
L’article va traiter de la programmation d’API (Application Programming Interfaces) Web sous Python. Celles-ci sont des outils permettant de rendre accessibles de l’information et des fonctionnalités via internet. Vous pouvez également découvrir comment connecter une API à une base de données sous python et comment programmer et documenter une API avec python, flask, swagger et connexion. Dans cet article, on verra :
1. Qu'est-ce qu'une API ?
Une API Web permet à de l’information et à des fonctionnalités d’être manipulées par des programmes informatiques via internet.
Par exemple, avec l’API Web Twitter, on peut écrire un programme dans un langage comme Python ou Javascript qui collecte des métadonnées sur les tweets.
Plus généralement, en programmation, le terme API (abréviation d’Application Programming Interface) réfère à une partie d’un programme informatique conçue pour être utilisée ou manipulée par un autre programme, contrairement aux interfaces qui sont conçues pour être utilisées ou manipulées par des humains.
Les programmes informatiques ont souvent besoin de communiquer entre eux ou avec le système d’exploitation sous-jacent et les API sont une façon de le faire.
Dans la suite, toutefois, on se limitera aux API Web.
2. Quand utiliser une API ?
Si on dispose de données qu’on souhaite partager avec le monde entier, créer une API Web est une façon de le faire.
Toutefois, les API ne sont pas toujours la meilleure manière de partager des données avec des utilisateurs.
Si le volume des données qu’on souhaite partager est relativement faible, il vaut mieux proposer un « data dump » sous la forme d’un fichier JSON, XML, CSV ou Sqlite. Selon les ressources dont on dispose, cette approche peut être viable jusqu’à un volume de quelques Gigaoctets.
