Snowflake es un almacén de datos basado en la nube. Descubre todo lo que necesitas saber sobre esta plataforma de Ciencia de Datos cada vez más popular, y cómo aprender a utilizarla con un curso de formación de Snowflake.
En la era del Big Data, los Data Warehouses son cada vez más populares. Estas bases de datos SQL o NoSQL altamente paralelas están especialmente diseñadas para el análisis de datos. Permiten importar y analizar datos procedentes de múltiples fuentes. La idea de Snowflake es ofrecer un Data Warehouse directamente en la nube.
¿Qué es Snowflake?
Snowflake es un Data Warehouse diseñado íntegramente y de forma nativa para la nube. Está disponible en Amazon Web Services y Microsoft Azure, y es una base de datos relacional y columnar con ejecución vectorizada. En otras palabras, puede gestionar las tareas de análisis de datos más exigentes.
Su arquitectura separa la computación del almacenamiento, por lo que puede escalarse en cualquier momento, incluso cuando se están ejecutando consultas. Los usuarios solo pagan por la potencia de cálculo que utilizan. Gracias a su tecnología de optimización adaptativa, Snowflake ofrece automáticamente el mejor rendimiento posible para cada consulta. Ya no hace falta gestionar manualmente los parámetros de configuración.
Además, su arquitectura multiclúster de datos compartidos, permite una concurrencia ilimitada. Esto significa que varios clústeres de computación pueden operar simultáneamente sobre los mismos datos sin que disminuya el rendimiento. Además, la funcionalidad de data warehouse virtual multiclúster adapta automáticamente el rendimiento en función de las necesidades de concurrencia.
Arquitectura Snowflake: ¿cómo funciona?
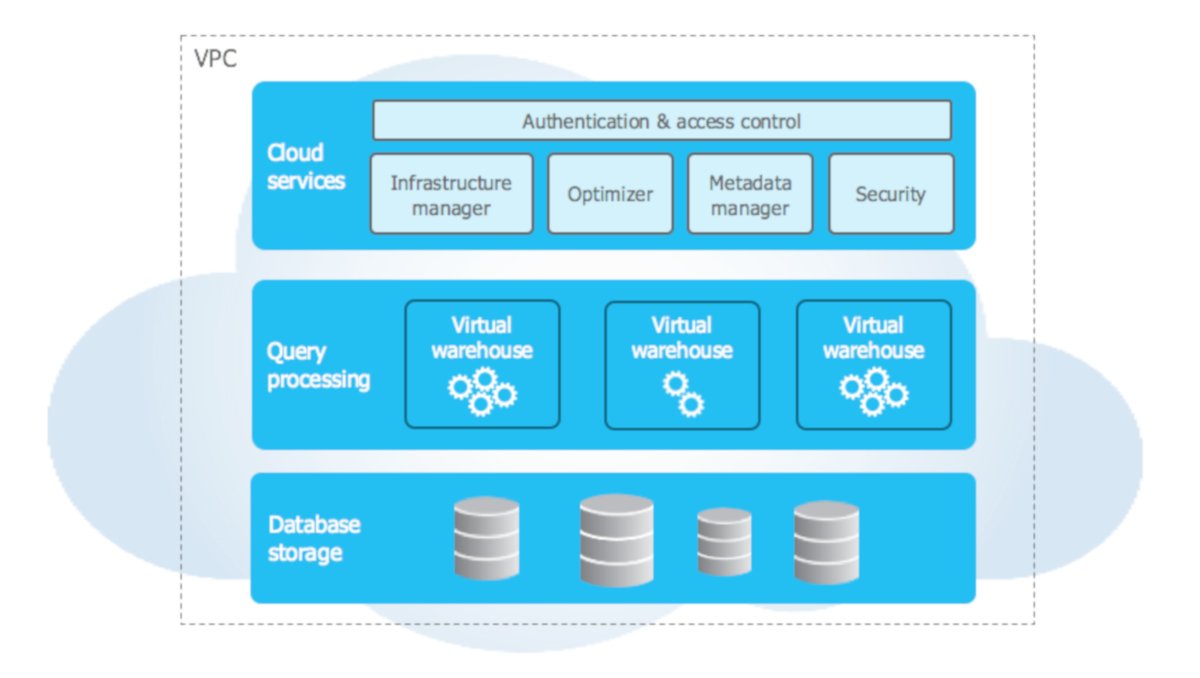
La arquitectura Snowflake se divide en instancias informáticas virtuales para la computación y un servicio de almacenamiento para guardar los datos persistentes.
