
On a vu dans les deux précédents articles un premier exemple de programmation d’une API Web sous Flask et comment connecter une API Web à une base de donnée SqLite.
Un des objectifs des APIs est de découpler les données des applications qui les utilisent, en rendant transparents les détails de l’implémentation des données.
1. La méthodologie REST
On a mentionné la méthodologie REST dans le premier article. On va à présent l’examiner plus en détail.
On peut voir REST comme un ensemble de conventions tirant parti du protocole HTTP pour fournir des outils CRUD (Create, Read, Update, Delete) agissant sur des entités ou des collections d’entités sur lnternet.
CRUD peut être mis en correspondance avec HTTP de la façon suivante :
On peut effectuer chacune de ces actions sur une entité ou une ressource.
On peut voir une ressource comme une entité à laquelle on peut associer un nom : une personne, une adresse, une transaction.
L’idée de ressource peut être mise en correspondance avec celle d’URL, comme on l’a vu dans le premier article.
Une URL doit identifier une ressource unique sur le Web, quelque chose qui correspond toujours à la même URL.
Avec les concepts de ressource et d’URL, on est à même de concevoir des applications agissant sur des choses identifiées de façon unique sur le Web.
C’est une première étape vers la conception d’APIs à proprement parler, permettant d’effectuer les actions souhaitées via le réseau.
2. Ce que REST n’est pas
La méthodologie REST étant très utile et aidant à mettre au point la façon dont on interagit avec une API, elle est parfois utilisée à tort, pour des problèmes auxquels elle n’est pas adaptée.
Dans de nombreux cas, on souhaite effectuer une action directement. Prenons l’exemple de la substitution d’une chaîne de caractères.
Voici un exemple d’URL permettant a priori de le faire :
/api/substituteString/<string>/<search_string>/<sub_string>
Ici, désigne la chaîne sur laquelle on veut faire la substitution, est la sous-chaîne à remplacer et est la nouvelle sous-chaîne.
On peut très certainement concevoir un code sur le serveur qui permette d’effectuer l’opération souhaitée, mais cela pose des problèmes en termes de REST.
- Premier problème : l’URL ne pointe pas vers une ressource unique ; ainsi ce qu’elle renvoie dépend entièrement du chemin spécifié.
- Deuxième problème : Aucun concept CRUD ne correspond à cette URL.
- Troisième problème : la signification des variables de chemin dépend de leur position dans l’URL.
On pourrait corriger cela en modifiant l’URL de façon à utiliser une requête :
/api/substituteString? string=<string>&search_string=<search_string>&sub_string=<sub_string>
Mais la portion d’URL /api/substituteString ne désigne pas une entité (n’est pas un nom) ou une
collection d’entités : elle désigne une action (c’est un verbe).
Cela ne rentre pas dans le cadre des conventions REST et de ce fait ne correspond pas à une API. Ce que l’URL précédente représente est en fait un RPC (Remote Procedure Call).
Conceptualiser ce qu’on veut faire comme un RPC est plus pertinent. Cela d’autant plus que les conventions REST et RPC peuvent coexister sans problème au sein d’une API.
3. Premiers pas
Dans l’exemple suivant, on va mettre au point une API REST permettant d’accéder à un annuaire de personnes et d’effectuer des opérations CRUD sur celui-ci.
Voici le design de l’API :
On va commencer par créer un serveur web très simple à l’aide du cadre de développement Flask.
On crée un répertoire api, un sous-répertoire version_1, puis un sous-répertoire templates ou on sauvegarde les programmes suivants :
server.py
templates/home.html
Le programme HTML est nommé home.html plutôt que index.html comme il est d’usage, car index.html pose problème lorsqu’on importe le module Connexion, ce qu’on fera dans la suite.
On lance une fenêtre Terminal, on se place dans le répertoire projects/api/version_1 et on lance l’application en saisissant successivement :
$ export FLASK_APP = server.py
$ export FLASK_ENV = development
$ flask run
On obtient le résultat suivant en saisissant http://127.0.0.1:5000 dans la barre du navigateur :
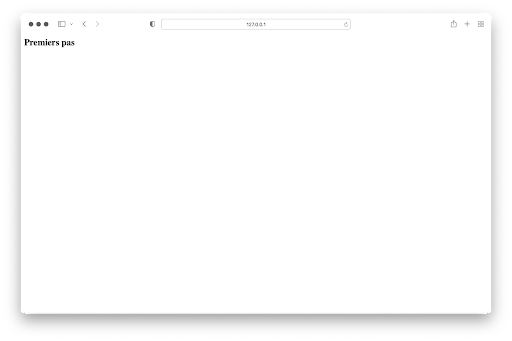
4. Connexion
À présent qu’on a un service Web fonctionnel, on va ajouter un chemin d’accès REST (REST API endpoint). À cet effet, on va installer le module Connexion.