En général, on utilise une API Web quand :
- Notre jeu de données est important, ce qui rend le téléchargement par FTP lourd ou consommateur de ressources importantes.
- Les utilisateurs ont besoin d’accéder aux données en temps réel, par exemple pour une visualisation sur un site web ou comme une partie d’une application.
- Nos données sont modifiées ou mises à jour fréquemment.
- Les utilisateurs n’ont besoin d’accéder qu’à une partie des données à la fois.
- Les utilisateurs ont à effectuer d’autres actions que simplement consulter les données, par exemple contribuer, mettre à jour ou supprimer.
Notons qu’on peut fournir à la fois un data dump et une API ; à charge des utilisateurs de choisir ce qui leur convient le mieux.
3. La terminologie associée aux API
HTTP (HyperText Transfert Protocol) : c’est le principal moyen de communiquer de l’information sur Internet. HTTP implémente un certain nombre de « méthodes » qui disent dans quelle direction les données doivent se déplacer et ce qui doit en être fait. Les deux plus fréquentes sont GET, qui récupère les données à partir d’un serveur, et POST, qui envoie de nouvelles données vers un serveur.
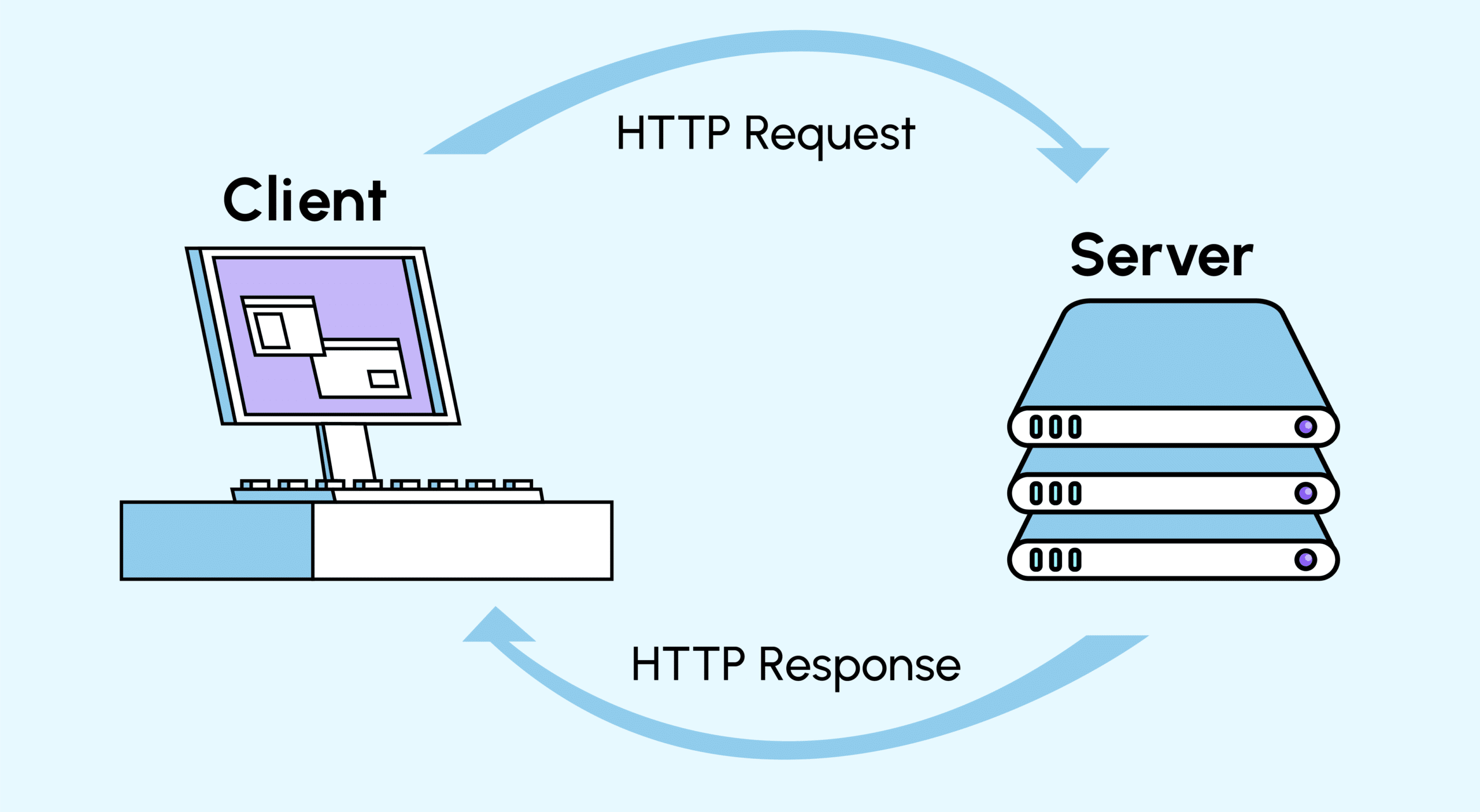
URL (Uniform Ressource Locator) : Adresse d’une ressource sur le web, comme http://www-facultesciences.univ-ubs.fr/fr. Une URL consiste en un protocole (http://), un domaine (www-facultesciences.univ-ubs.fr), un chemin optionnel (/fr).
Elle décrit l’emplacement d’une ressource spécifique, comme une page Web. Dans le domaine des API, les termes URL, request, URI, endpoint désignent des idées similaires. Dans la suite, on utilisera uniquement les termes URL et request (requête), pour être plus clair.
Pour effectuer une requête GET ou suivre un lien, il suffit de disposer d’un navigateur Web.