El repositorio central de datos es accesible desde todos los nodos de cálculo del Data Warehouse. Además, el procesamiento de los datos se lleva a cabo mediante clústeres de computación masivamente paralelos. Cada nodo del clúster almacena localmente una parte del conjunto de datos.
Cuando los datos se cargan en Snowflake, se reorganizan en su formato columnar comprimido. Se puede acceder a los datos mediante consultas SQL.
Se trata de una plataforma 100 % en la nube, por lo que no es posible ejecutarla en una infraestructura en nube privada local o alojada. Una de las ventajas es que no requiere instalación ni configuración. El mantenimiento y la configuración corren a cargo de Snowflake.
Es posible conectarse a Snowflake a través de su interfaz web, la CLI de SnowSQL, controladores ODBC y JDBC para aplicaciones como Tableau, conectores nativos para lenguajes de programación o conectores de terceros para herramientas BI y ETL.
¿Cuáles son las funcionalidades de Snowflake?
El Data Warehouse Cloud de Snowflake es compatible con la mayoría de los DDL y DML definidos en SQL:1999 y las extensiones analíticas de SQL:2003. En términos de conectividad, existen conectores y controladores para Python Spark, Node.js, Go, .Net, JDBC, ODBC y la extensión de código abierto dplyr-snowflakedb.
Los Warehouses virtuales pueden controlarse desde la interfaz gráfica de usuario o desde líneas de comandos. Se pueden crear, redimensionar, suspender o eliminar. El redimensionamiento puede hacerse mientras se ejecuta una consulta, sin tiempo de inactividad. Esto es muy práctico para acelerar una consulta.
La plataforma es compatible con una gran variedad de formatos de datos y archivos. Es posible cargar archivos comprimidos o formatos como JSON, Avro, ORC, Parquet y XML. También se admiten fuentes de datos S3 y archivos locales. Los datos pueden compartirse de forma segura con otras cuentas de Snowflake.
Las funcionalidades de seguridad varían en función de la edición. La edición estándar ofrece cifrado automático de todos los datos, autenticación multifactor e inicio de sesión único.
La edición Enterprise añade el recifrado periódico de los datos cifrados. Por último, la edición Enterprise for Sensitive Data añade compatibilidad con HIPAA y PCI DSS. También es posible elegir dónde se almacenan los datos, lo que facilita el cumplimiento del RGPD.
¿Cuáles son las ventajas de Snowflake?
En el pasado, las empresas almacenaban los datos en local. Los ingenieros y analistas de datos explotaban software de código abierto como Apache Hadoop para el almacenamiento y análisis de datos.
Sin embargo, son escasos los Data Engineers capaces de desarrollar y mantener un sistema de este tipo. El almacén de datos SaaS (software como servicio) de Snowflake resuelve esta carencia.
Los usuarios no tienen que preocuparse por el hardware físico o virtual y no necesitan instalar ningún software. Las actualizaciones y el mantenimiento corren a cargo de los equipos de Snowflake.
Además, esta solución es más rápida, fácil de usar y flexible que los Data Warehouses tradicionales. Además, esta plataforma no se basa en una plataforma de software existente, como Hadoop.
Se basa en un motor de base de datos SQL completamente nuevo, creado por Snowflake con una arquitectura diseñada para la nube. Esto significa que cualquier ingeniero de software con conocimientos de SQL puede entender y utilizar Snowflake.
