu’une variable numérique dont la plage de valeurs est comprise entre 0 et 10000 sera plus pesante dans l’analyse qu’une variable dont les valeurs sont comprises entre 0 et 1 ce qui causerait un problème de biais par la suite.
Attention cependant à ne pas considérer la normalisation comme une étape obligatoire dans le traitement de nos données, elle constitue une perte d’information dans l’immédiat et peut desservir dans certains cas !
Je comprends mieux, mais une question reste en suspens, comment on normalise des données concrètement ?
Sur Python c’est très simple, de nombreuses librairies le permettent. Je ne mentionnerai que Scikit-learn, car c’est la plus utilisée en Data Science. Cette bibliothèque propose des fonctions qui effectuent les normalisations voulues en quelques lignes de code très simples.
Il est important néanmoins de remettre les cas d’usage en contexte, car en pratique il ne suffit pas d’appliquer une normalisation bête et méchante à toutes les données qui nous passent sous la main alors que l’on a déjà normalisé nos données d’entraînement.
Pourquoi ? Pour la simple raison qu‘il n’est pas possible d’appliquer cette même transformation à un échantillon de test, ou à des données nouvelles.
Il est possible évidemment de centrer et réduire n’importe quel échantillon de la même manière, mais avec une moyenne et un écart type qui seront différents de ceux utilisés sur l’ensemble d’entraînement
Les résultats obtenus ne seraient pas une juste représentation de la performance du modèle dans son ensemble, lorsqu’il sera appliqué à de nouvelles données.
Donc, plutôt que d’appliquer directement la fonction de normalisation, il est préférable d’utiliser une fonctionnalité de Scikit-Learn appelée Transformer API, qui vous permettra d’ajuster (fit) une étape de preprocessing en utilisant les données d’entraînement.
Ainsi lorsque la normalisation, par exemple, sera appliquée à d’autres échantillons, elle utilisera les mêmes moyennes et écart-types sauvegardés.
Pour créer cette étape de preprocessing ‘ajustée’ il suffit d’utiliser la fonction StandardScaler puis de l’ajuster grâce à aux données d’entraînement. Enfin pour l’appliquer à un tableau de données par la suite il faudra simplement lui appliquer scaler.transform().
De même pour une normalisation MinMax :
Super, merci Daniel !
Si on veut se former en Data Science en étant guidé par tes conseils, comment on fait ?
Rien de plus simple, il vous suffit de démarrer prochainement l’une de nos formations en Data Science 🙂 Si vous souhaitez découvrir l’apport de Daniel au cours d’une formation, retrouvez l’interview de deux de nos alumnis :