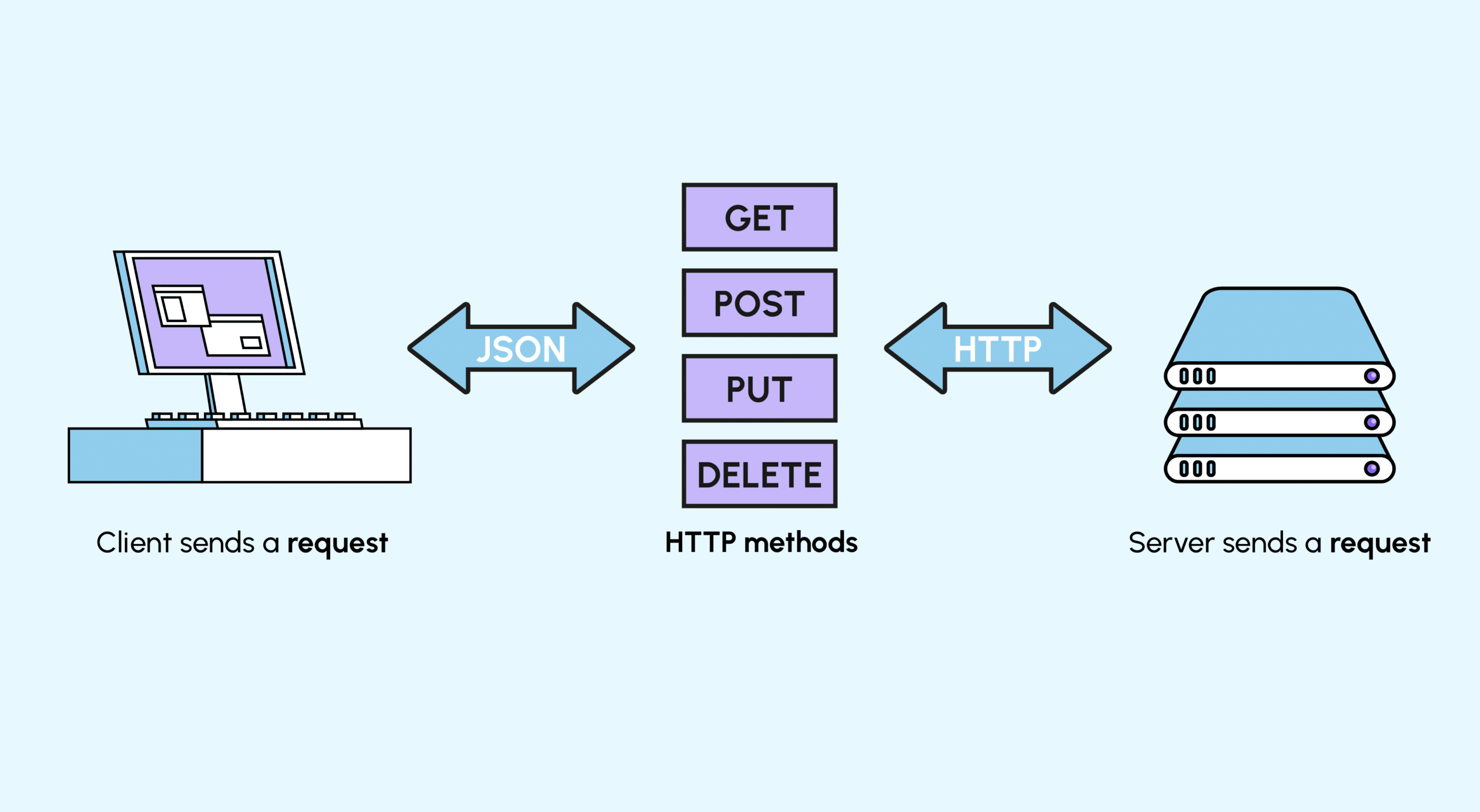
JSON (JavaScript Object Notation) : c’est un format texte de stockage des données conçu pour être lisible à la fois par les êtres humains et les machines. JSON est le format le plus usuel des données récupérées par API, le deuxième plus usuel étant XML.
REST (REpresentational State Transfer) : c’est une méthodologie qui regroupe les meilleures pratiques en termes de conception et d’implémentation d’APIs. Les API conçues selon les principes de la méthodologie REST sont appelées des API REST (REST APIs). Il y a toutefois de nombreuses polémiques autour de la signification exacte du terme. Dans la suite, on parlera plus simplement d’API Web ou d’API HTTP.
4. Un premier exemple
Dans la suite, on va voir comment créer une API en utilisant Python et le cadre de travail Flask.
Notre exemple d’API portera sur un annuaire des employés d’une entreprise qui fournira leur nom, prénom, fonction et ancienneté.
On commencera par utiliser Flask pour créer une page web pour notre site. Cela nous permettra de voir comment Flask fonctionne. Une fois qu’on aura une petite application Flask fonctionnelle sous la forme d’une page Web, on transformera le site en une API.
Pourquoi Flask ? En effet, Python dispose de plusieurs cadres de développement (frameworks) permettant de produire des pages Web et des API.
Le plus connu est Django, qui est très riche mais qui peut toutefois être écrasant pour les utilisateurs non expérimentés.
Les applications Flask sont construites à partir de canevas très simples et sont donc plus adaptées au prototypage d’APIs.
