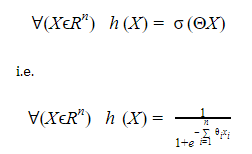Si vous vous intéressez un tant soit peu au Machine Learning et aux problèmes de classification, vous avez déjà dû avoir affaire au modèle de régression logistique. Et pour cause ! Il s’agit d’un des modèles de Machine Learning les plus simples et interprétables qui existe, prend des données à la fois continues ou discrètes, et les résultats obtenus avec sont loin d’être risibles.
Mais que se cache-t’il derrière cette méthode miracle ? Et surtout comment l’utiliser sur Python ? La réponse dans cet article
Qu'est-ce que la régression logistique ?
La régression logistique est un modèle statistique permettant d’étudier les relations entre un ensemble de variables qualitatives Xi et une variable qualitative Y. Il s’agit d’un modèle linéaire généralisé utilisant une fonction logistique comme fonction de lien.
Un modèle de régression logistique permet aussi de prédire la probabilité qu’un événement arrive (valeur de 1) ou non (valeur de 0) à partir de l’optimisation des coefficients de régression. Ce résultat varie toujours entre 0 et 1. Lorsque la valeur prédite est supérieure à un seuil, l’événement est susceptible de se produire, alors que lorsque cette valeur est inférieure au même seuil, il ne l’est pas.
Mathématiquement, comment ça se traduit / ça s'écrit ?
Considérons une entrée X= x1x2x3… xn, la régression logistique a pour objectif de trouver une fonction h telle que nous puissions calculer :
y= {1 si hX≥ seuil , 0 si hX< seuil}
On comprend donc qu’on attend de notre fonction h qu’elle soit une probabilité comprise entre 0 et 1, paramétrée par =123n à optimiser, et que le seuil que nous définissons correspond à notre critère de classification, généralement il est pris comme valant 0.5.
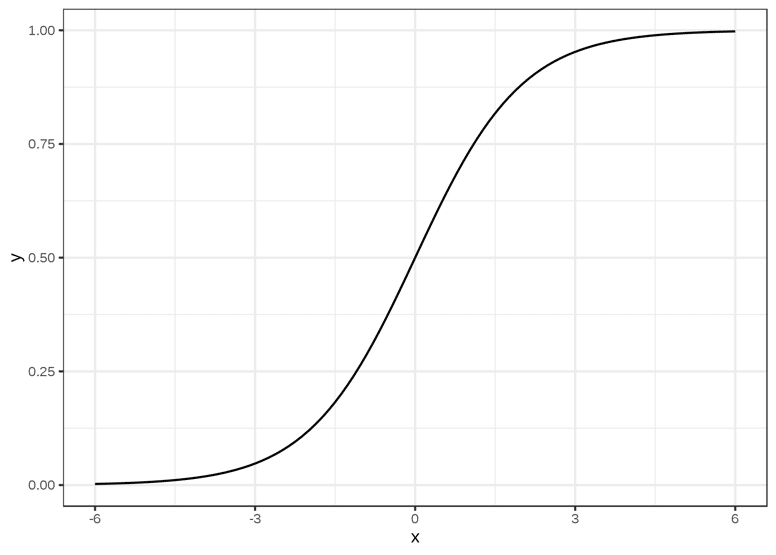
La fonction qui remplit le mieux ces conditions est la fonction sigmoïde, définie sur R à valeurs dans [0,1]. Elle s’écrit de la manière suivante :
Graphiquement, celle-ci correspond à une courbe en forme de S qui a pour limites 0 et 1 lorsque x tend respectivement vers -∞ et +∞ passant par y = 0.5 en x = 0.
Sigmoid function
Et notre classification dans tout ça ?
La fonction h qui définit la régression logistique s’écrit alors :
Tout le problème de classification par régression logistique apparaît alors comme un simple problème d’optimisation où, à partir de données, nous essayons d’obtenir le meilleur jeu de paramètre Θpermettant à notre courbe sigmoïde de coller au mieux aux données. C’est dans cette étape qu’intervient notre apprentissage automatique.
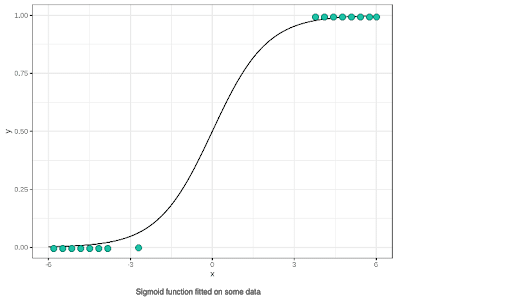
Une fois cette étape effectuée, voici un aperçu du résultat qu’on peut obtenir:
Il ne reste plus, à partir du seuil défini, qu’à classer les points en fonction de leurs positions par rapport à la régression et notre classification est faite !
La régression logistique en pratique
En Python c’est assez simple, on se sert de la classe LogisticRegression du module sklearn.linear_model comme un classificateur normal et que l’on entraîne sur des données déjà nettoyées et séparées en ensembles d’entraînement et de test puis le tour est joué !
Niveau code, rien de plus basique :
Pour des cas d’applications plus poussés, pourquoi ne pas suivre le cours dispensé par l’équipe Datascientest ?