Aunque el aprendizaje automático permite a las organizaciones ser más eficientes y tomar mejores decisiones, los expertos en Data Science siguen necesitando dominar los distintos algoritmos de inteligencia artificial. Al fin y al cabo, hay docenas de ellos. Y cada uno sirve para un propósito concreto. En este artículo, echamos un vistazo a los distintos algoritmos de clasificación.
¿Qué es un algoritmo de clasificación?
Definición
En primer lugar, hay que ver qué es un algoritmo: un conjunto de operaciones seguidas en un orden preciso para resolver un problema o aportar nuevas soluciones. Como el aprendizaje de un sistema de inteligencia artificial.
Esta es precisamente la función de los algoritmos de clasificación utilizados en Machine Learning. Permiten al software aprender de forma independiente a partir de varios conjuntos de datos.
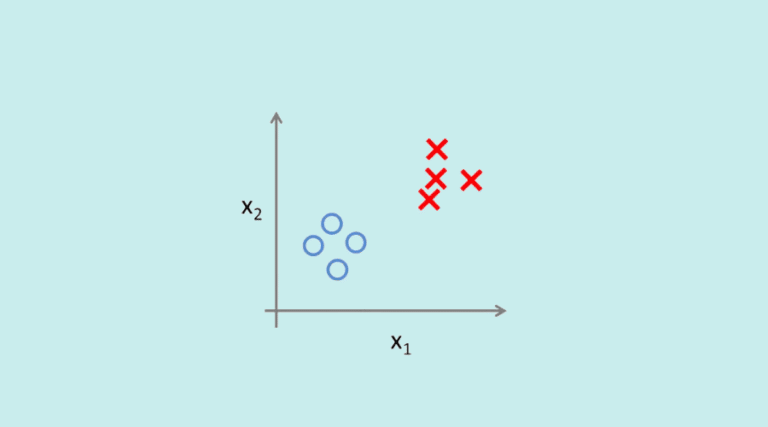
Se trata de clasificar los distintos elementos de un conjunto de datos en varias categorías. Estas agrupan los datos en función de su similitud. Como los conjuntos de datos tienen características comunes, es más fácil predecir su comportamiento.
Por ejemplo, para una tienda de comercio electrónico, los usuarios que vuelven al sitio varias veces tienen más probabilidades de comprar que los que no lo vuelven a visitar nunca. El algoritmo de clasificación segmenta a los usuarios en distintas categorías para que la empresa pueda adaptar sus comunicaciones.
Estos diferentes modelos de aprendizaje pueden utilizarse para el análisis de datos y el análisis predictivo.
Clasificación supervisada
El algoritmo de clasificación es uno de los métodos de aprendizaje supervisado. Es decir, las predicciones se realizan a partir de datos históricos.
Esto contrasta con el aprendizaje no supervisado, en el que no hay clases predefinidas. Por tanto, las categorías deben formarse a partir de atributos comunes y, a continuación, se realizan las predicciones.
Dentro de estos algoritmos supervisados, hay que distinguir entre algoritmos de aprendizaje de clasificación y de predicción (o regresión). En este último caso, el objetivo es predecir nuevos datos en función de un valor real específico, en lugar de una categoría.
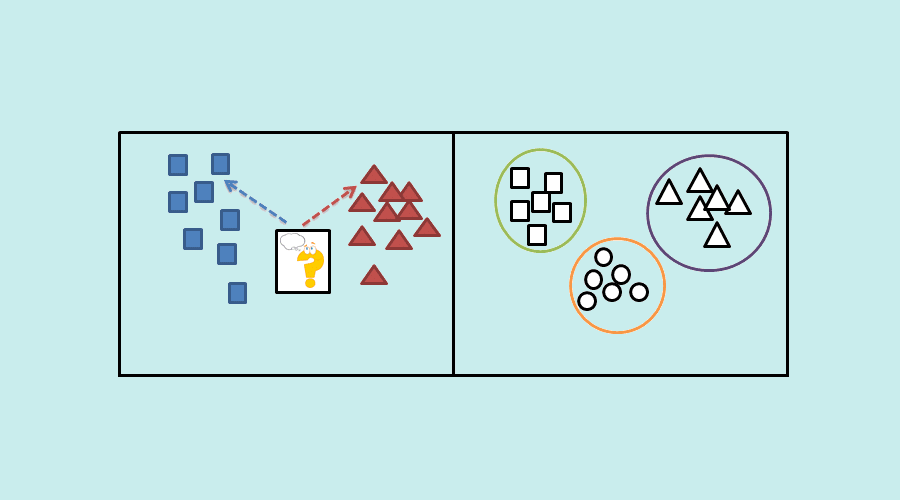
¿Cuáles son los principales modelos de clasificación?
Existen muchos algoritmos de aprendizaje supervisado basados en la clasificación. Hemos reunido los principales en esta lista no exhaustiva.
La máquina de vectores de soporte (SVM)
Este algoritmo se considera un clasificador lineal. Su función es separar conjuntos de datos a lo largo de líneas (denominadas hiperplanos). Para ello, el algoritmo debe maximizar las distancias entre la línea de separación y las distintas muestras situadas a ambos lados. Las muestras más cercanas a la línea se denominan vectores de apoyo.
La idea es encontrar el hiperplano óptimo, uno que distinga perfectamente las dos clases para minimizar los errores de clasificación. Esto permite separar claramente los datos para poder identificar fácilmente las clases simples. Por ejemplo, ciudades grandes y pequeñas. Cuando se trata de datos más complejos, como el material genético de un individuo, no es tan fácil identificar las distintas categorías. Por tanto, este algoritmo no será el más pertinente.
La SVM se utiliza a menudo en el sector financiero para comparar el rendimiento actual y futuro, el rendimiento de las inversiones, etc.