On commence par créer un nouveau répertoire sur l’ordinateur, qui servira de répertoire de projet et qu’on nommera projects.
Les fichiers de notre projet seront stockés dans un sous-répertoire de projects, nommé api.
On lance ensuite Spyder 3 ou tout autre EDI et on saisit le code suivant :
On sauvegarde ensuite le programme sous le nom api.py dans le répertoire api précédemment créé.
Afin de l’exécuter, on lance une fenêtre ligne de commande à partir de ce répertoire et on saisit les commandes suivantes :
$ export FLASK_APP = api.py
$ export FLASK_ENV = development
$ flask run
Alternativement, on peut exécuter le programme sous Spyder ou tout autre EDI utilisé.
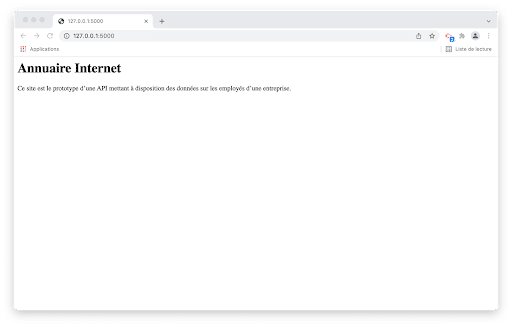
On obtient dans le console l’affichage suivant (entre autres sorties) :
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
Il suffit de saisir le lien précédent dans un navigateur Web pour accéder à l’application.
On a ainsi créé une application Web fonctionnelle.
Examinons à présent la façon dont Flask fonctionne.
Flask envoie des requêtes HTTP à des fonctions Python. Dans notre cas, nous avons appliqué un chemin d’URL (‘/‘) sur une fonction : home.
Flask exécute le code de la fonction et affiche le résultat dans le navigateur. Dans notre exemple, le résultat est un code HTML de bienvenue sur le site hébergeant notre API.
Le processus consistant à appliquer des URL sur des fonctions est appelé routage (routing).
L’instruction :
@app.route(‘/’, methods=[‘GET’])
apparaissant dans le programme indique à Flask que la fonction home correspond au chemin /.
La liste methods (methods=[‘GET’]) est un argument mot-clef qui indique à Flask le type de requêtes HTTP autorisées.
On utilisera uniquement des requêtes GET dans la suite, mais de nombreuses applications Web utilisent à la fois des requêtes GET (pour envoyer des données de l’application aux utilisateurs) et POST (pour recevoir les données des utilisateurs).
Commentons à présent le programme plus en détail.
import Flask : Cette instruction permet d’importer la bibliothèque Flask, qui est disponible par défaut sous Anaconda.
app = flask.Flask(__name__) : Crée l’objet application Flask, qui contient les données de l’application et les méthodes correspondant aux actions susceptibles d’être effectuées sur l’objet. La dernière instruction app.run( ) est un exemple d’utilisation de méthode.
app.config[“DEBUG” = True] : lance le débogueur, ce qui permet d’afficher un message autre que « Bad Gateway » s’il y a une erreur dans l’application.
app.run( ) : permet d’exécuter l’application.
À présent, afin de créer l’API, on va spécifier nos données sous la forme d’une liste de dictionnaires Python.
À titre d’exemple, on va fournir des données sur trois employés de notre entreprise. Chaque dictionnaire contiendra un numéro d’identification, le nom, le prénom, la fonction et l’ancienneté d’un employé.
On introduira également une nouvelle fonction : une route permettant aux visiteurs d’accéder à nos données.
Ainsi, nous remplaçons le code sauvegardé dans api.py par le code suivant :

Pour accéder à l’ensemble des données, il suffit de saisir dans le navigateur l’adresse :
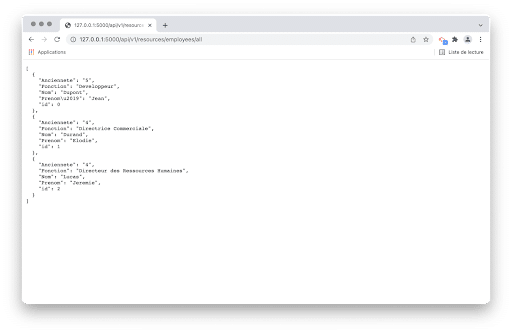
On a utilisé la fonction jsonify de Flask. Celle-ci permet de convertir les listes et les dictionnaires au format JSON.
