Les réseaux de neurones récurrents ou Recurrent Neural Network (RNN) sont des modèles d’apprentissage automatique puissants qui permettent d’analyser des séquences de données, telles que du texte, de la parole ou des séries temporelles. Ces réseaux permettent aux machines de « se souvenir » des informations passées et de les utiliser pour prendre des décisions en temps réel. Dans cet article nous allons découvrir comment fonctionnement les RNN.
Si vous êtes un adepte de notre blog, vous savez déjà ce qu’est un réseau de neurones (si ce n’est pas le cas, n’hésitez pas à lire cet article avant) mais qu’apporte l’adjectif récurrent à ce modèle ? Nous allons voir dans cet article comment les réseaux de neurones récurrents, appelés RNN, sont devenus un modèle classique en deep learning.
Mise en situation des Recurrent Neural Network
Avant d’expliciter un RNN, concentrons-nous sur une balle. En effet, il est fréquent en Machine Learning de vouloir prédire la trajectoire d’un objet amovible. Comme nous le montre la figure 1, du point de départ, la balle peut prendre toutes sortes de directions. Comment savoir quel est le prochain mouvement de la balle ?
Toutefois, si nous prenons la figure 2, il est évident de dire que la balle va continuer à aller vers la droite, grâce aux trajectoires passées, qui traduisent un mouvement vers la droite.
Jusque là tout semble logique.
Contrairement à la figure 1, nous avons plus des données d’entraînement en plus, d’où nous sommes plus aptes à décider du déplacement de la balle.
Ainsi, il suffit de donner à notre réseau de neurones les anciens déplacements de la balle et notre étude est terminée. Toutefois, comment choisir le nombre de neurones d’entrées ? Une trajectoire peut être partagée de la manière que nous voulons. Que cela soit 10 ou 100

La balle blanche représente la position actuelle de la balle et les balles en bleu claires représentent les anciennes trajectoires de la balle blanche, ainsi nous devinons que la balle se dirige vers la droite.
Occultons ce détail pour l’instant, et fixons la taille de nos échantillons d’entrée. Observons la figure 3, où la balle va-t-elle se diriger ?

Certes, le mouvement de la balle est plus complexe que dans la figure 1, mais nous arrivons toujours à dire que le prochain déplacement de la balle se fera vers le haut. Le modèle fera-t-il la même prédiction ? Malheureusement non, car le réseau de neurones ne pense pas comme nous ! Le modèle, contrairement à nous, ne prend pas en compte le lien entre les entrées. Les entrées ne sont pas indépendantes les unes des autres, donc nous devons préserver ce lien entre elles lorsque nous entraînons notre réseau de neurones.
Nous devons pallier 2 problèmes :
- La taille de nos échantillons d’entrée qui n’est pas fixe.
- Les données d’entrées ne sont pas liées entre elles.
Transition vers le RNN
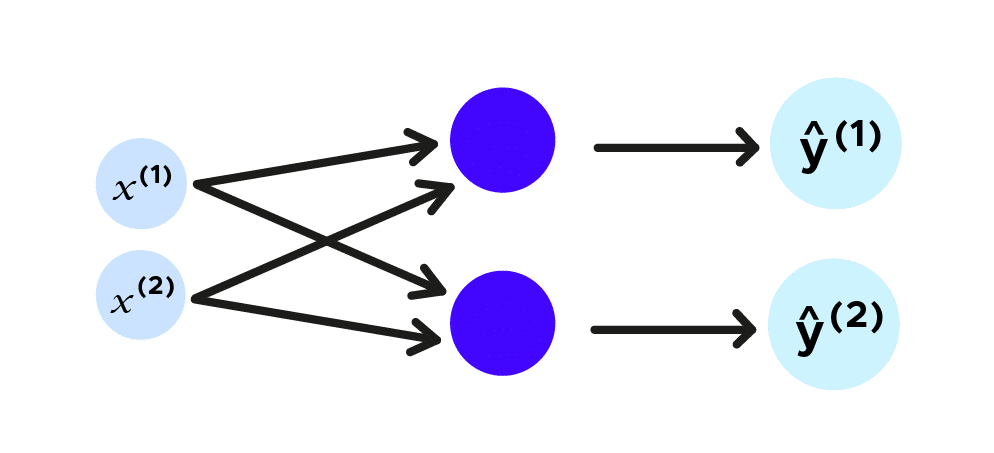
Revenons sur notre étude de trajectoire de balle. Nous allons considérer un plan, donc la trajectoire de la balle aura deux coordonnées, que nous nommons x^1,x^2 et nous voulons prédire la prochaine localisation de la balle, la prédiction des futures coordonnées seront ŷ^1,ŷ^2. Représentons cela avec un réseau de neurones traditionnel.