Pour cela, on saisit dans une fenêtre terminal (cela suppose qu’on travaille sous Anaconda) :
$ conda install -c conda-forge connexion
On peut à présent l’importer sous Python.
On crée ensuite un sous-répertoire version_2 dans le répertoire api et on y sauvegarde les programmes suivants :
server.py
swagger.yml
Afin d’utiliser Connexion, on commence par l’importer, puis on crée l’application à l’aide de Connexion plutôt que Flask. L’application Flask est quand même créée de façon sous-jacente, mais avec des fonctionnalités additionnelles.
La création de l’instance de l’application comprend un paramètre specification_dir. Il indique à Connexion où trouver le fichier de configuration, ici le répertoire courant.
La ligne app.add_api (‘swagger.yml’) indique à l’instance de lire le fichier swagger.yml dans le specification_dir et de configurer le système pour Connexion.
Le fichier swagger.yml est un fichier YAML (ou JSON) contenant l’information nécessaire à la configuration du serveur, permettant d’assurer la validation des inputs et des outputs, de fournir les URL de requête et de configurer l’interface utilisateur (UI) Swagger.
Le code précédent définit la requête GET / api/people. Le code est organisé de manière hiérarchique, l’indentation définissant le degré d’appartenance ou portée.
Par exemple, paths définit la racine de toutes les URL de l’API. La valeur /people indentée à la suite définit la racine de toutes les URL /api/people. Le get : indenté à la suite définit une requête GET vers l’URL /api/people, et ainsi de suite pour tout le fichier de configuration.
Dans le fichier swagger.yml, on configure Connexion avec la valeur operationId pour appeler le module people et la fonction read de ce module quand l’API reçoit une requête HTTP du type GET /api/people. Cela signifie qu’un module people.py doit exister et contenir une fonction read( ).
Voici le module people.py :
people.py
Dans le module people.py apparaît d’abord la fonction get_timestamp( ) qui génère une représentation de la date/heure courante sous la forme d’une chaîne de caractères. Elle est utilisée pour modifier les données quand une requête de modification est transmise à l’API.
Ensuite, on définit un dictionnaire PEOPLE qui est une simple base de données de noms, ayant comme clé le nom de famille.
PEOPLE est une variable de module et son état persiste donc entre les appels à l’API.
Dans une application réelle, les données PEOPLE se trouveraient dans une base de données, un fichier ou une ressource Web, c’est-à-dire qu’elles persisteraient indépendamment de l’exécution de l’application.
Vient ensuite la fonction read( ) qui est appelée lorsque le serveur reçoit une requête HTTP GET pour /api/people.
La valeur de retour de cette fonction est convertie au format JSON (comme spécifié par produces : dans le fichier de configuration swagger.yml).
Elle consiste en la liste des personnes triée par ordre alphabétique du nom de famille. À ce stade, on peut exécuter le programme server.py à l’aide de la command :
$ python server.py
ce qui donne le résultat suivant en saisissant comme adresse http://0.0.0.0:8080/api/people dans la barre du navigateur :
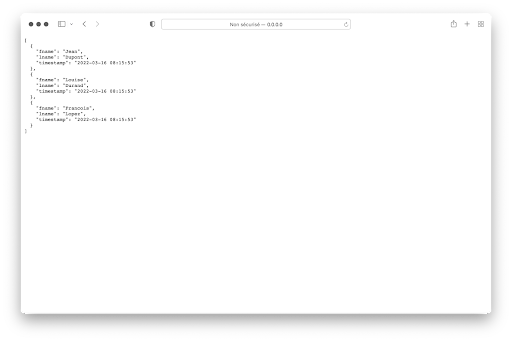
5. Swagger/OpenAPI
On a ainsi construit une API simple autorisant une seule requête. On peut toutefois se poser la question suivante, d’autant plus qu’on a vu comment obtenir le même résultat beaucoup plus simplement avec Flask dans notre premier article :
Qu’apporte la configuration à l’aide du fichier swagger.yml ?
En fait, en plus de l’API une Interface Utilisateur (UI) Swagger (OpenAPI) a été créée par Connexion. Pour y accéder, il suffit de saisir http://localhost:8080/api/ui.
