
L’algorithme des K plus proches voisins ou K-nearest neighbors (kNN) est un algorithme de Machine Learning qui appartient à la classe des algorithmes d’apprentissage supervisé simple et facile à mettre en œuvre qui peut être utilisé pour résoudre les problèmes de classification et de régression. Dans cet article, nous allons revenir sur la définition de cet algorithme, son fonctionnement ainsi qu’une application directe en programmation.
KNN : Définition
Avant de nous concentrer sur l’algorithme KNN, il est nécessaire de reprendre les bases. Qu’est-ce qu’un algorithme d’apprentissage supervisé?
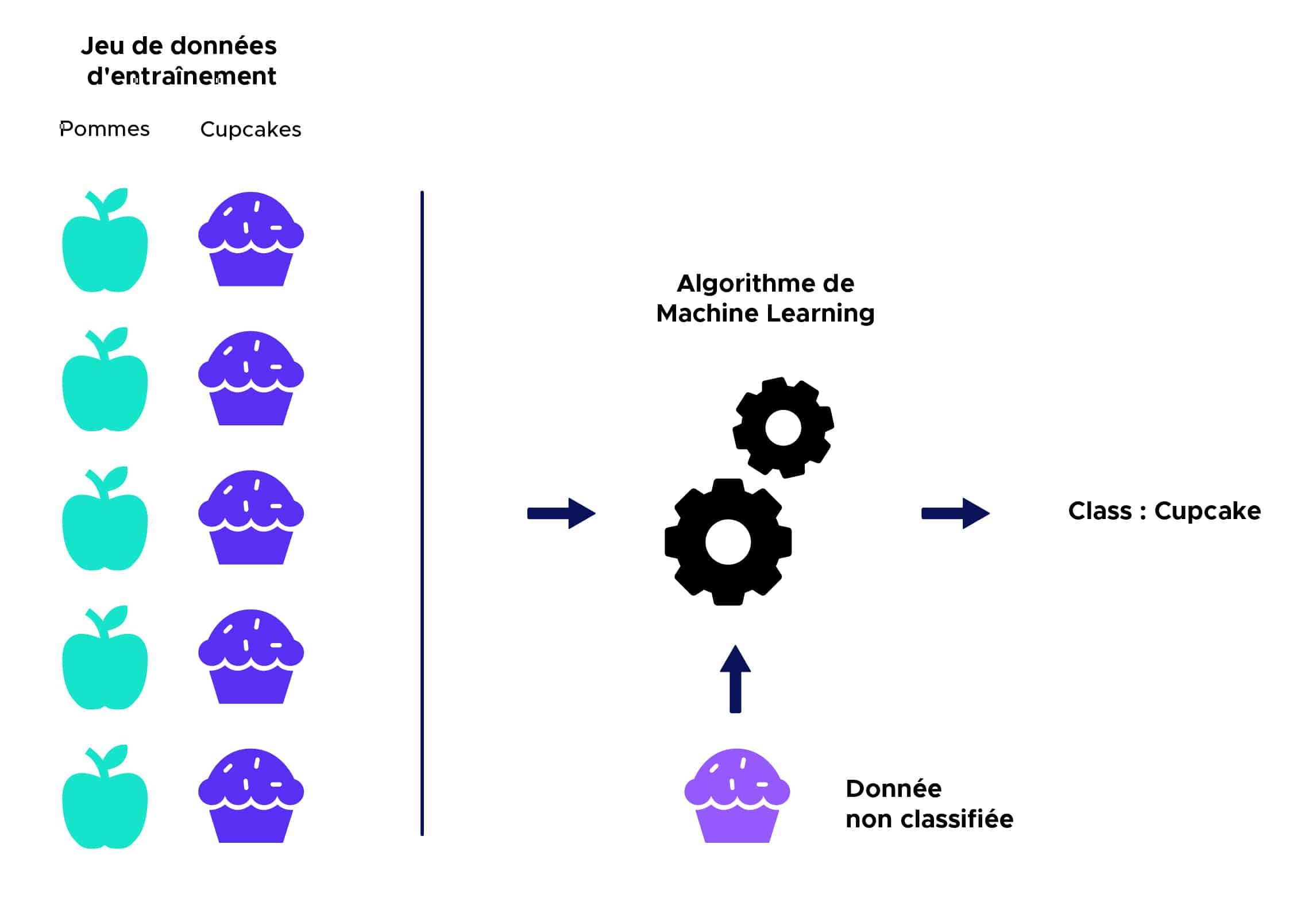
En apprentissage supervisé, un algorithme reçoit un ensemble de données qui est étiqueté avec des valeurs de sorties correspondantes sur lequel il va pouvoir s’entraîner et définir un modèle de prédiction. Cet algorithme pourra par la suite être utilisé sur de nouvelles données afin de prédire leurs valeurs de sorties correspondantes.
