L’analyse de sentiments est une technique qui s’est fortement développée en même temps que les réseaux sociaux, où les utilisateurs ont la possibilité de s’exprimer massivement et de partager en permanence leurs sentiments. L’analyse de sentiment (ou sentiment analysis en anglais) vise donc à déterminer la tonalité émotionnelle d’un discours en le classifiant dans différentes catégories comme positif, négatif ou neutre par exemple.
Elle est prisée par des acteurs variés que ce soit le politicien en pleine campagne électorale ou encore des entreprises prêtes à lancer un nouveau produit, pour ne citer qu’eux.
Le politicien voudra tester sa cote de popularité auprès des électeurs tandis que l’entreprise cherchera à évaluer l’accueil de son produit auprès du public.
fig. : exemple de phrase à analyser
Mais en quoi consiste réellement le Sentiment Analysis et comment les Data Scientist utilisent-ils les techniques de Machine Learning pour décrypter la tonalité émotionnelle d’un discours ?
Comment ca marche ?
L’analyse de sentiment (ou sentiment analysis) intervient quand on communique que ce soit à écrit ou à l’oral. Les Data Scientist ont la possibilité d’exploiter des données audios ou bien textuelles. C’est d’ailleurs le format des données qui oriente la technique de Machine Learning à utiliser.
Comment analyser une phrase dite oralement ?
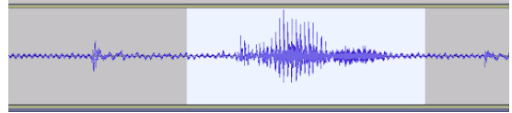
Dans ce cas, la donnée à analyser est un signal électrique généré par le cerveau appelé électroencéphalogrammes ( ou EEG). Globalement ça ressemble à ça :
fig. : exemple de signal électrique produit par le cerveau [1]
Pour collecter cette donnée, que l’on va analyser par la suite, des électrodes sont disposées sur le crâne. Si l’on mène l’expérience sur vous, vous ressemblerez à peu près à ça :
Une fois les signaux collectés, il faut en extraire des caractéristiques (aussi appelées features en anglais) qui représentent l’information contenue dans le signal. Ces caractéristiques sont un format plus lisible par l’algorithme de Machine Learning qui va classifier les signaux. L’extraction de features se fait en appliquant différentes transformations comme des filtres au signal électrique.
Une fois les features extraites, nous allons les donner en entrée à notre algorithme comme par exemple un Réseau de Neurones (ou Neural Network) afin qu’il puisse classifier les signaux dans les différentes catégories : positif/négatif/neutre.
En réalité, cette technique de récupérer un signal cérébral pour ensuite l’analyser et en déduire une polarité (positive/négative/neutre) est peu utilisée dans la vie courante et surtout exploitée dans le domaine de la recherche notamment par les chercheurs qui s’intéressent aux problématiques mêlant Intelligence Artificielle et neurosciences.
Comment est classifié un commentaire écrit sur Facebook ?
Ces méthodes analysent directement les mots et doivent tenir compte des aspects contextuels et linguistiques de la donnée.
En bref, la phrase à analyser va être traitée comme une séquence qui définit un contexte et dont les mots sont dépendants les uns des autres c’est-à-dire qu’ils vont être analysés au regard des mots qui les précèdent dans la phrase.
Pour traiter ces phrases, les Data Scientists vont alors utiliser des Réseau de neurones récurrents (ou RNN, Recurrent neural network en anglais) qui sont des réseaux de neurones spécialisés dans le traitement de séquences.
Une architecture (très simplifiée) de RNN pour l’analyse de sentiment ressemblerait donc à ce pipeline :
fig. : architecture d’un RNN pour l’analyse de sentiments
Si on prend la phrase “Tu es poli” alors on voit bien que le mot “poli” une fois analysé par l’algorithme va permettre de renvoyer une des deux classes (ici, positive en l’occurrence) et que ce mot “poli” a été analysé après le mot “es” (autrement dit, dans le contexte du mot “es”) lui-même analysé après le mot “tu” (autrement dit, dans le contexte du mot “tu”).
Cette récurrence permet donc de définir un contexte, indispensable dans l’analyse de sentiment.
Bien évidemment, il existe des phrases subtiles et complexes à analyser pour des machines. “Ce parfum sent extrêmement bon, il en est addictif”. Le mot “extrêmement” peut être connoté soit positivement soit négativement tandis qu’ “addictif” est en général associé à un sentiment négatif.
Même si la technologie des réseaux de neurones récurrents (RNN) existe depuis plusieurs années, ce n’est que récemment que les scientifiques ont réussi à obtenir des résultats très prometteurs, notamment grâce aux capacités de calcul qui sont en constante amélioration. Cette technologie est donc utilisée de plus en plus régulièrement par les entreprises souhaitant avoir un retour de leurs utilisateurs sur un produit ou tout autre personne ayant accès à une grande quantité de messages afin d’en dégager un sentiment général.
Cet article vous a plu ?
Vous vous demandez comment récupérer des données de site web pour analyser les sentiments des utilisateurs ?