De manière synthétique, si nous posons (x^1,x^2)=x_t et (ŷ^1,ŷ^2)=ŷ_t, nous pouvons faire le schéma ci-dessous :
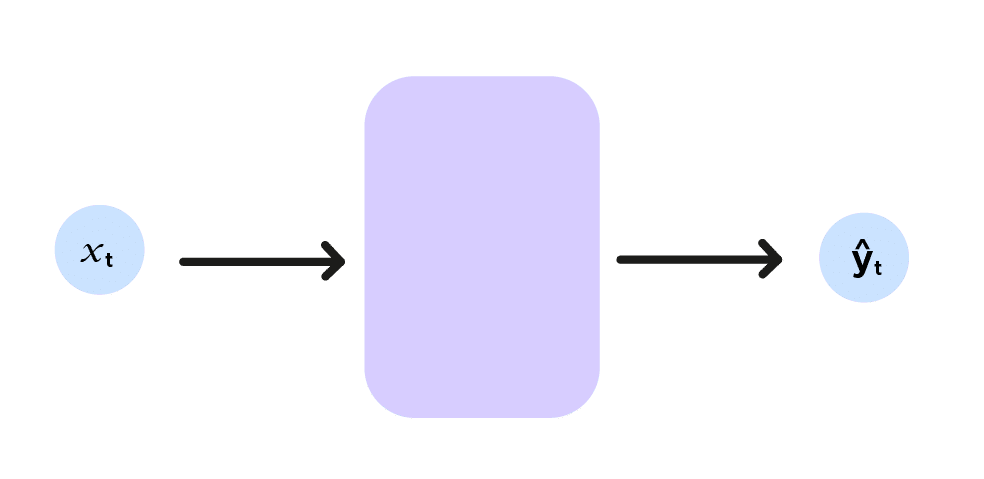
Ici l’indice t indique les coordonnées de la balle à l’instant t, représentant le réseau de neurones par une fonction f, nous avons :
f(x_t)=ŷ_t (reprendre le style mathématique de la formule RNN(ci-dessous en anglais))
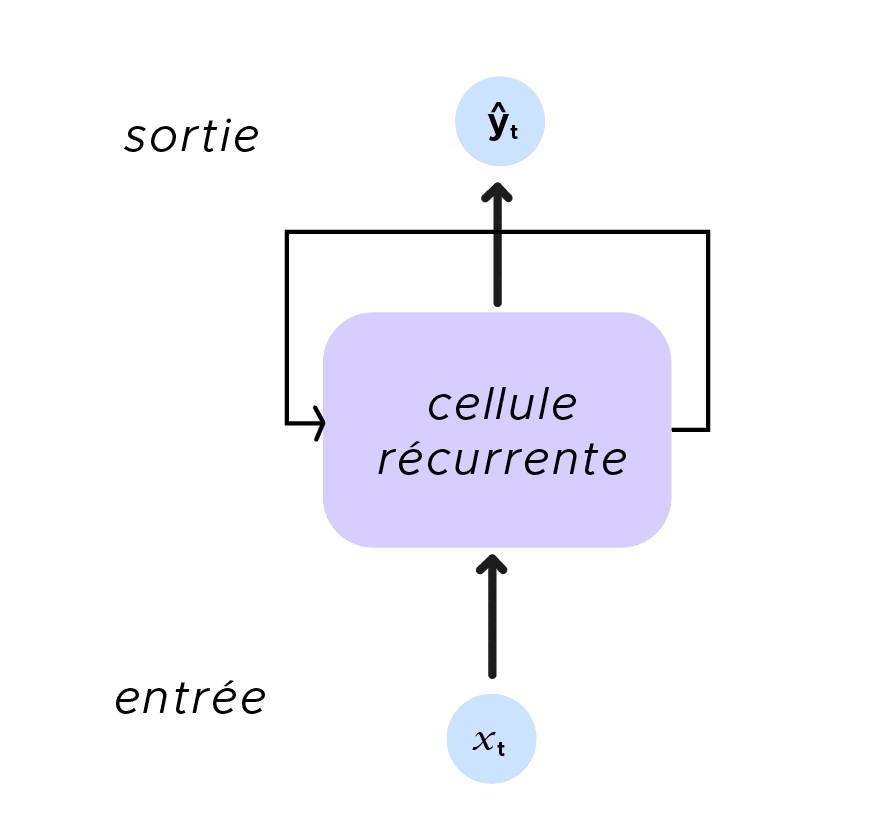
Comme nous l’avions indiqué précédemment, nous étudions de manière locale le mouvement de la balle. Nous voulons prendre en compte plusieurs instants du mouvement de la balle. Si nous ne pouvons y parvenir avec un réseau de neurones traditionnel, avec les RNN, tout cela change, car le concept de récurrence est introduit. En effet, observons la figure ci-dessous. Nous rajoutons une entrée h_t, appelée état caché(hidden state). Cet état caché incarne ŷ_t et est donnée en argument de la prochaine prédiction en plus de l’entrée x_t. Nous avons bien considéré un ensemble et nous mettons donc en lien les sorties et les entrées sans limite pour nos échantillons d’entrée.