Voici une illustration simplifiée :
L’intuition derrière l’algorithme des K plus proches voisins est l’une des plus simples de tous les algorithmes de Machine Learning supervisé :
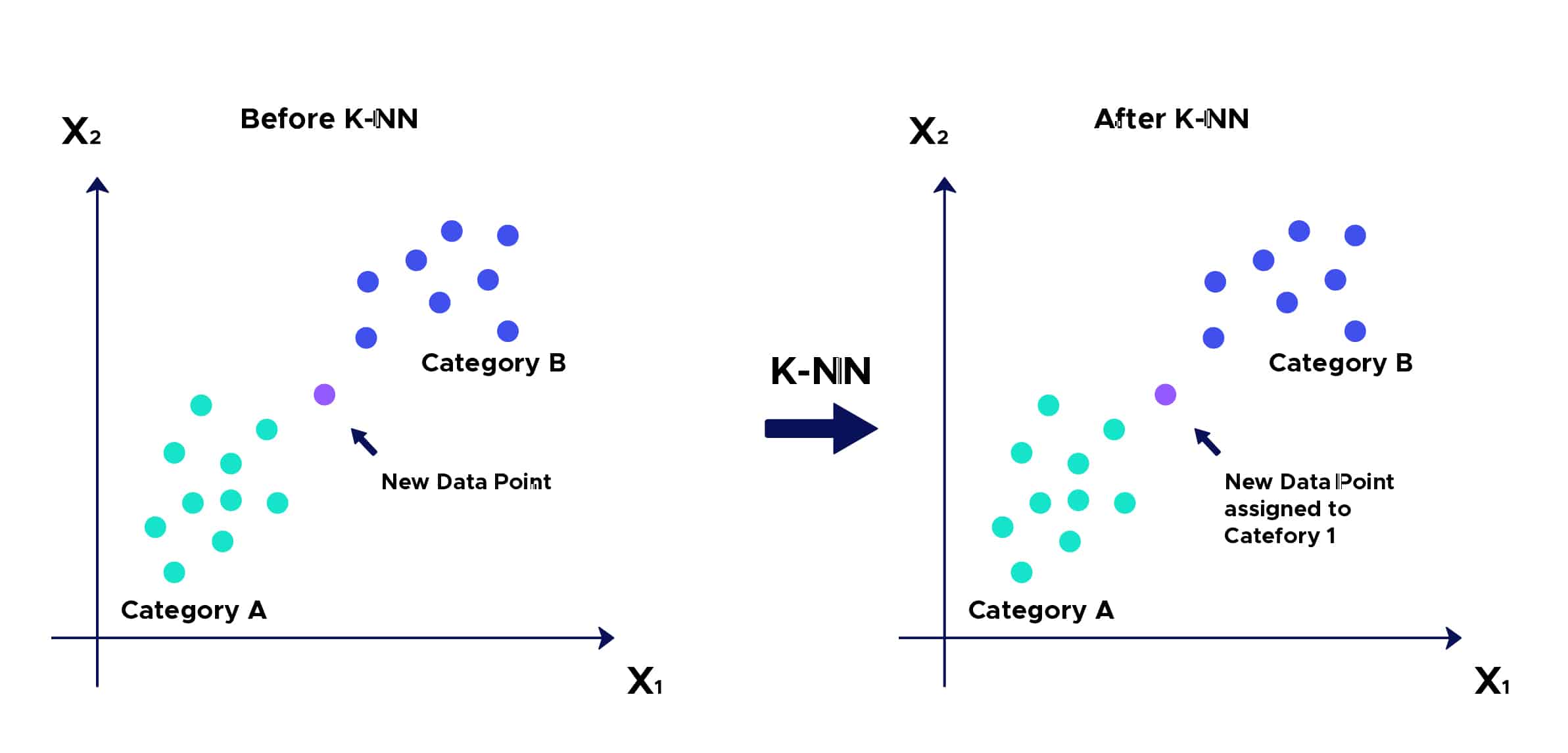
- Étape 1 : Sélectionnez le nombre K de voisins
- Étape 2 : Calculez la distance
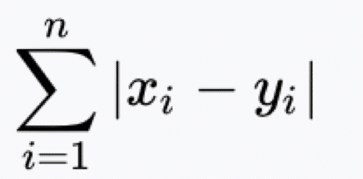
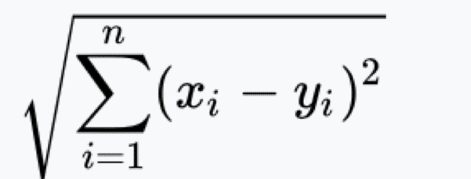
Du point non classifié aux autres points.
- Étape 3 : Prenez les K voisins les plus proches selon la distance calculée.