¿Quiénes son los competidores de Snowflake?
Los principales competidores de Snowflake son Amazon Redshift, Google BigQuery y Microsoft Azure Synapse Analytics. Estas son las ofertas de Data Warehouses de los tres principales proveedores de Cloud.
Otros rivales son Teradata, Oracle Exadata, MarkLogic y SAP BW/4HANA. Estas soluciones pueden instalarse tanto en la nube, como en local.
¿Cómo puedo aprender a utilizarlo?
Snowflake ofrece muchas ventajas, pero su uso puede resultar complejo. Teniendo esto en cuenta, la empresa ofrece una serie de tutoriales y vídeos para ayudarte a dominar la plataforma. Algunos son generales y están dirigidos a principiantes, mientras que otros permiten descubrir funciones específicas con más detalle.
También puede optar por hacer un curso de Snowflake. DataScientest te ofrece la oportunidad de aprender a dominar Cloud Data Warehouse a través de nuestro curso de Machine Learning Engineer y nuestro curso de Data Engineer.
¿Qué diferencia a Snowflake de sus competidores?
Hubo un tiempo en que el coste de contratar un servicio de televisión por cable implicaba que la infraestructura y los contenidos estaban incluidos en un solo paquete. Hoy, estos elementos están separados y los usuarios tienen más control sobre lo que utilizan y cómo lo pagan.
La arquitectura de Snowflake permite una flexibilidad similar con Big Data. Esta herramienta de cloud computing desacopla las funciones de almacenamiento y computación, lo que significa que las empresas con grandes demandas de almacenamiento pero menos necesidad de ciclos de CPU, o viceversa, no tienen que pagar por un paquete integrado que les obligue a pagar por ambos. Este punto de diferenciación es uno de los factores que han permitido a sus cofundadores (Marcin Zukowski, Benoît Dageville y Thierry Cruanes) ahorrar millones de dólares a varias organizaciones, al tiempo que han revalorizado su start-up en varias decenas de miles de millones de dólares en la actualidad, desde que la primera recaudación de fondos en febrero de 2020.
Los usuarios pueden aumentar o reducir su capacidad según sus necesidades y solo pagan a Snowflake por la carga de trabajo que necesitan. El almacenamiento se factura en terabytes almacenados al mes. La computación se factura por segundos. De hecho, la arquitectura Snowflake se compone de tres capas, cada una de las cuales es escalable de forma independiente: almacenamiento, computación y servicios.
Capa de almacenamiento de datos
La capa de almacenamiento de datos contiene todos los datos cargados en Snowflake, incluidos los datos estructurados y semiestructurados. Snowflake ofrece una gestión automática de las tareas de almacenamiento, desde la organización de los datos hasta su compresión y estructuración. Además, el funcionamiento de esta capa de almacenamiento de datos es totalmente independiente del de la capa de cálculo.
Capa informática
La capa de computación está formada por almacenes virtuales que ejecutan las tareas de procesamiento de datos necesarias para las consultas. Cada almacén virtual (o clúster) puede acceder a todos los datos de la capa de almacenamiento y operar de forma independiente, de modo que los almacenes no comparten ni compiten por los recursos informáticos. Esto permite un escalado automático sin interrupciones, lo que significa que los recursos informáticos pueden cambiar o no durante la ejecución de las consultas y, por tanto, no es necesario redistribuir o reequilibrar los datos en la capa de almacenamiento de datos.
Capa de servicios cloud
La capa de servicios en la nube utiliza ANSI SQL y coordina todo el sistema. Elimina la necesidad de gestionar y ajustar manualmente el almacén de datos. Los servicios de esta capa incluyen autenticación, gestión de infraestructuras y metadatos, análisis y optimización de consultas y control de acceso.
Ahora ya sabes todo lo que hay que saber sobre Snowflake. Consulta nuestro dosier completo sobre Docker, otra herramienta clave de Big Data, y nuestro dosier sobre Machine Learning.