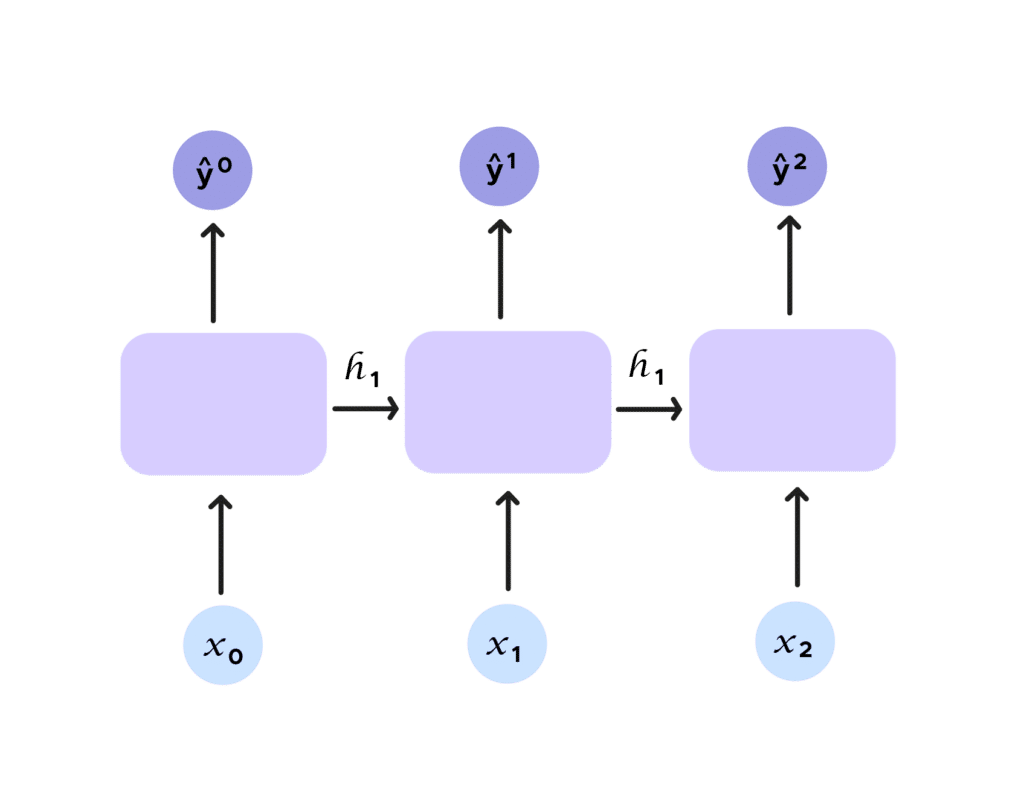
Si nous essayons de symboliser cela par une formule, nous obtenons l’équation suivante :
Nous apercevons bien le concept de récurrence. Pour prédire le prochain terme, nous avons besoin d’informations antérieures fournies par h_{t-1}.
La récurrence est encore plus flagrante dans ce schéma récapitulatif.