On obtient le résultat suivant :
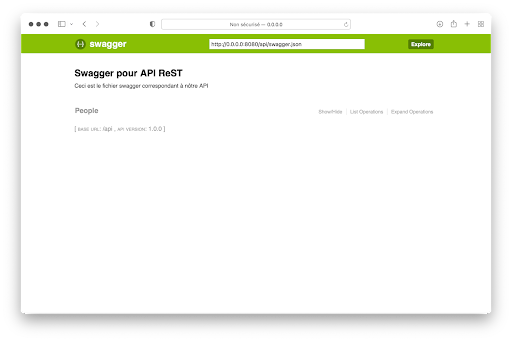
En cliquant sur People, la requête potentielle apparaît :
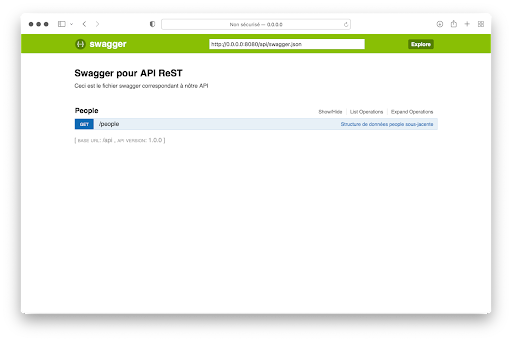
En cliquant sur la requête, les informations supplémentaires suivantes sont affichées par l’interface :
- La structure de la réponse
- Le format de la réponse (content-type)
Le texte renseigné dans swagger.yml à propos de la requête
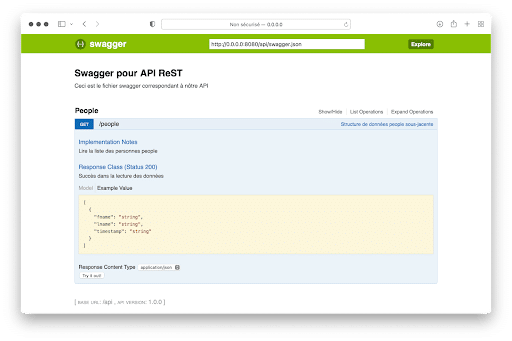
On peut même essayer la requête en cliquant sur le bouton Try It Out ! en bas de l’écran.
L’interface développe encore plus l’affichage et on obtient à la suite :
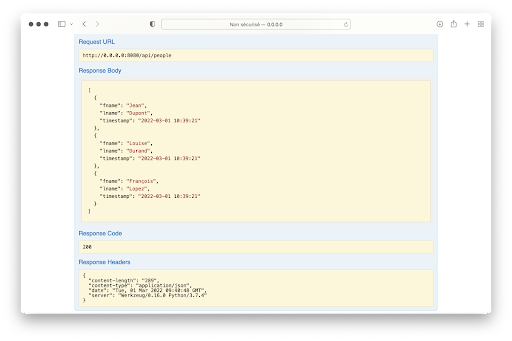
Tout cela est très utile lorsqu’on dispose d’une API complète puisque cela permet de tester et d’expérimenter avec l’API sans écrire de code. En plus d’être pratique pour accéder à la documentation, l’interface Swagger/OpenAPI a l’avantage d’être mise à jour dès que le fichier swagger.yml est mis à jour.
De plus, le fichier swagger.yml fournit une façon méthodique de concevoir l’ensemble des requêtes, ce qui permet d’assurer une conception rigoureuse de l’API. Enfin, cela permet de découpler le code Python de la configuration des requêtes, ce qui peut s’avérer très utile lorsqu’on conçoit des API supportant des applications Web. On en verra un exemple dans la suite.
6. API Complète
Notre objectif était de créer une API offrant un accès CRUD à nos données PEOPLE. À cet effet, on complète le fichier de configuration swagger.yml et le module people.py afin de satisfaire aux spécifications de notre API.
Les fichiers complétés sont accessibles dans le sous-répertoire version_3 sous GitHub : https://github.com/salimlardjane1/projects/tree/version_3
L’exécution de server.py donne alors, pour ce qui est de l’interface Swagger/OpenAPI :
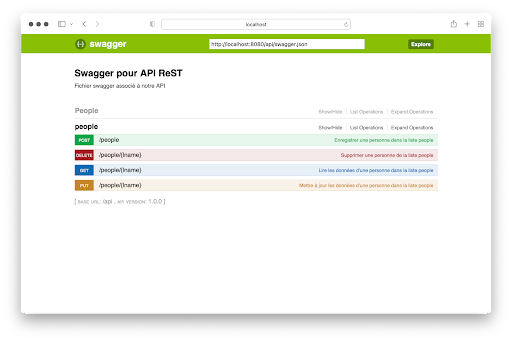
L’interface précédente permet d’accéder à la documentation renseignée dans le fichier swagger.yml et d’interagir avec toutes les URL implémentant les fonctionnalités CRUD de l’API.