Via la route qu’on a créé, nos données sur les employés sont converties d’une liste de dictionnaires vers le format JSON, avant d’être fournies à l’utilisateur.
À ce stade, nous avons créé une API fonctionnelle, bien que limitée.
En effet, en l’état actuel de notre API, les utilisateurs ne peuvent accéder qu’à l’intégralité de nos données; il ne peuvent spécifier de filtre pour trouver des ressources spécifiques.
Bien que cela ne pose pas problème sur nos données de test, peu nombreuses, cela devient problématique au fur et à mesure qu’on ajoute des données.
Dans la suite, on va introduire une fonction permettant aux utilisateurs de filtrer les résultats renvoyés à l’aide de requêtes plus spécifiques.
Le nouveau code est le suivant :
Après avoir saisi, sauvegardé et exécuté le code sous Spyder 3, on peut saisir les adresses suivantes dans le navigateur :
127.0.0.1:5000/api/v1/resources/employees?id=0
127.0.0.1:5000/api/v1/resources/employees?id=1
127.0.0.1:5000/api/v1/resources/employees?id=2
127.0.0.1:5000/api/v1/resources/employees?id=3
Chacune de ces adresses renvoie un résultat différent, excepté la dernière, qui renvoie une liste vide, puisqu’il n’y a pas d’employé d’identifiant 3.
Dans la suite, on va examiner notre nouvelle API en détail.
Nous avons créé une nouvelle fonction api_root, avec l’instruction @app_route, appliquée sur le chemin /api/v1/resources/employees.
Ainsi, la fonction est exécutée dès lors qu’on accède à http://127.0.0.1:5000/api/v1/resources/employees.
Notons qu’accéder au lien sans spécifier d’ID, renvoie le message d’erreur spécifié dans le code : Erreur: Pas d’identifiant fourni. Veuillez spécifier un id.
Dans notre fonction, on fait deux choses : on commence par examiner l’URL fournie à la recherche d’un identifiant, puis on sélectionne le livre qui correspond à l’identifiant.
L’ID doit être fourni avec la syntaxe ?id=0, par exemple.
Les données passées à l’URL de cette façon sont appelées paramètres de requête. Ils sont une des caractéristique du protocole HTTP.
La partie suivante du code détermine s’il y a un paramètre de requête du type ?id=0, puis affecte l’ID fourni à une variable.
Ensuite, on parcourt l’annuaire des employés, on identifie l’employé ayant l’ID spécifié et on le rajoute à la liste renvoyée en résultat.
Finalement, l’instruction return jsonify(results) renvoie les résultats au format JSON pour affichage dans le navigateur.
A ce stade, on a créé une API fonctionnelle. Dans les posts suivants, on va voir comment créer une API un peu plus complexe, qui utilise une base de données. Les principes et instructions fondamentaux resteront toutefois les mêmes.
5. Quelques principes de bonne conception des API Web
Deux aspects des bonnes API sont la facilité d’utilisation (usability) et la maintenabilité (maintainability). Nous garderons ces exigences présentes lorsque nous programmerons des API sous Python.
La méthodologie la plus répandue de conception des API (API design) s’appelle REST.
L’aspect le plus important de REST est qu’elle est basée sur quatre méthodes définies par le protocole HTTP : GET, POST, PUT et DELETE. Celles-ci correspondent aux quatre opérations standard effectuées sur une base de données : READ, CREATE, UPDATE et DELETE.
Dans la suite, on ne s’intéressera qu’aux requêtes GET, qui permettent de lire dans une base de données.
Les requêtes HTTP jouent un rôle essentiel dans le cadre de la méthodologie REST, de nombreux principes de conception gravitant autour de la façon dont les requêtes doivent être formatées.
On a déjà créé une requête HTTP, qui renvoyait l’intégralité de notre catalogue.
Commençons par une requête mal conçue :
http://api.example.com/getemployee/10
Cette requête pose un certain nombre de problèmes : le premier est sémantique ; dans une API REST, les verbes typiques sont GET, POST, PUT et DELETE, et sont déterminés par la méthode de requête plutôt que par l’URL de requête. Cela entraîne que le mot « get » ne doit pas apparaître dans la requête, puisque « get » est impliqué par le fait qu’on utilise une requête HTTP GET.