Nota: Aunque este algoritmo se utiliza principalmente para la clasificación de datos, también se puede utilizar para la regresión.
Árboles de decisión
El árbol de decisión es un algoritmo que clasifica diferentes datos en forma de ramas. Parte de una raíz en la que cada dato toma una dirección determinada en función de su comportamiento. Lo que permite predecir las variables de respuesta.
Como en los árboles, las intersecciones se denominan nodos y sus extremos, hojas. Los nodos representan las reglas de separación de los datos en diferentes categorías y las hojas son la información propiamente dicha.
Aquí tienes un ejemplo muy sencillo:
| Más de 100.000 habitantes | Ciudad de Île-de-France | |
|---|---|---|
| París | Sí | Sí |
| Courbevoie | No | Sí |
| Marsella | Sí | No |
Este algoritmo de clasificación es muy fácil de entender, incluso para los no expertos en datos. Eso sí, cuando representa grandes volúmenes de datos, se vuelve más difícil de entender.
Puede utilizarse para anticipar cambios en los tipos de interés de los préstamos, la reacción del mercado a los cambios, etc.
Clasificación K-means
Este algoritmo de clasificación ordena los datos en diferentes grupos en función de sus características.
Para ello, establece una media de referencia entre un conjunto de datos, que luego puede utilizarse para definir un perfil típico.
La ventaja del algoritmo K-means es su precisión. Incluso cuando se procesan rápidamente grandes volúmenes de datos.
La eficacia de K-means permite utilizarlo en muchas aplicaciones: los motores de búsqueda para ofrecer resultados que respondan a las expectativas de los usuarios, las empresas para anticipar el comportamiento de posibles clientes o internautas, los responsables informáticos para analizar el rendimiento de sistemas y redes, etc.
Clasificador bayesiano ingenuo
Este algoritmo utiliza el teorema de Bayes y las probabilidades condicionales.
Se basa en conjuntos de datos etiquetados y los asocia a otros datos no etiquetados para clasificarlos.
El clasificador bayesiano ingenuo se utiliza principalmente en el procesamiento del lenguaje natural. En otras palabras, es lo que facilita que las máquinas entiendan el lenguaje humano.
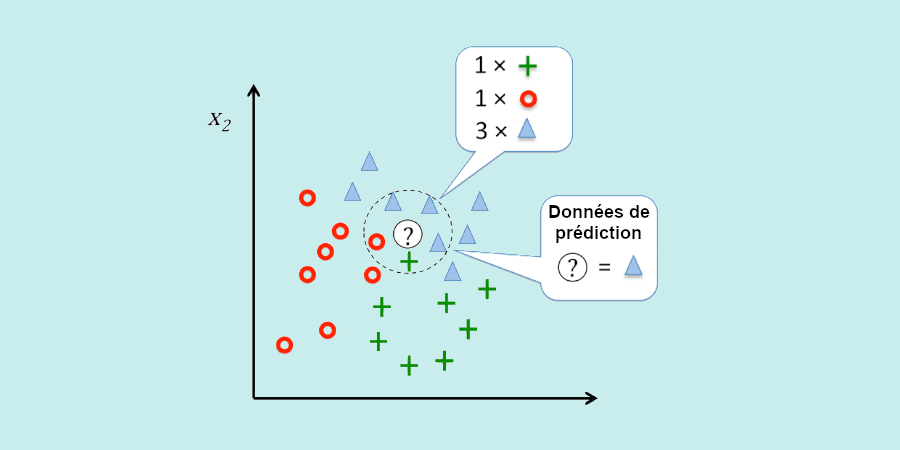
KNN (vecinos más cercanos)
K-nearest neighbours (o algoritmo de vecinos más cercanos) puede utilizarse tanto como algoritmo de regresión como de clasificación. Sin embargo, suele utilizarse en este último caso.
La idea es clasificar las variables de un conjunto de datos analizando las similitudes entre ellas. Para ello, KNN utiliza un gráfico y calcula la distancia entre los distintos puntos. Los más cercanos se registran en la misma categoría.
Regresión lineal
Es uno de los algoritmos de clasificación más utilizados. La idea es establecer correlaciones sencillas entre las entradas y las salidas. Esto explica cómo puede afectar un cambio en una variable a otra.
Es la simplicidad de este modelo lo que hace que sea tan popular entre los Data Scientists. Requiere muy pocos parámetros, es fácil de representar gráficamente y de explicar a los responsables de la toma de decisiones.
Como tal, a menudo se utiliza en el ámbito comercial para prever el número de ventas o, de forma más general, para anticipar riesgos.
Nota: A diferencia de la regresión logística, que predice la categoría de la variable dependiente en función de la variable independiente, la regresión lineal se ocupa de las variables independientes.
Perceptrón
Es uno de los algoritmos más sencillos y, sobre todo, uno de los más antiguos, ya que fue inventado en 1957 por Frank Rosenblatt.
Más concretamente, se trata de un algoritmo de clasificación binaria. Compara la suma de varias señales de entrada. Si la suma supera o no un determinado umbral, el Perceptrón concluye con un resultado basado en la regla definida anteriormente. Esta regla se denomina Perceptron Learning Rule y permite que la red neuronal aprenda automáticamente.
Este algoritmo es muy útil para detectar tendencias en los datos de entrada.
Además de estos diferentes algoritmos de clasificación, existen otros que permiten clasificar datos.
¿Cómo puedo informarme sobre los algoritmos de Machine Learning?
Esenciales para el Machine Learning, los algoritmos de clasificación son herramientas que dominan los Data Scientists y Data Analysts. Para entenderlos, sin embargo, necesitas una formación especializada en Data. Este es precisamente el caso de nuestros cursos en DataScientest.