Quelques applications des RNN
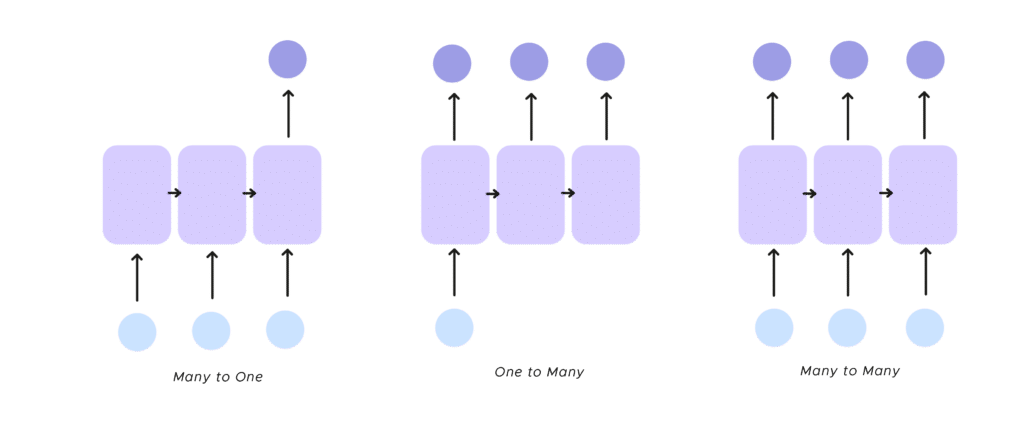
- one to many Le RNN reçoit une unique entrée et retourne plusieurs sorties, l’exemple classique de ce procédé est la légende d’image
- many to one On a plusieurs entrées et il y a une unique sortie. Une illustration de ce mode est l’analyse de sentiment sur des textes. Cela permet d’identifier un sentiment à partir d’un groupe de mots, déterminer le mot qui manque pour finir la phrase reçue en entrée. Pour en apprendre plus sur l’analyse de sentiments, rendez-vous dans cet article .
- many to many Enfin, on peut prendre plusieurs entrées et obtenir plusieurs sorties. Nous n’avons pas forcément le même nombre de neurones d’entrée et de sortie. Nous pouvons citer ici, la traduction de texte mais nous pouvons être ambitieux et projeter de finir une œuvre musicale avec son début.
Parfait, nous avons vu le fonctionnement d’un RNN et ses multiples applications, mais est-il parfait ? Malheureusement, il présente un inconvénient majeur, appelé mémoire à court terme, dont nous allons voir un exemple en TALN(Traitement automatique du langage naturel).
Le RNN est-il un poisson rouge ?
Prenons le cas de la complétion de phrase : J’aime les sushis, je vais partir en manger au …
Le RNN n’arrive pas à retenir le mot sushi pour prédire Japon, car il n’a pas retenu le mot sushi. Pour arriver à déterminer le Japon, il faut que le RNN possède une mémoire plus forte. Nous pouvons faire cela, en complexifiant les neurones. En particulier, nous allons voir le cas du LSTM(Long Short Term Memory). En plus de l’état caché conventionnel h_t, nous allons ajouter un deuxième état appelé c_t. Ici, h_t représente la mémoire courte du neurone et c_t la mémoire longue.
Nous n’allons pas rentrer dans les considérations techniques de cet effrayant schéma. L’essentiel est de remarquer que nous avons une cellule beaucoup plus complexe, qui nous permet de régler le problème de mémoire. Avec le LSTM, nous faisons passer les h_t et c_t dans des portes, au nombre de 4.
- La première porte permet d’éliminer les informations inutiles, c’est la forget gate.
- La deuxième porte, stocke la nouvelle information, la store gate.
- La troisième porte met à jour l’information que nous allons donner au RNN avec le résultat de la forget gate et de la store gate, c’est la update gate.
- Enfin la dernière porte(output gate), nous donne y_t et h_t.
Ce long processus permet de contrôler les informations que nous gardons et transmettons à travers le temps.
Le RNN arrive à savoir ce qu’il faut garder et ce qu’il faut oublier, grâce à son apprentissage. Le LSTM(Long Short Term Memory) n’est pas unique, nous pouvons utiliser aussi GRU(Gated Recurrent Unit), juste l’architecture de la cellule change.
Résumons maintenant ce que nous avons vu. Les RNN est un type particulier de réseaux de neurones qui permet de traiter des données qui ne sont pas indépendantes et qui n’ont pas de taille fixe. Néanmoins, les RNN standards sont assez limités avec le problème de mémoire courte, que nous pouvons régler en utilisant des cellules plus complexes comme les LSTM ou GRU.
Par ailleurs, nous pouvons faire un parallèle avec un autre système de réseau de neurones : les réseaux de neurones convolutifs(CNN en anglais). En effet, les CNN sont connus pour partager les informations spatiales alors que les RNN eux partagent les informations temporelles, vous pouvez vous renseigner sur les CNN avec cet article. Enfin, si vous voulez mettre en pratique les RNN, n’hésitez pas à rejoindre notre formation Data Scientist.