De plus, les collections de ressources, comme employees ou users, doivent être désignées par des noms au pluriel.
Cela permet d’identifier facilement si l’API se réfère à un ensemble d’employés (employees) ou à un employé particulier (employee).
Ces remarques présentes à l’esprit, la nouvelle forme de notre requête est la suivante :
http://api.example.com/employees/10
La requête ci-dessus utilise une partie du chemin pour fournir l’identifiant.
Bien que cette approche soit utilisée en pratique, elle est trop rigide : avec des URL construites de cette façon, on ne peut filtrer que par un champ à la fois.
Les paramètres de requêtes permettent de filtrer selon plusieurs champs de la base de données et de spécifier des données supplémentaires, comme un format de réponse :
http://api.example.com/employees?nom=Durand&prenom=Elodie&output=xml
Quand on met au point la structure des requêtes soumises à une API, il est également raisonnable de prévoir les développements futurs.
Bien que la version actuelle de l’API ne fournisse de l’information que sur un type de ressources (employees), il fait sens d’envisager qu’on puisse rajouter d’autres ressources ou des fonctionnalités à notre API, ce qui donne :
http://api.example.com/resources/employees?id=10
Spécifier un segment « resources » sur le chemin permet d’offrir aux utilisateurs l’option d’accéder à toutes les ressources disponibles, avec des requêtes du type :
https://api.example.com/v1/resources/images?id=10
https://api.example.com/v1/resources/all
Une autre façon d’envisager les développements futurs de l’API est de rajouter un numéro de version au chemin.
Cela permet de continuer à maintenir l’accès à l’ancienne API si on est amené à concevoir une nouvelle version, par exemple la v2, de l’API.
Cela permet aux applications et aux scripts conçus avec la première version de l’API de continuer à fonctionner après la mise à jour.
Finalement, une requête bien conçue, dans les cadres de la méthodologie REST, est de la forme suivante :
6. Exemples et documentation
Sans documentation, même la meilleure API est inutilisable.
Une documentation doit être associée à l’API, qui décrit les ressources ou fonctionnalités disponibles via l’API et fournit des exemples concrets d’URLs de requête et de code.
Il est nécessaire de prévoir un paragraphe pour chaque ressource, qui décrit les champs pouvant être requêtés, comme title et id.
Chaque paragraphe doit fournir un exemple de requête HTTP ou un bloc de code.
Une pratique usuelle de la documentation des API consiste à annoter le code, les annotations pouvant être automatiquement regroupées en une documentation à l’aide d’outils comme Doxygen ou Sphinx.
Ces outils génèrent une documentation à partir des « docstrings », c’est-à-dire des chaînes de caractères documentant les fonctions.
Bien que ce type de documentation soit précieux, on ne doit pas s’arrêter là. Il faut se mettre dans la peau d’un utilisateur et fournir des exemples concrets d’utilisation.
Idéalement, on doit disposer de trois types de documentation :
- une référence détaillant chaque route et son comportement ;
- un guide expliquant la référence en prose ;
- un ou deux tutoriels expliquant en détail chaque étape.
Pour un exemple de documentation d’API, on pourra consulter le New York Public Library Digital Collections API qui constitue un bon standard.
Un autre exemple, plus fourni, est celui de la MediaWiki Action API qui fournit de la documentation permettant aux utilisateurs de soumettre des requêtes partielles à l’API.
Pour d’autres exemples de documentation d’API, on pourra consulter l’API de la Banque Mondiale et l’API European Pro.
7. Références bibliographiques
- Creating Web APIs with Python and Flask, Patrick Smyth : https://programminghistorian.org/en/lessons/creating-apis-with-python-and-flask
- Flask RESTful documentation : https://flask-restful.readthedocs.io/en/latest/index.html
- Flask Web Development : Developing Web Applications with Python (2ème édition). M. Grinberg. O’Reilly 2018.
- Architectural Styles and the Design of Network-Based Software Architectures. Fielding. Thèse, Université de Californie, 2000.