7. Application Web
On dispose à présent d’une API REST documentée et avec laquelle on peut interagir à l’aide de Swagger/OpenAPI.
Comment aller plus loin ?
L’étape suivante consiste à créer une application Web illustrant l’utilisation concrète de l’API.
On crée une application Web qui affiche les personnes de la base à l’écran et permet d’ajouter des personnes, de mettre à jour les données des personnes et de supprimer des personnes de la base. Cela sera fait à l’aide de requêtes AJAX émises de JavaScript vers les URL de notre API.
Pour commencer, on doit compléter le fichier home.html, qui contrôle la structure et l’apparence de la page d’accueil de l’application web, de la façon suivante :
Le fichier home.html est disponible sur GitHub :
Dans le sous-répertoire templates du répertoire version_4.
Le programme HTML complète le programme home.html initial en y adjoignant un appel au fichier externe normalize.min.css (https:// necolas.github.io/normalize.css/), qui permet de normaliser l’affichage sur différents navigateurs.
Il fait également appel au fichier jquery-3.3.1.min.js (https:// jquery.com) qui permet de disposer des fonctionnalités jQuery en JavaScript. Celles-ci sont utilisées pour programmer l’interactivité de la page.
Le code HTML définit la partie statique de l’application. Les parties dynamiques seront apportées par JavaScript lors de l’accès à la page et lorsque l’utilisateur interagit avec celle-ci.
Le fichier home.html fait référence à deux fichiers statiques : static/css/home.css et static/js/home.js. Le répertoire nommé static est immédiatement reconnu par l’application Flask et le contenu des répertoires css et js est ainsi accessible à partir du fichier home.html.
Les fichiers home.css et home.js sont disponibles sur GitHub :
On parlera davantage de CSS et de JavaScript dans le prochain article.
Lorsqu’on se place dans le répertoire version_4 et qu’on exécute server.py, on obtient le résultat suivant dans le navigateur :
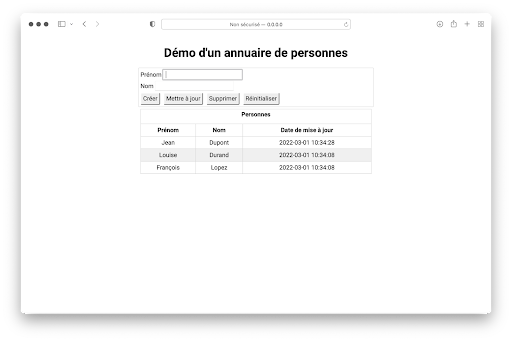
Le bouton Créer permet à l’utilisateur de rajouter une personne au catalogue sur le serveur.
Un double clic sur une ligne du tableau fait apparaître le nom et le prénom dans les champs de saisie.
Pour mettre à jour, l’utilisateur doit modifier le prénom, le nom étant la clef de recherche.
Pour supprimer une personne de l’annuaire, il suffit de cliquer sur Supprimer.
Réinitialiser vide les champs de saisie.
On a ainsi construit une petite application Web fonctionnelle.
On verra plus en détail son fonctionnement dans le prochain article.
8. Références bibliographiques
- Creating Web APIs with Python and Flask, Patrick Smyth, 2022 : https://programminghistorian.org/en/lessons/creating-apis-with-python-and-flask.
- Python REST APIs With Flask, Connexion, and SQLAlchemy, Doug Farrell, 2022 : https://realpython.com/flask-connexion-rest-api/.
- Python REST APIs With Flask, Connexion, and SQLAlchemy, Doug Farrell, 2022 : https://realpython.com/flask-connexion-rest-api-part-2/.
- Flask RESTful documentation, 2020 : https://flask-restful.readthedocs.io/en/latest/index.html.
- Flask Web Development : Developing Web Applications with Python (2ème édition). M. Grinberg. O’Reilly 2018.
- Architectural Styles and the Design of Network-Based Software Architectures. T. Fielding. Thèse, Université de Californie, 2000.









