
La collecte des données est la première étape pour créer un modèle de Machine Learning. Il est donc essentiel de choisir un modèle de base de données qui offre les caractéristiques dont votre application a le plus besoin. Les bases de données relationnelles et NoSQL constituent les deux familles de systèmes les plus utilisées. Leur structure, le stockage des données qu’elles assurent et leur accessibilité diffèrent. Dans cet article nous allons examiner chacune de leur caractéristique spécifique.
Bases de données relationnelles:
Elles sont le plus ancien type de base de données à usage général encore largement utilisé aujourd’hui.
Les bases de données relationnelles organisent les données à l’aide de tableaux.
Les tables sont des structures qui imposent un schéma aux enregistrements qu’elles contiennent.
Chaque colonne d’une table a un nom et un type de données. Chaque ligne représente une donnée dans la table, qui contient des valeurs pour chacune des colonnes.
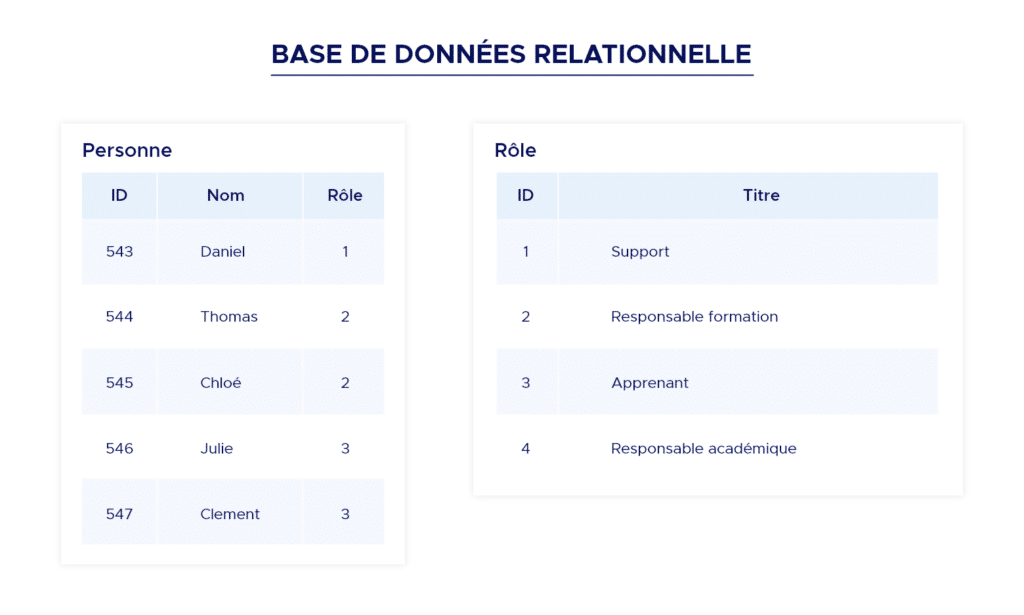
Le langage SQL, a été créé pour accéder aux données stockées dans ce format et afin de garantir les propriétés ACID. Elles sont souvent adaptées à des données régulières et prévisibles. Comme elles fonctionnent à partir d’un schéma, il peut être plus difficile de modifier la structure des données une fois qu’elles sont dans le système.
Dans l’ensemble, les bases de données relationnelles constituent un choix solide pour de nombreuses applications, car les applications génèrent souvent des données bien ordonnées et structurées.
Base de données NoSQL
Les prochains types que nous allons voir font partie de la famille des bases de données NoSQL : des alternatives à haute performance pour les données qui ne correspondent pas au modèle relationnel.
Elles excellent par leur facilité d’utilisation, leur scalabilité, leur résilience et leurs caractéristiques de disponibilité.
Base de données orientée Document
Bon choix pour un développement rapide car vous pouvez modifier les propriétés des donnéesque vous souhaitez enregistrer à tout moment sans modifier les structures ou les données existantes.
Chaque document est autonome et possède son propre système d’organisation. Si vous n’avez pas encore déterminé votre structure de données, ce modèle pourrait être un bon point de départ.
Attention toutefois, car la flexibilité signifie que vous êtes responsable du maintien de la cohérence, ce qui peut être extrêmement difficile.
Base de données orientée Colonne
Utile pour les applications qui exigent de grandes performances pour les opérations en ligne et une grande évolutivité. Comme toutes les données et métadonnées d’une entrée sont accessibles avec un seul identificateur de ligne, aucune jointure coûteuse en termes de calcul n’est nécessaire pour trouver et extraire les informations.
Cependant, elles ne fonctionnent pas bien dans tous les cas de figure. Si vous avez des données hautement relationnelles qui nécessitent des jointures, ce n’est pas le bon modèle à utiliser.

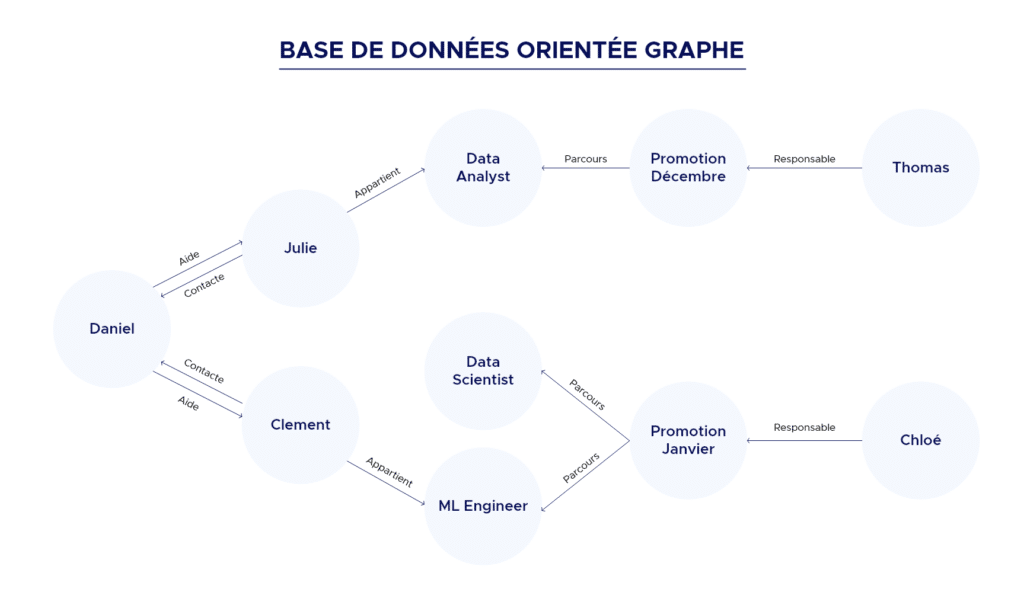
Base de données orientée Graphe
Elles sont particulièrement utiles lorsqu’on travaille avec des données dont les connexions sont très importantes.
Par exemple, la recherche de la connexion entre deux utilisateurs d’un réseau social dans une base de données relationnelle est susceptible de nécessiter de multiples jointures de tables et donc d’être assez gourmande en ressources. Cette même requête serait simple dans une base de données graphique qui établit directement des correspondances entre les connexions.
L’objectif des bases de données graphiques est de rendre le travail sur ce type de données intuitif et puissant.
Choisir sa base de données passe par le choix de sa typologie mais aussi par la compréhension du théorème CAP.
Dans le prochain article nous verrons le théorème CAP et vous serez ainsi en possession de toutes les armes afin de débuter votre projet de Data
Et si votre projet Data commençait par une formation en Data Science élaborée par des experts et certifiée par la Sorbonne ?








