Une Random Forest (ou Forêt d’arbres de décision en français) est une technique de Machine Learning très populaire auprès des Data Scientists et pour cause : elle présente de nombreux avantages comparé aux autres algorithmes de data.
C’est une technique facile à interpréter, stable, qui présente en général de bonnes accuracies et qui peut être utilisée pour des tâches de régression ou de classification. Elle couvre donc une grande partie des problèmes de Machine Learning.
Dans Random Forest il y a d’abord le mot « Forest » (ou forêt en français). On comprend donc que cet algorithme va reposer sur des arbres que l’on appelle arbre de décision ou arbre décisionnel.
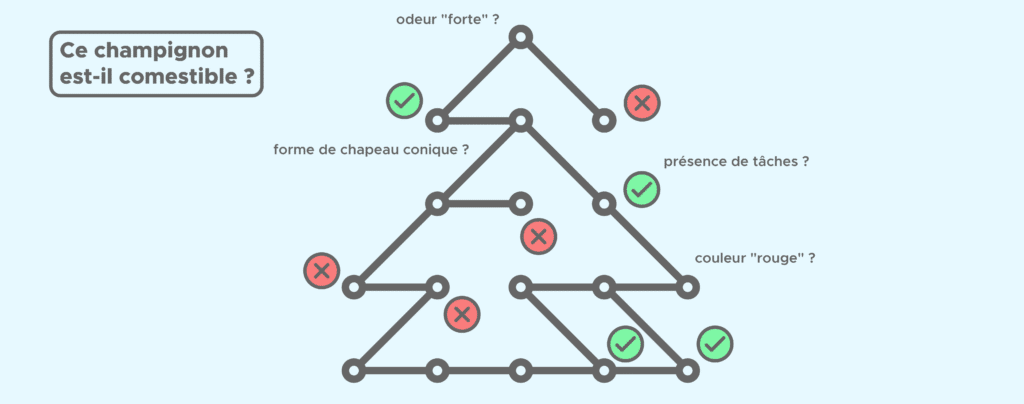
Un exemple d’arbre de décision
Comme son nom l’indique, un arbre de décision aide le Data Scientist à prendre une décision grâce à une série de questions (aussi appelées tests) dont la réponse (oui/non) mènera à la décision finale.
Prenons un exemple de classification binaire : on cherche à savoir si un champignon est comestible en fonction des critères – ou features en anglais – suivants : couleur, taille du champignon, forme du chapeau, odeur, taille de la tige, présence de tâches, etc.


Sur l’arbre, chaque question correspond à un noeud c’est-à-dire à un endroit où une branche se sépare en deux branches. En fonction de la réponse à chaque question, nous allons nous orienter vers telle ou telle branche de l’arbre pour finalement arriver sur une feuille de l’arbre (ou extrémité) qui contiendra la réponse à notre question.
Vous vous demandez peut-être comment on choisit l’ordre des questions à poser : pourquoi commencer par telle ou telle question ?
A chaque nœud, l’algorithme se pose la question de savoir quelle question poser c’est-à-dire si on doit plutôt s’intéresser à l’odeur, la forme du chapeau ou la taille du champignon. Il va donc calculer pour chaque feature le gain d’information que l’on obtiendrait si l’on choisissait cette feature. Nous voulons maximiser le gain d’information c’est pourquoi l’arbre choisit la question et donc la feature qui maximise ce gain.
La forêt comme la combinaison des arbres
Random Forest est ce qu’on appelle une méthode d’ensemble (ou ensemble method en anglais) c’est-à-dire qu’elle « met ensemble » ou combine des résultats pour obtenir un super résultat final.
Mais les résultats de quoi ? Tout simplement des différents arbres de décision qui la composent.
Les Random Forest peuvent être composées de plusieurs dizaines voire centaines d’arbres, le nombre d’arbre est un paramètre que l’on ajuste généralement par validation croisée (ou cross-validation en anglais). Pour faire court, la validation croisée est une technique d’évaluation d’un algorithme de Machine Learning consistant à entrainer et tester le modèle sur des morceaux du dataset de départ.
Chaque arbre est entraîné sur un sous-ensemble du dataset et donne un résultat (oui ou non dans le cas de notre exemple sur les champignons). Les résultats de tous les arbres de décision sont alors combinés pour donner une réponse finale. Chaque arbre « vote » (oui ou non) et la réponse finale est celle qui a eu la majorité de vote.
C’est ce que l’on appelle une méthode de bagging :
- On découpe notre dataset en plusieurs sous-ensembles aléatoirement constitués d’échantillons – d’où le « Random » dans Random Forest.
- On entraine un modèle sur chaque sous-ensemble : il y a autant de modèles que de sous-ensembles.
- On combine tous les résultats des modèles (avec un système de vote par exemple) ce qui nous donne un résultat final.
De cette manière on construit un modèle robuste à partir de plusieurs modèles qui sont pas forcément aussi robustes.
En bref, cet algorithme est très populaire pour sa capacité à combiner les résultats de ses arbres pour obtenir un résultat final plus fiable. Son efficacité lui a permis d’être utilisé dans de nombreux domaines comme par exemple le marketing téléphonique pour prédire le comportement de clients ou encore la finance pour la gestion de risques.
Vous souhaitez démarrer une formation en Machine Learning ? Découvrez vite nos cursus Data Analyst, Data Scientist et Data Engineer !