- Étape 4 : Parmi ces K voisins, comptez le nombre de points appartenant à chaque catégorie.
- Étape 5 : Attribuez le nouveau point à la catégorie la plus présente parmis ces K voisins.
- Étape 6 : Notre modèle est prêt :
KNN : Exemple d’utilisation
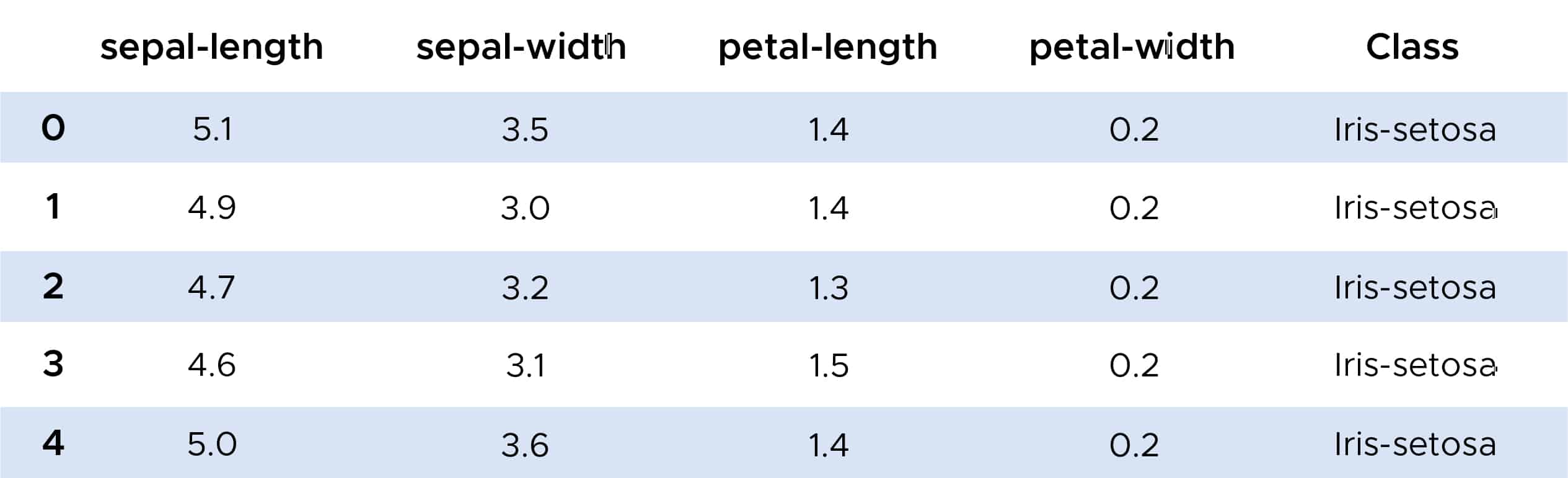
Nous pouvons à présent nous intéresser à un exemple d’utilisation de l’algorithme des K plus proches voisins. Grâce à la librairie Scikit-Learn, nous pouvons importer la fonction KKNeighborsClassifier que nous utiliserons sur le jeu de donnée IRIS.
Grâce à l’algorithme KNN, nous obtenons un excellent taux de bonne classification des plantes proches des 100%. On peut également s’intéresser à un moyen de choisir le K pour lequel la classification sera la meilleure. Une façon de le trouver consiste à tracer le graphique de la valeur K et le taux d’erreur correspondant pour l’ensemble de données :
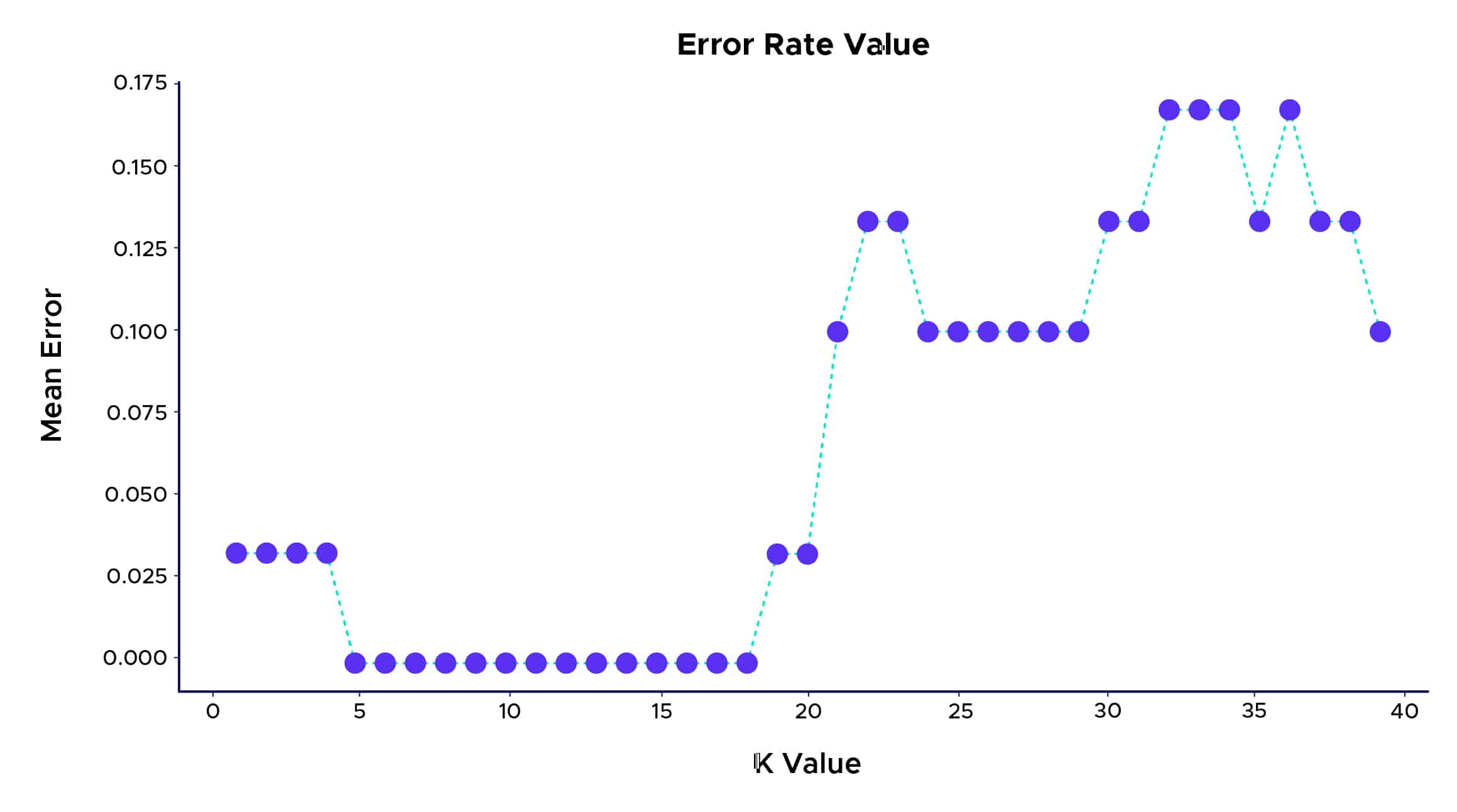
Ainsi, nous pouvons voir que le meilleur taux de prédiction est obtenu pour un K entre 5 et 18. Au-dessus de cette valeur, on peut observer un phénomène nommé « Overfitting » ou Sur apprentissage en Français qui se produit lorsque les données d’apprentissage utilisées pour construire un modèle expliquent très voire « trop » bien les données mais ne parviennent pas à faire des prédictions utiles pour de nouvelles données.
Quelques applications :
- Il peut être utilisé dans des technologies comme l’OCR (Optical Character Recognizer), qui tente de détecter l’écriture manuscrite, les images et même les vidéos.
- Il peut être utilisé dans le domaine des notations de crédit. Il essaie de faire correspondre les caractéristiques d’un individu avec le groupe de personnes existantes afin de lui attribuer la cote de crédit. Il se verra attribuer la même note que celle accordée aux personnes correspondant à ses caractéristiques.
- Il est utilisé pour prédire si la banque doit accorder un prêt à un particulier. Il tentera d’évaluer si l’individu donné correspond aux critères des personnes qui avaient précédemment fait défaut ou ne fera pas défaut à son prêt.
Avantages :
- L’algorithme est simple et facile à mettre en œuvre.
Il n’est pas nécessaire de créer un modèle, de régler plusieurs paramètres ou de formuler des hypothèses supplémentaires. - L’algorithme est polyvalent. Il peut être utilisé pour la classification ou la régression.
Inconvénients :
- L’algorithme devient beaucoup plus lent à mesure que le nombre d’observation et de variables indépendantes augmente.
Étant l’un des algorithmes les plus simples de Machine Learning, il est hautement implémenté pour développer des systèmes basés sur l’apprentissage, intuitifs et intelligents qui pourraient effectuer et prendre de petites décisions tout seuls.
Cela rend les choses encore plus pratiques pour l’apprentissage et le développement et aide presque tous les types d’industries qui pourraient utiliser des systèmes, des solutions ou des services intelligents.
Il existe pleins d’autres algorithmes de Clustering supervisé ou non Supervisé qui seront plus ou moins approprié selon la situation comme celui des K-means, du CAH (La classification ascendante hiérarchique ), DBSCAN (density-based spatial clustering of applications with noise)… que vous pouvez retrouver sur notre blog.







